Observability
Grafana monitoring dashboard
The API exposes Prometheus-compatible metrics at /metrics, scraped automatically by Prometheus via Kubernetes annotations. A custom Grafana dashboard visualizes prediction throughput, latency, and errors in real time — the same observability stack used in production ML systems.
Counter
prediction_requests_total
Tracks every prediction, labeled by success or error status for SLA monitoring.
Histogram
prediction_latency_seconds
Captures latency distribution across configurable buckets for percentile analysis (p50, p95, p99).
Counter
prediction_errors_total
Categorizes failures by type — validation errors, server errors, and unexpected exceptions.
Grafana — Used Car Price API Dashboard
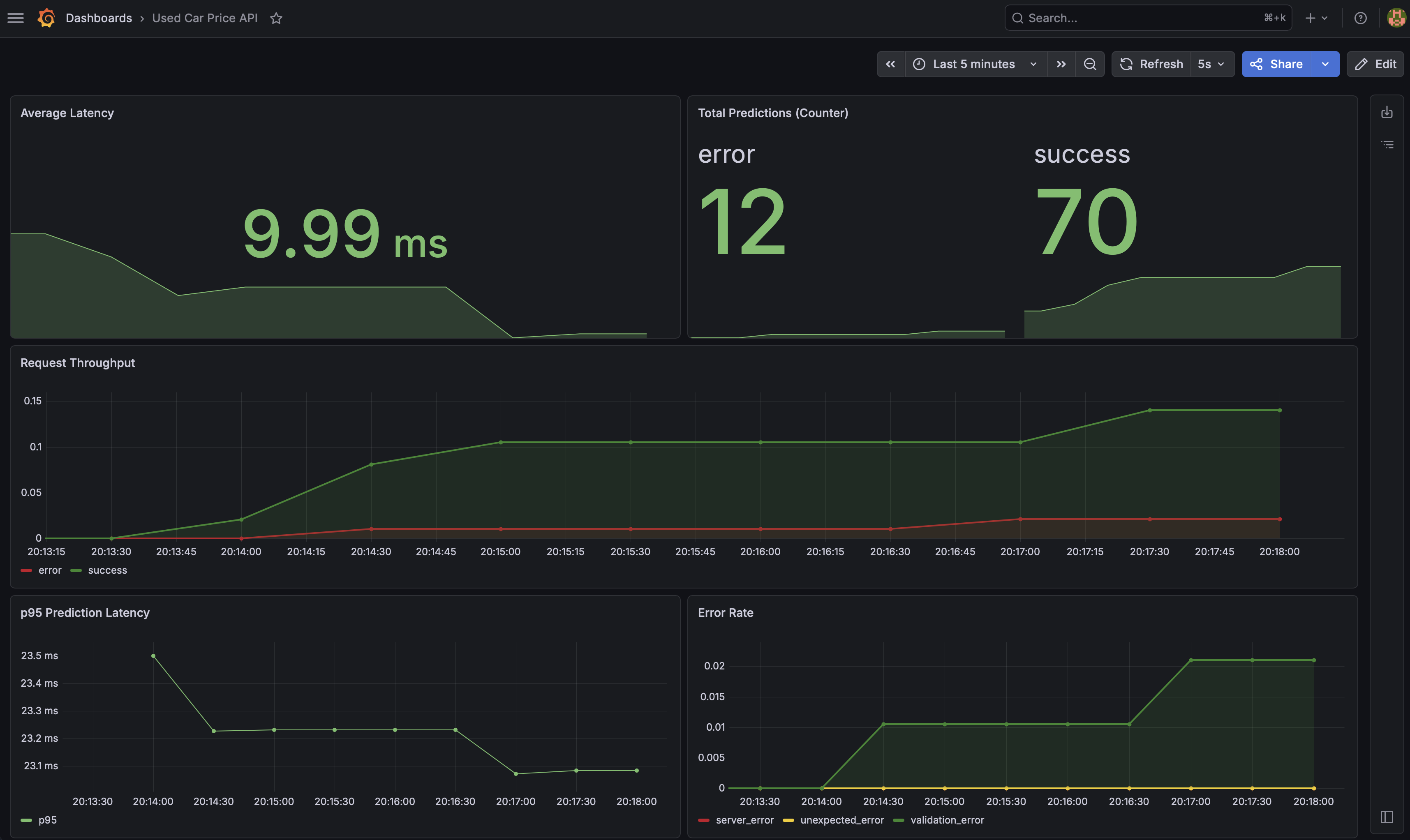
Live dashboard running on minikube — 5 panels tracking latency, throughput, error rates, and prediction counts across 2 pods