---
title: "Used Car Price Prediction (Ridge → CatBoost → FT-Transformer)"
jupyter: used-car-price
author: "Erin Weiss"
freeze: auto
format:
html:
toc: true
toc-depth: 4
code-fold: true
code-tools: true
theme: cosmo
# Workaround: "Show/Hide All Code" dropdown click handlers not attached.
# Observed on Quarto 1.8.27. Remove if fixed in a future release.
include-after-body:
- text: |
<script>
document.addEventListener('click', (e) => {
const t = e.target.closest('a, button');
if (!t) return;
const text = t.textContent.trim();
if (text === 'Show All Code') {
document.querySelectorAll('details.code-fold').forEach(d => d.open = true);
} else if (text === 'Hide All Code') {
document.querySelectorAll('details.code-fold').forEach(d => d.open = false);
}
});
</script>
execute:
echo: true
warning: false
message: false
---
## Project Background
### Objective
This project predicts used-car listing prices from structured vehicle attributes using three increasingly sophisticated modeling approaches. The goal while comparing these methods is to minimize the error, but also to examine the balance between interpretability, feature engineering effort, and evaluate predictive performance on real-world data.
::: {.callout-note title="Why This Matters"}
Applying machine learning models to used car pricing can be an effective tool for dealerships, online marketplaces, and lenders to quickly and accurately set competitive listing prices, flag underpriced inventory for acquisition, detect overpriced listings, and underwrite auto loans. A model that predicts within ~$1,300 of the true price at the median — as CatBoost does here — is accurate enough to automate first-pass pricing and reduce the need for manual appraisals. Further development of this model through incorporating additional features and ensemble methods could reduce the median margin of error even more and improve production readiness.
:::
### Dataset
The dataset comes from the Kaggle [Used Cars Dataset](https://www.kaggle.com/datasets/andreinovikov/used-cars-dataset) by andreinovikov, containing ~762k used-car listings with 20 attributes, including vehicle specs, seller information, and pricing. After cleaning and restricting to fully observed records, 243,500 listings remained for modeling.
### Modeling Strategy
Three models were implemented to explore different modeling paradigms:
- **Ridge regression** — a linear baseline that establishes a performance floor and quantifies how far a simple additive model can go on the engineered feature set.
- **CatBoost** — a gradient-boosted tree model designed for categorical-heavy tabular data. Selected as the **final production model** based on superior test-set performance.
- **FT-Transformer (Keras)** — a deep learning architecture with learned embeddings for categorical features, included as evidence of advanced experimentation rather than as the production pick.
This model progression enables direct comparison between classical machine learning and deep learning approaches using the same features and train/validation/test split.
### Model Comparison Summary
| Metric | Ridge | CatBoost | FT-Transformer |
|---|---|---|---|
| **Test RMSE (full)** | $7,824 | **$3,935** | $4,255 |
| **Test MAE (full)** | $3,011 | **$1,916** | $1,934 |
| **Test MedianAE (full)** | $1,759 | **$1,280** | $1,305 |
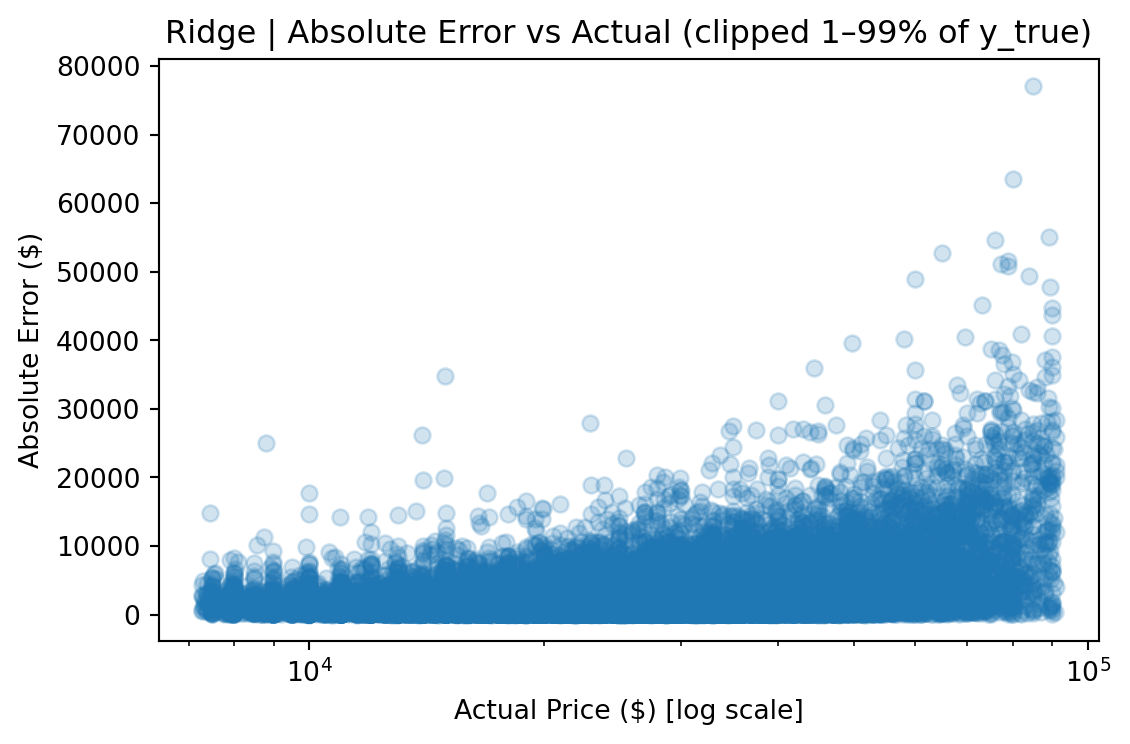
| Test RMSE (clipped 1–99%) | $4,211 | **$2,665** | $2,677 |
| Test MAE (clipped 1–99%) | $2,653 | **$1,782** | $1,800 |
| Test MedianAE (clipped 1–99%) | $1,736 | **$1,267** | $1,291 |
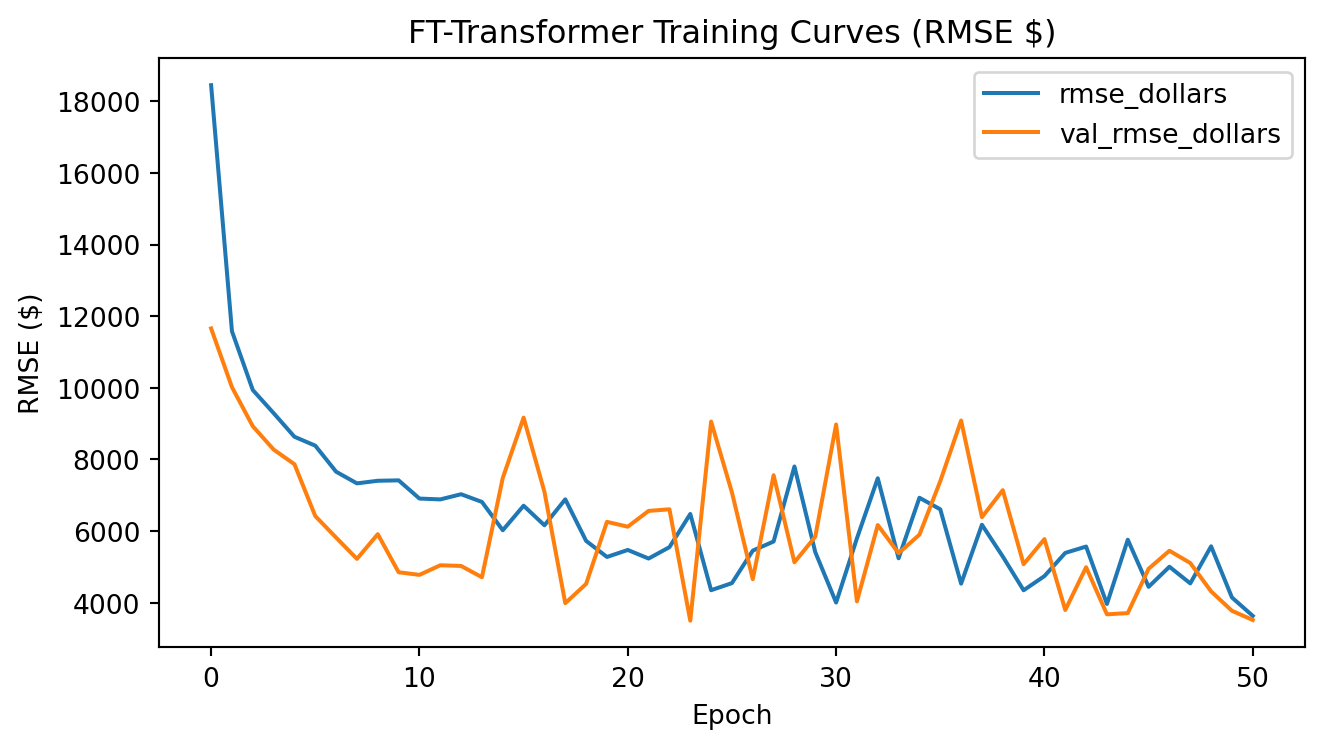
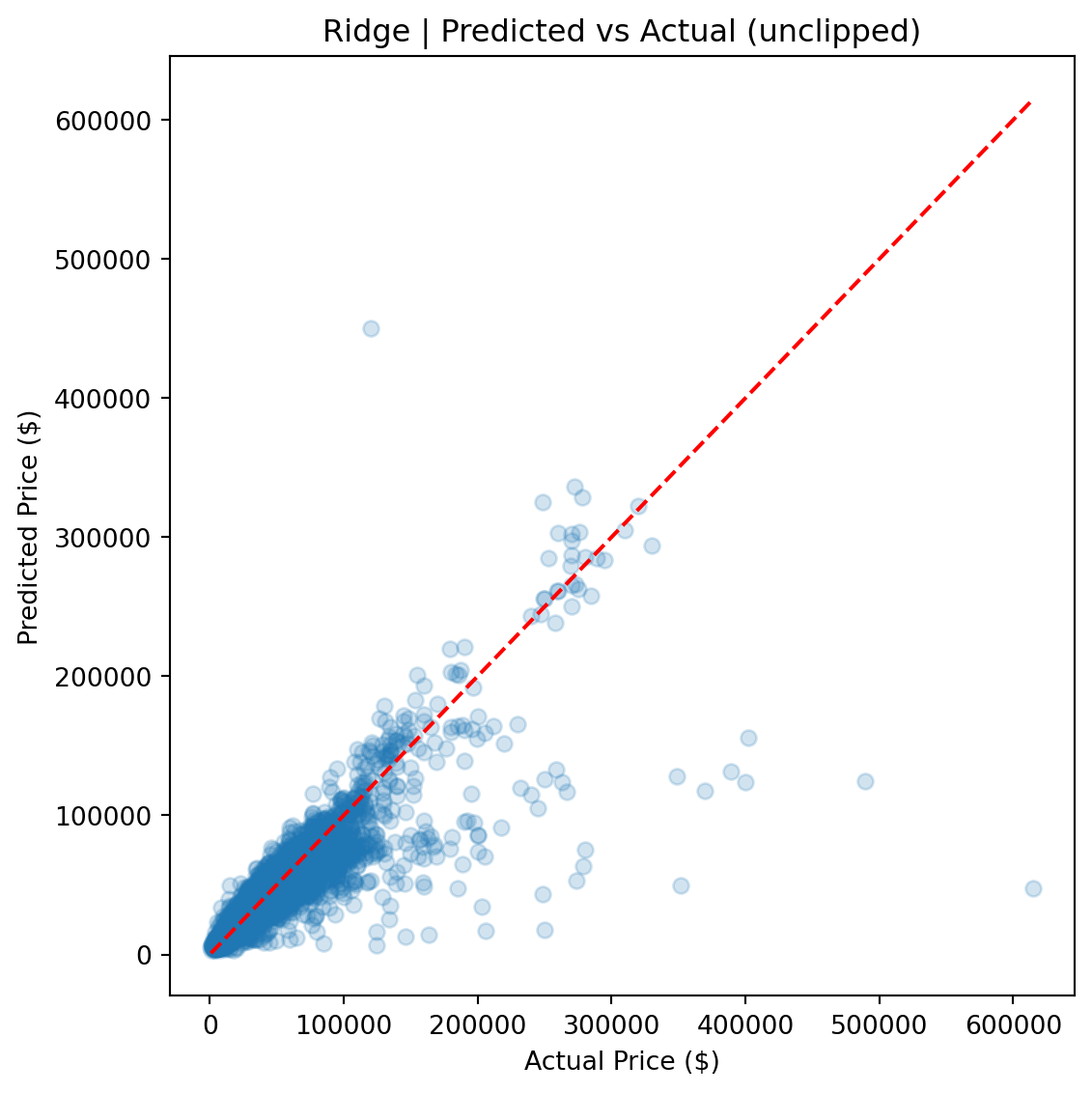
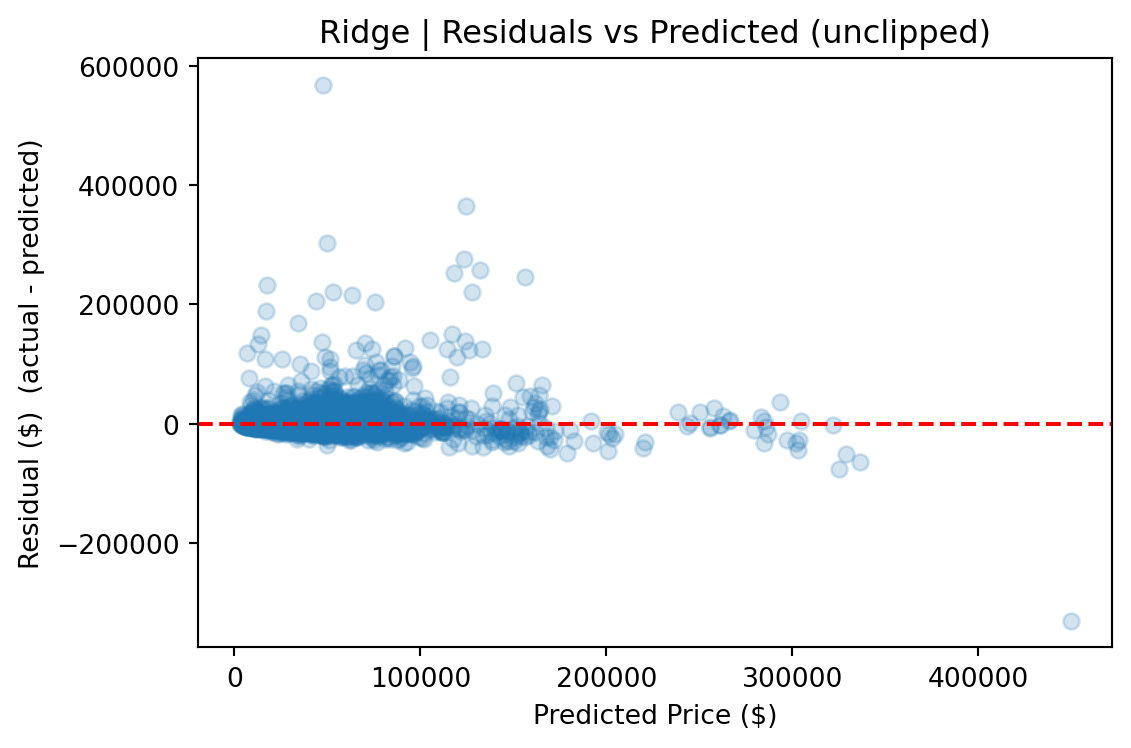
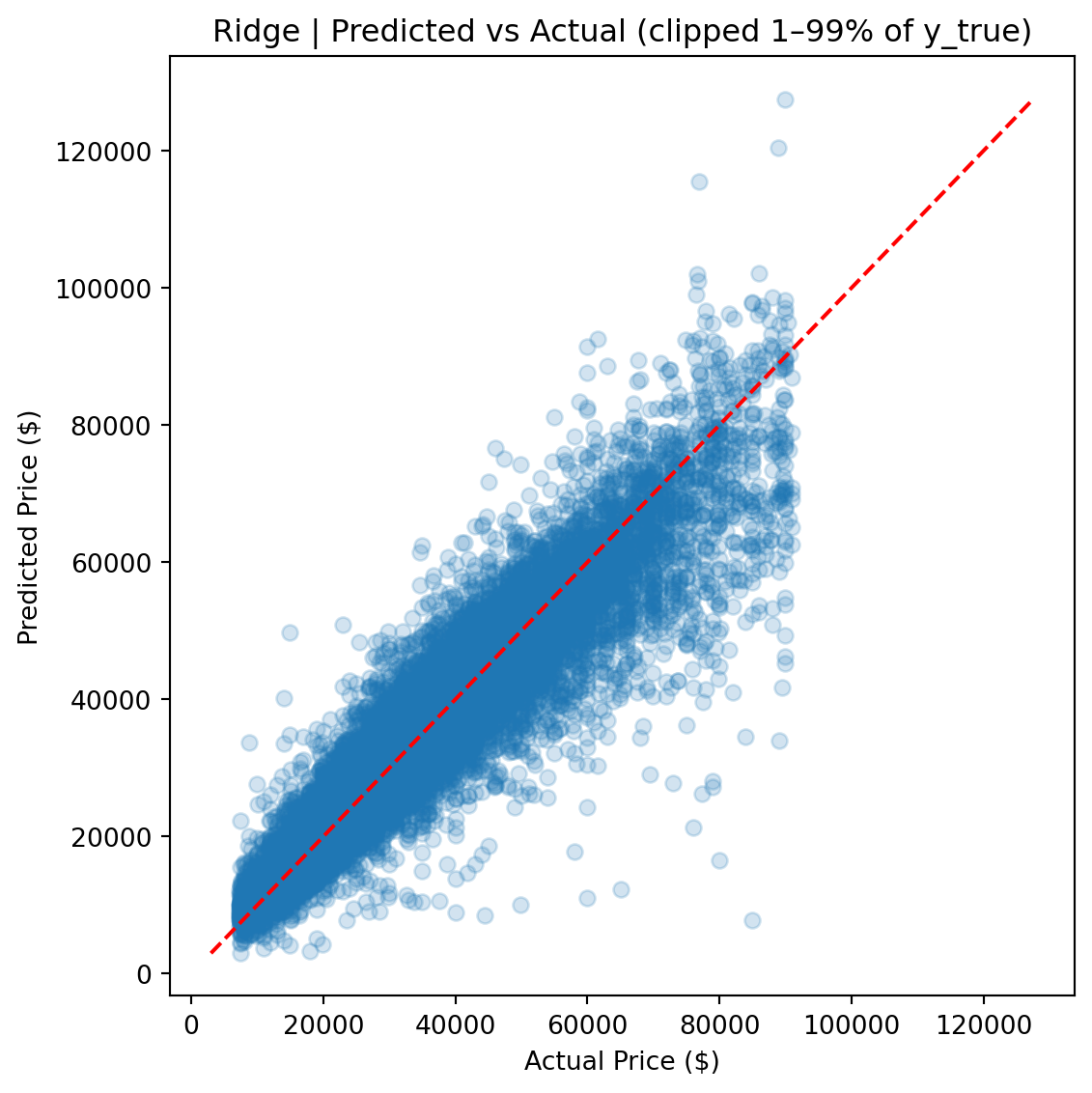
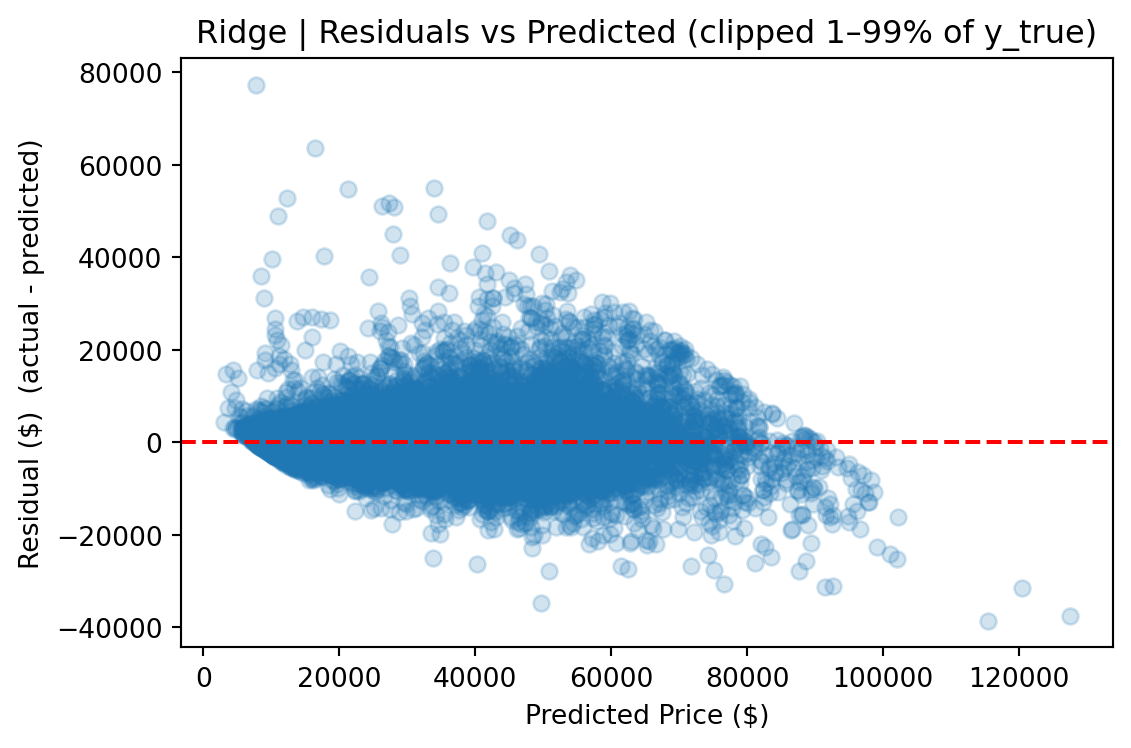
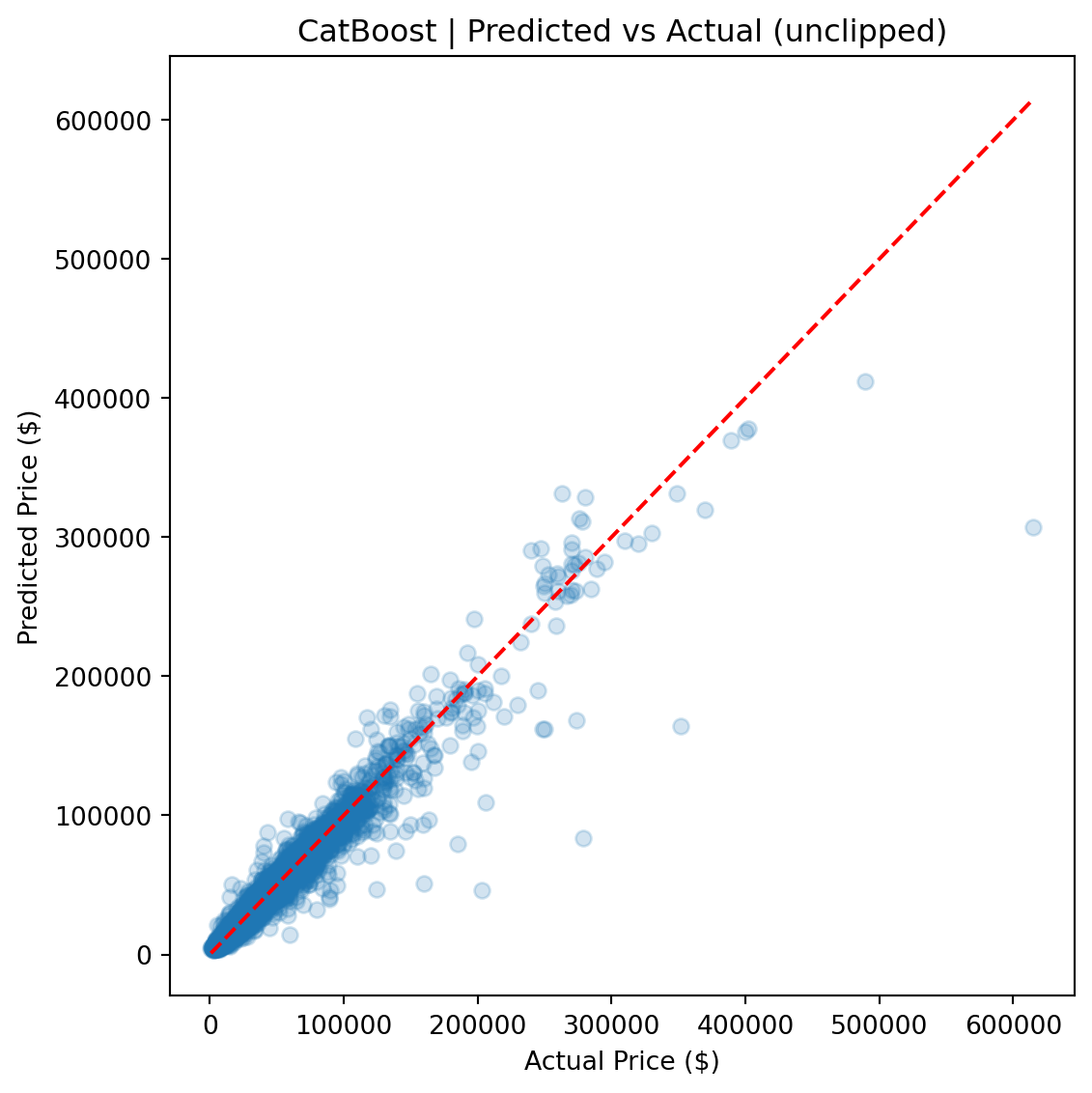
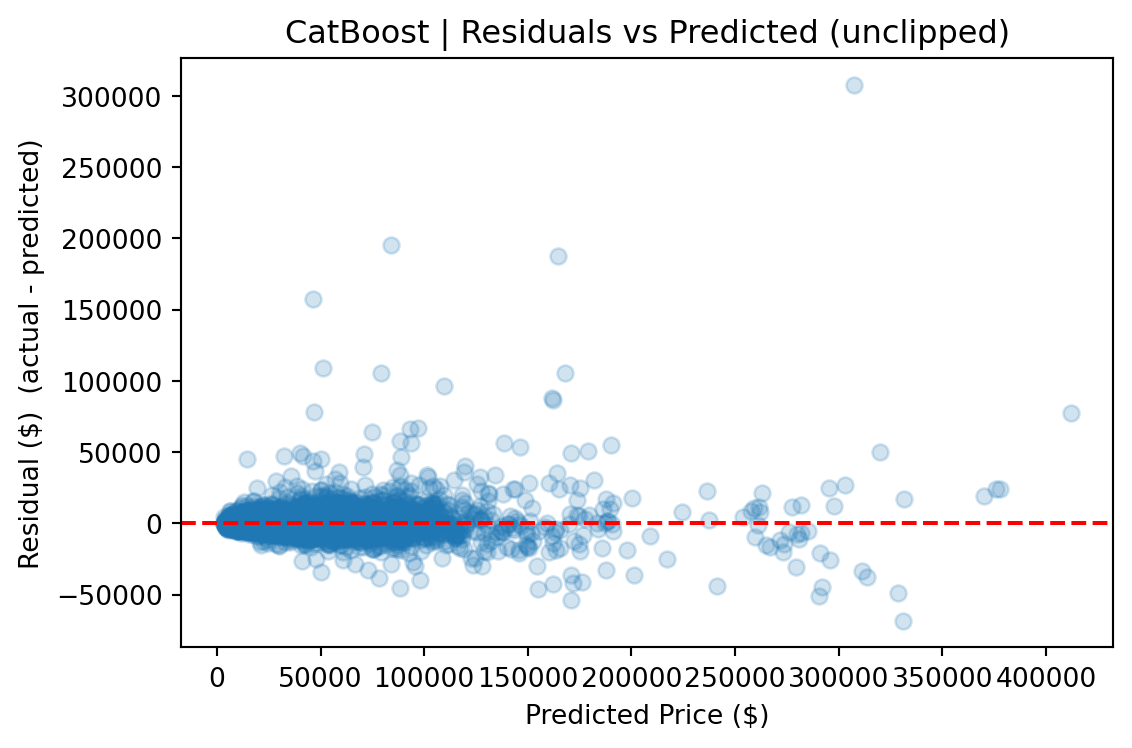
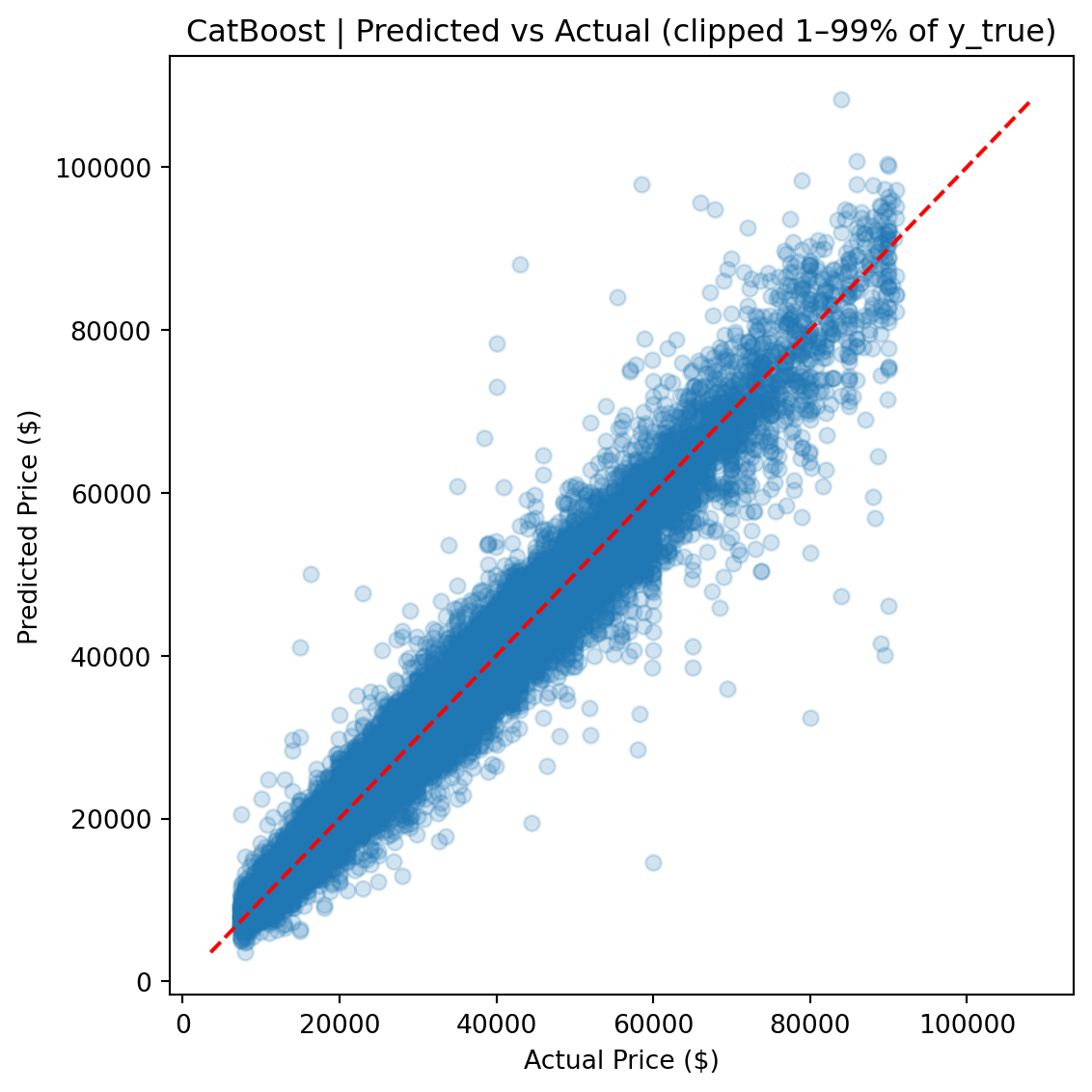
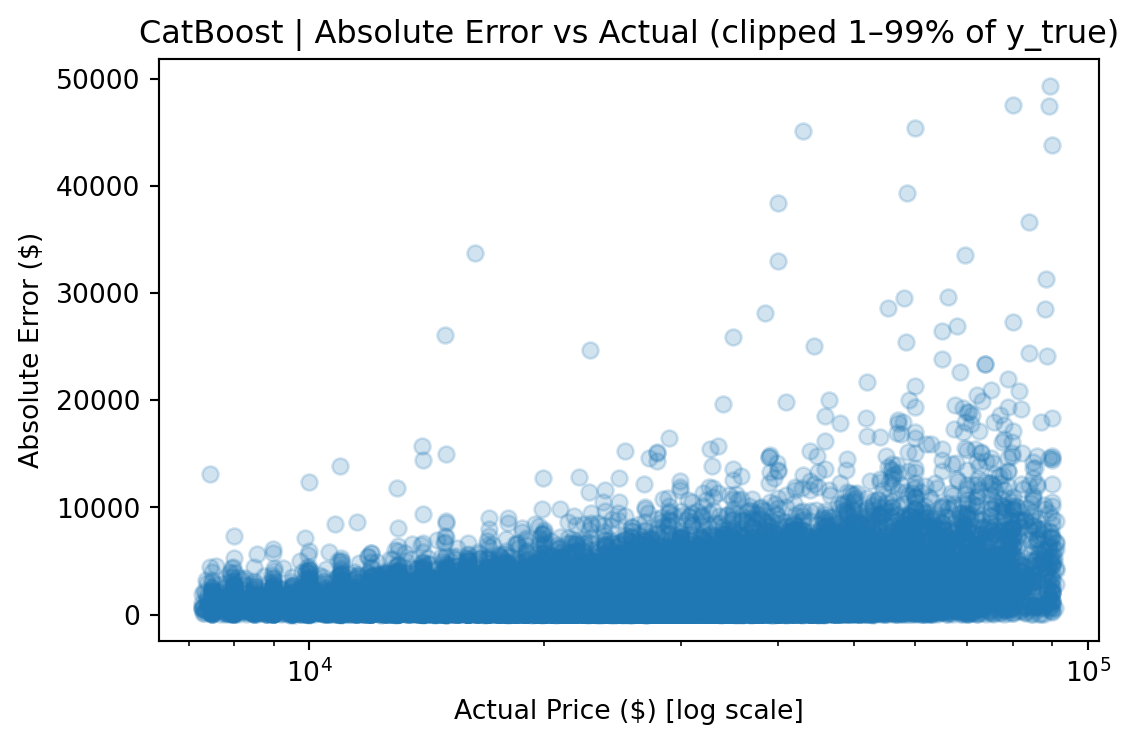
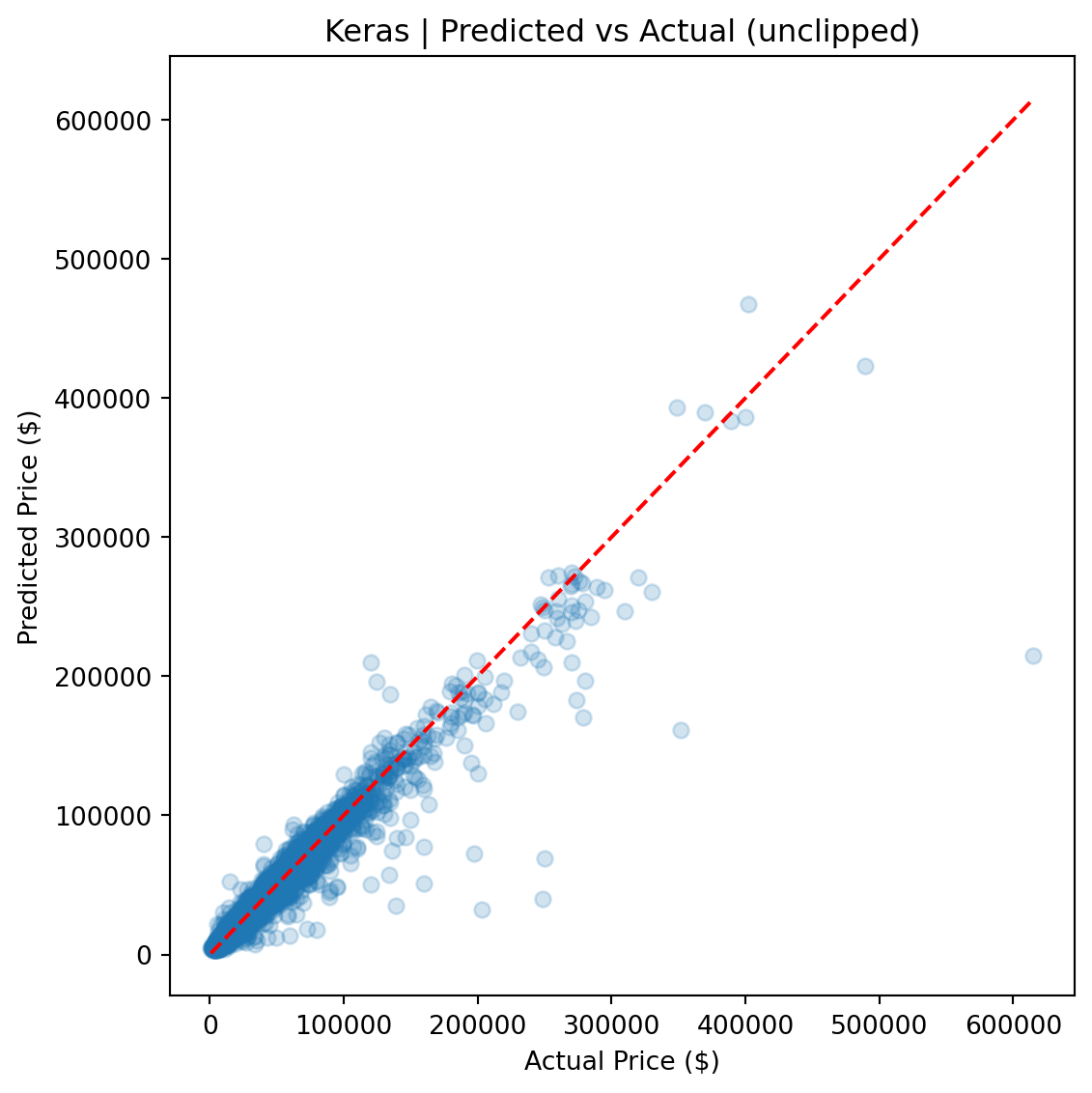
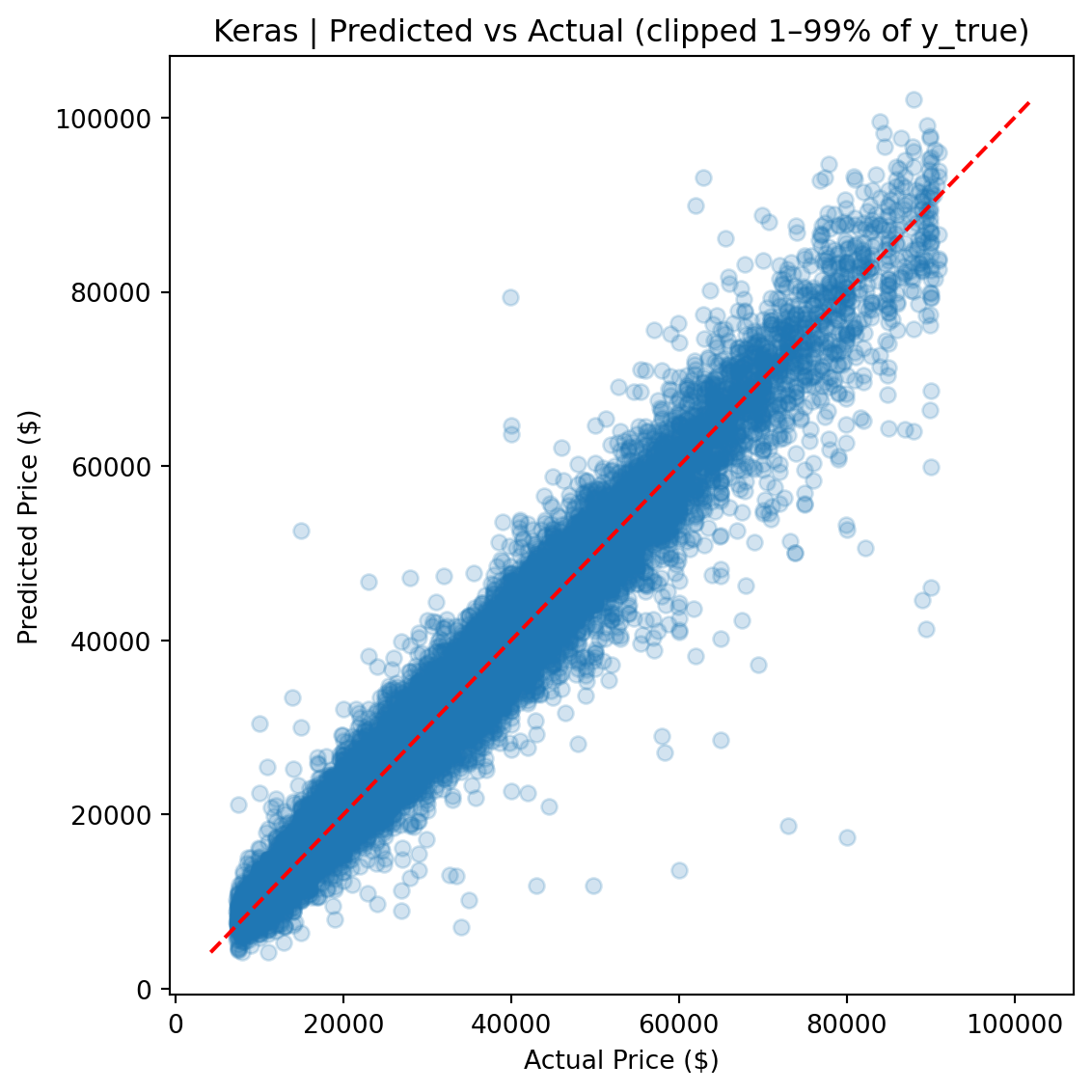
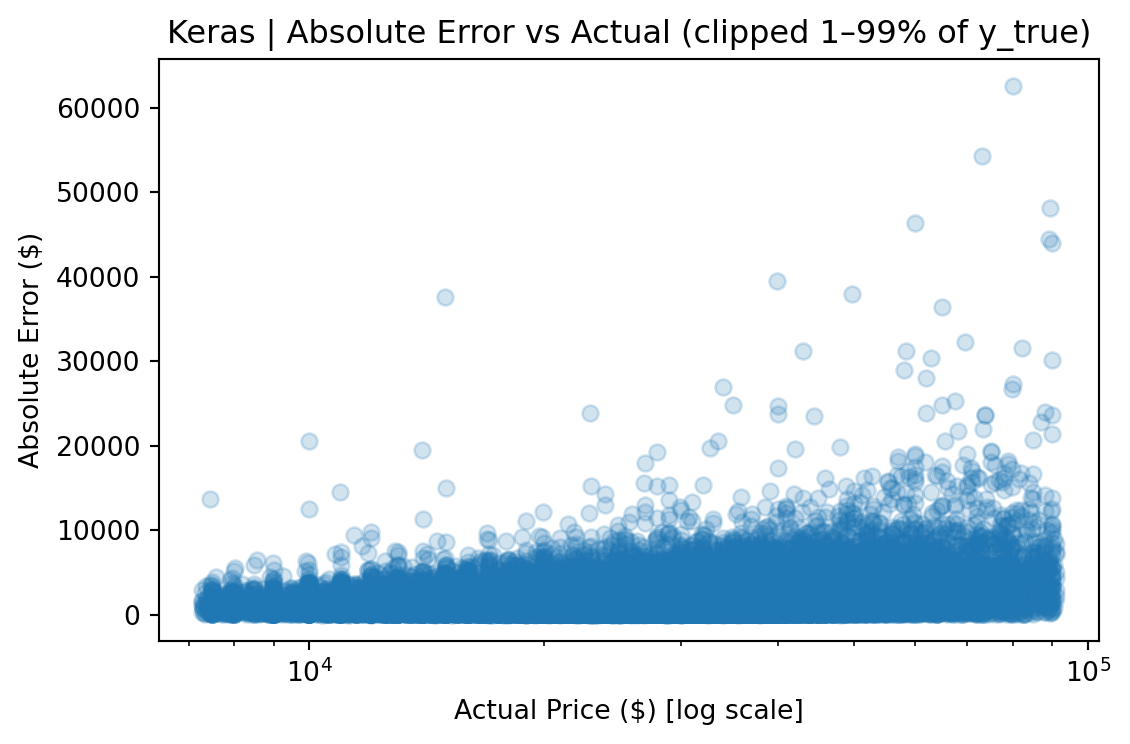
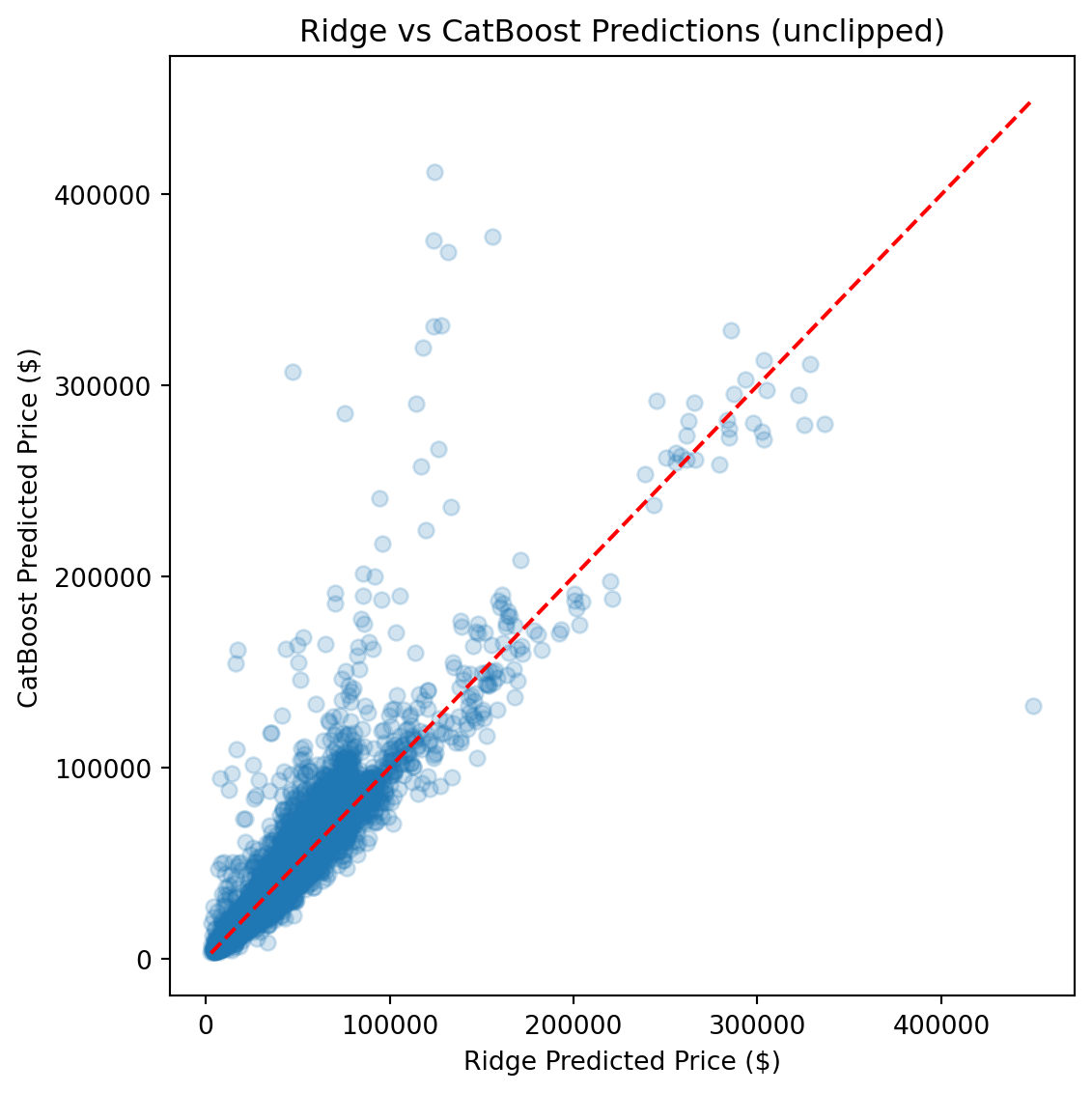
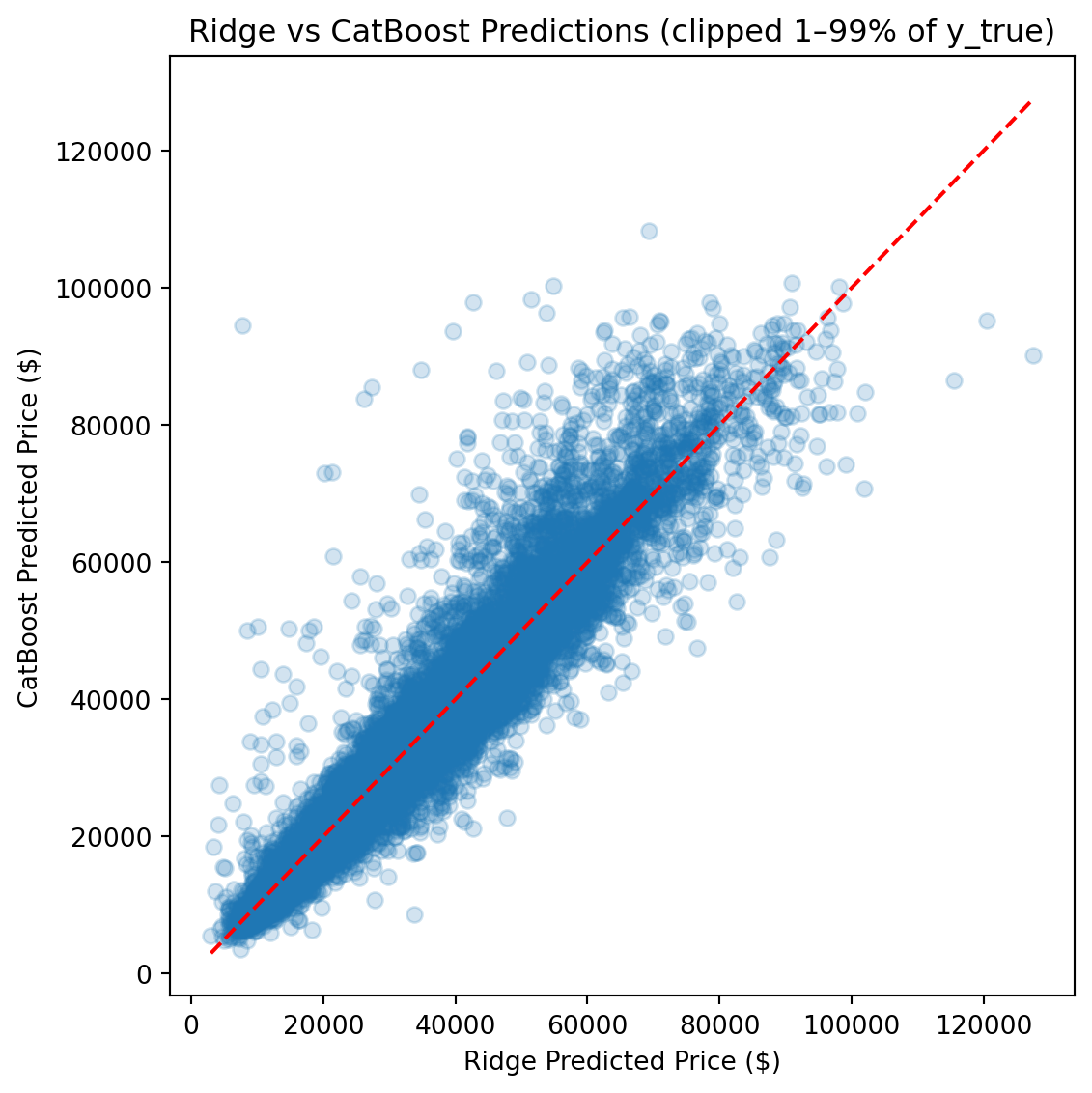
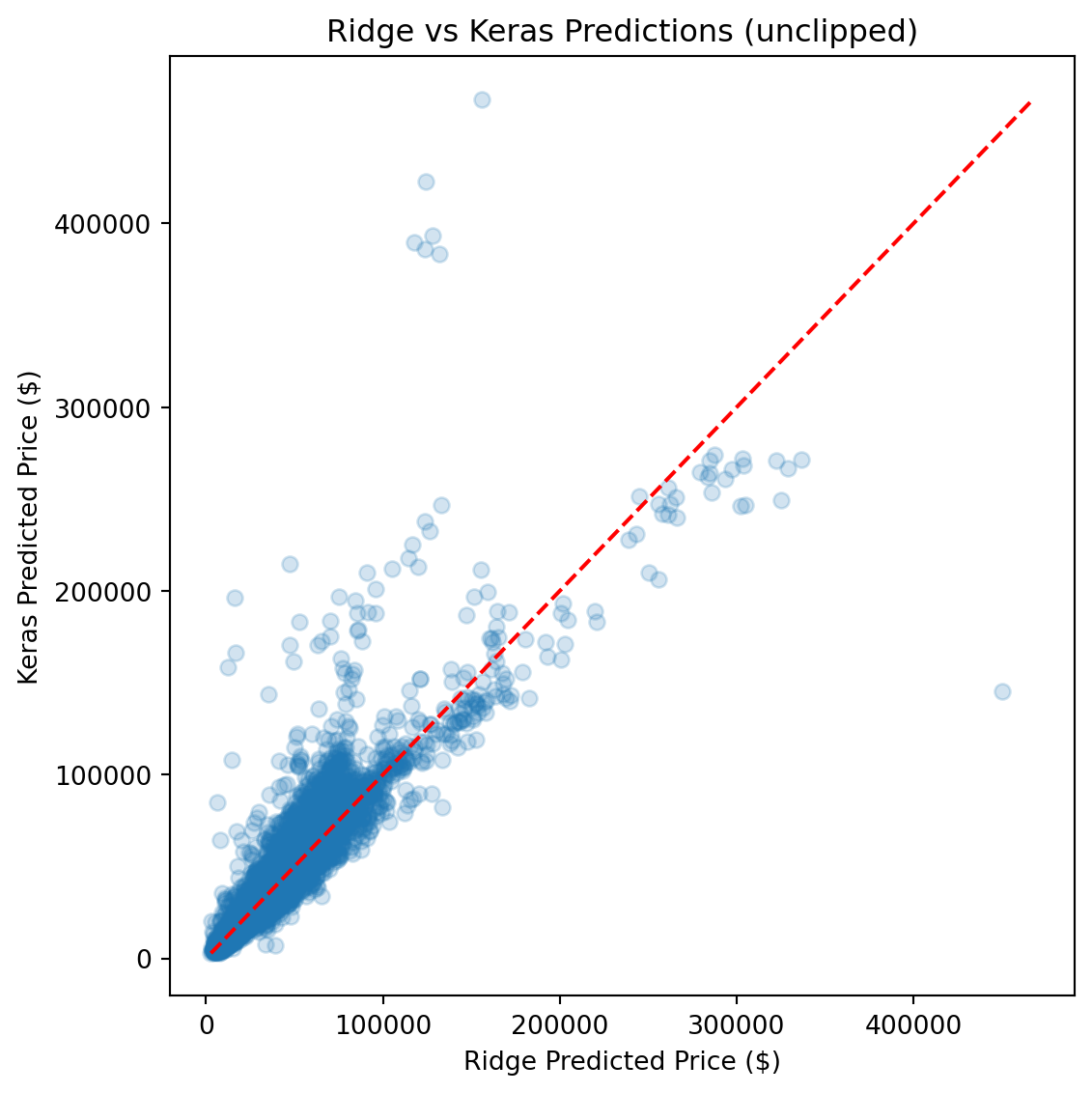
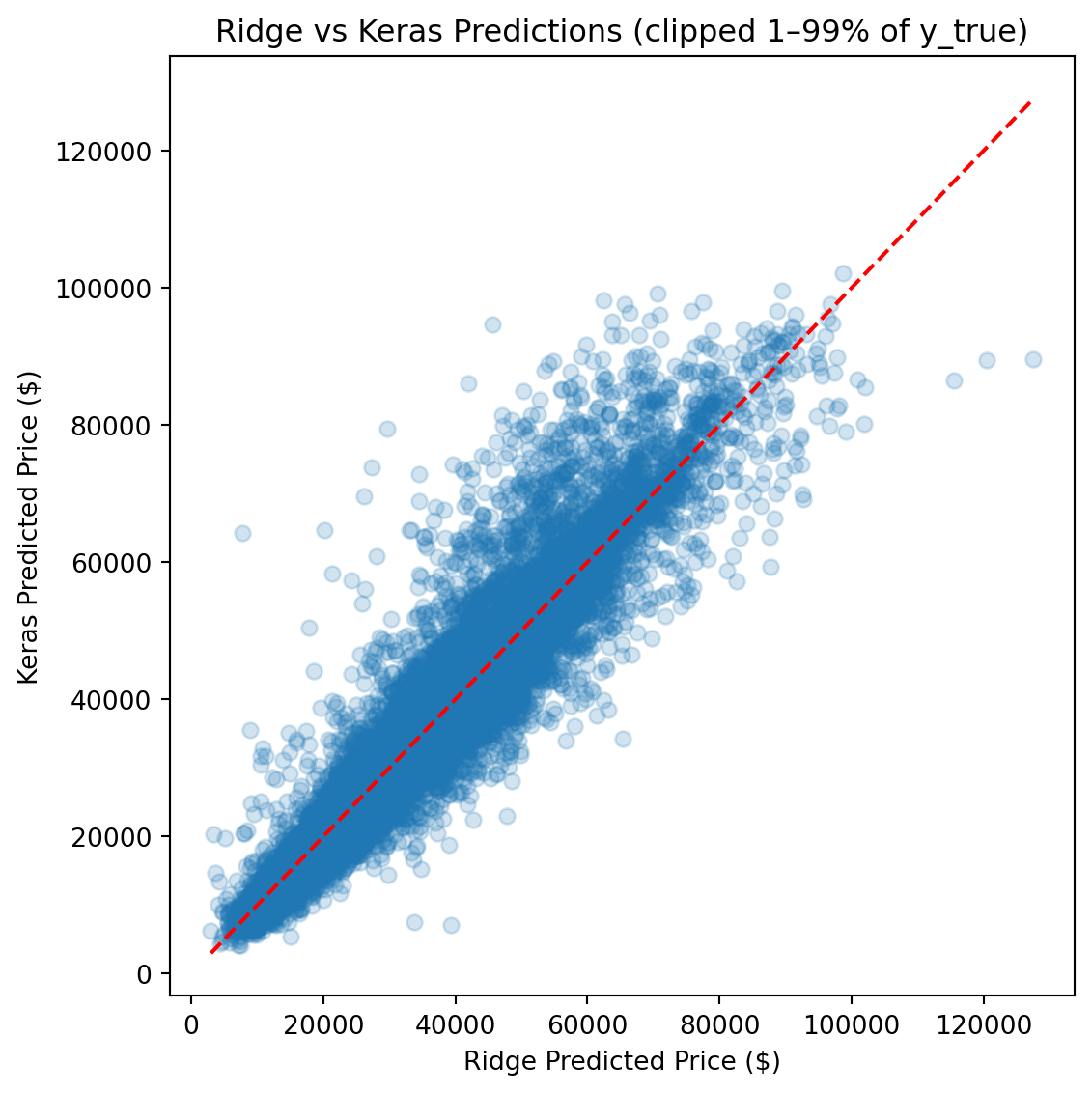
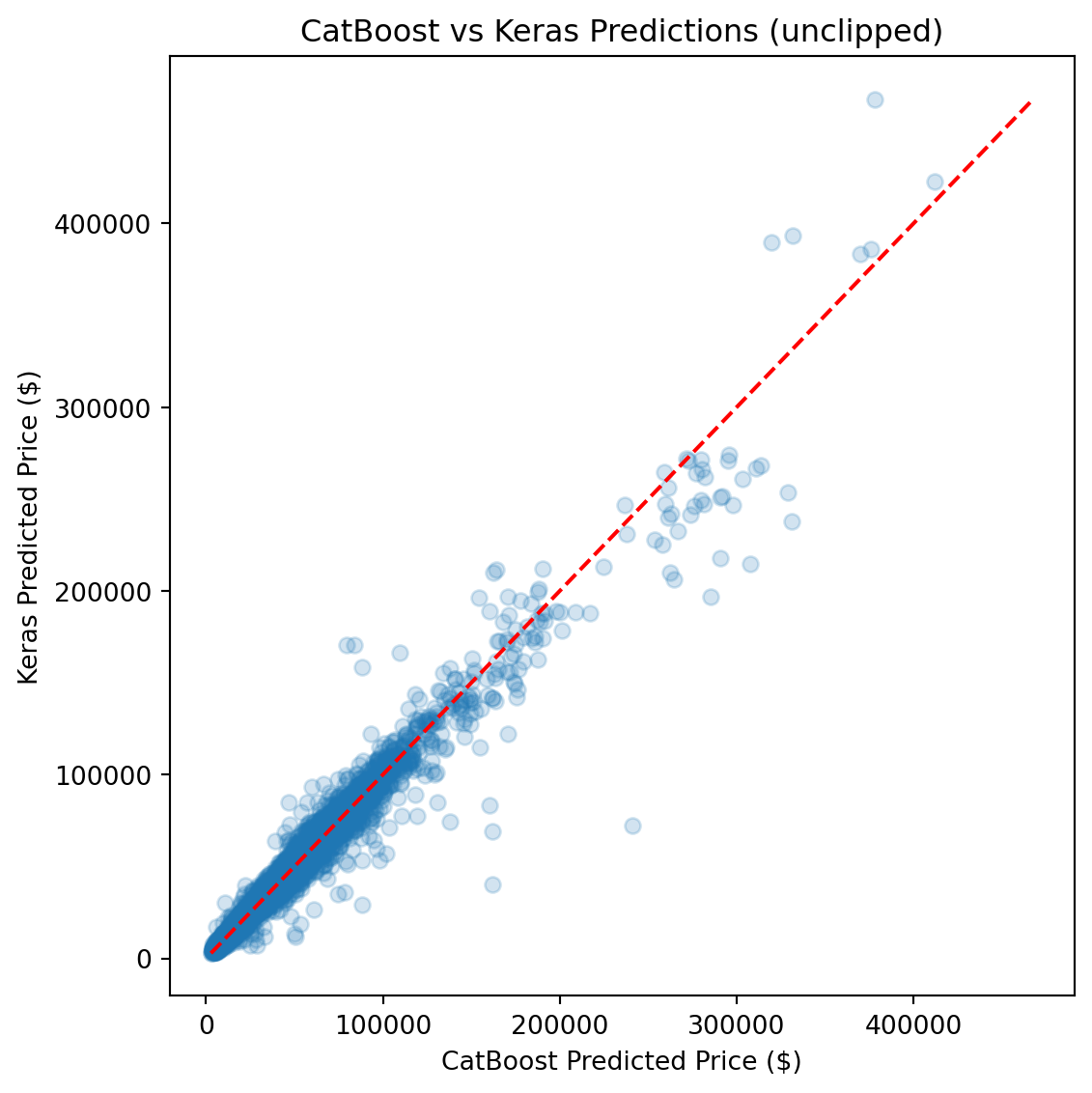
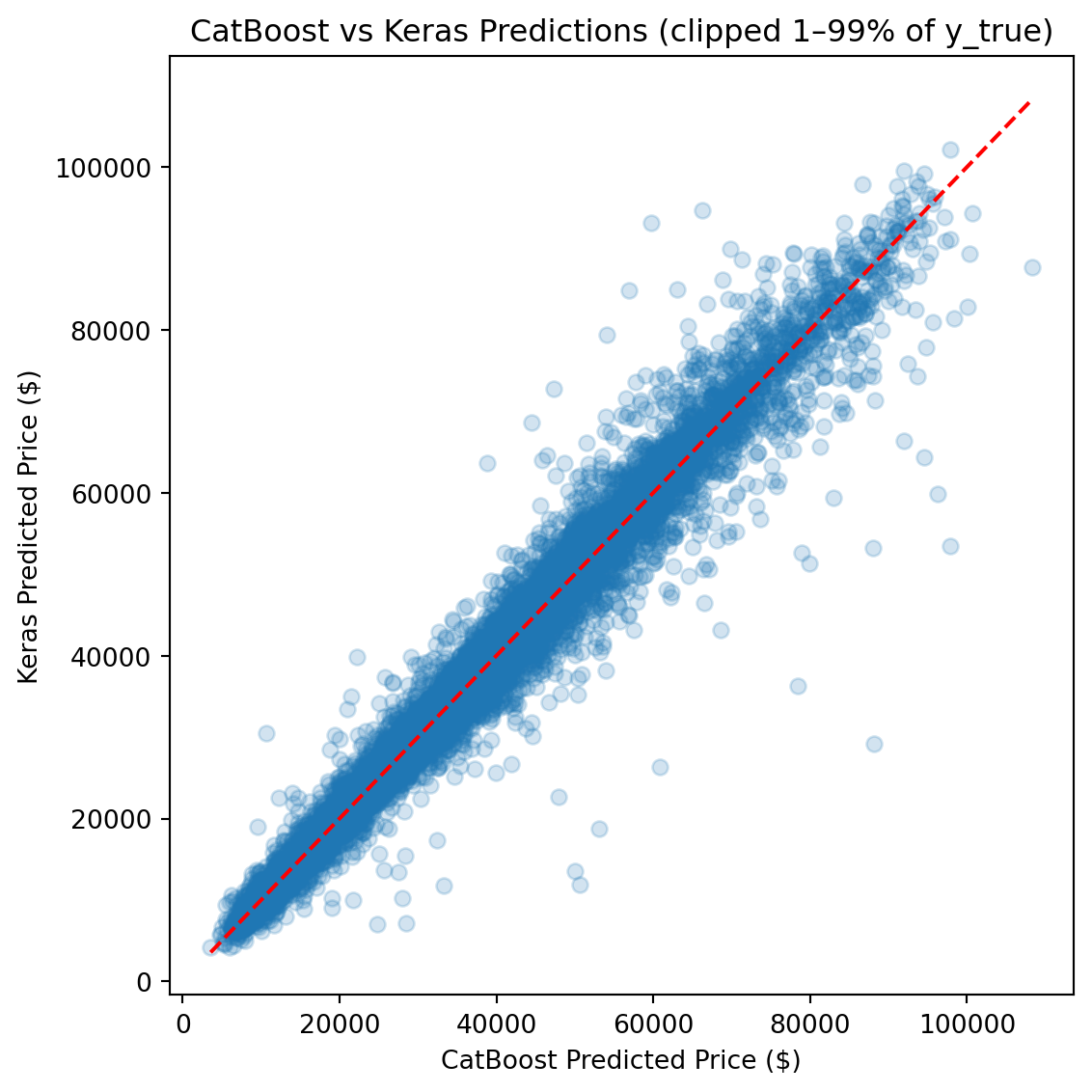
CatBoost outperforms Ridge by roughly 50% across every metric and edges out the FT-Transformer by a meaningful margin, particularly on full-distribution RMSE, where sensitivity to rare high-value vehicles amplifies differences.
Ultimately, the **CatBoost** model achieved the best generalization performance across all metrics, required the least hyperparameter tuning, and produced the most stable predictions across the full price range.
### Key Predictive Features
CatBoost's feature importance analysis highlights major predictors of vehicle price. The FT-Transformer's permutation rankings largely agree—model (25.0%), manufacturer (14.4%), mileage (14.1%), and age (12.0%) also emerge as its top features—indicating these attributes consistently hold the most information across models, not just due to algorithmic bias.
Top features include:
| Feature | Importance |
|------|------|
| Vehicle age | Highest |
| Mileage | High |
| Model | High |
| Manufacturer | High |
| MPG | Moderate |
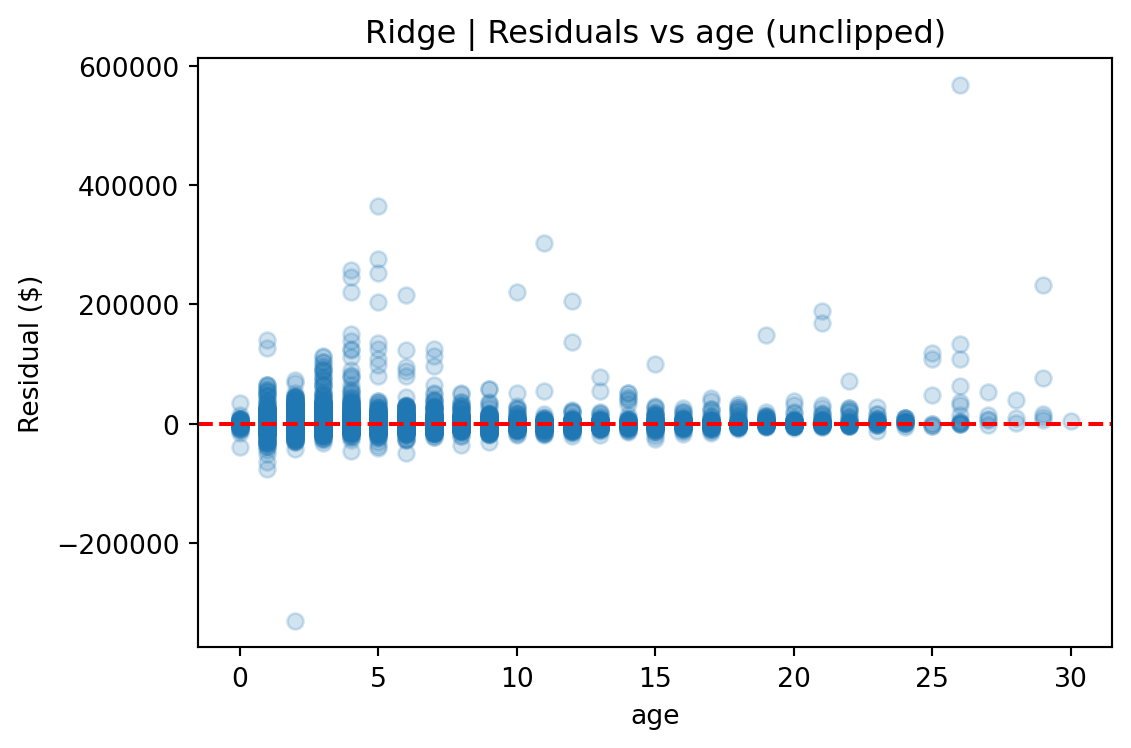
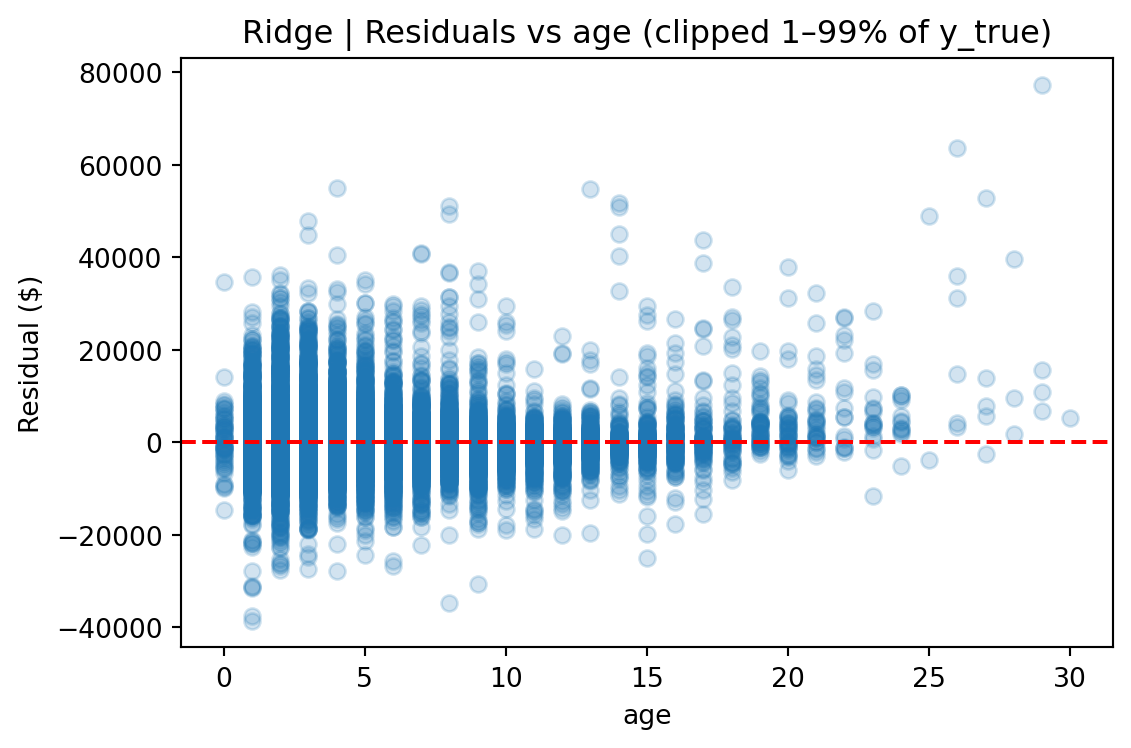
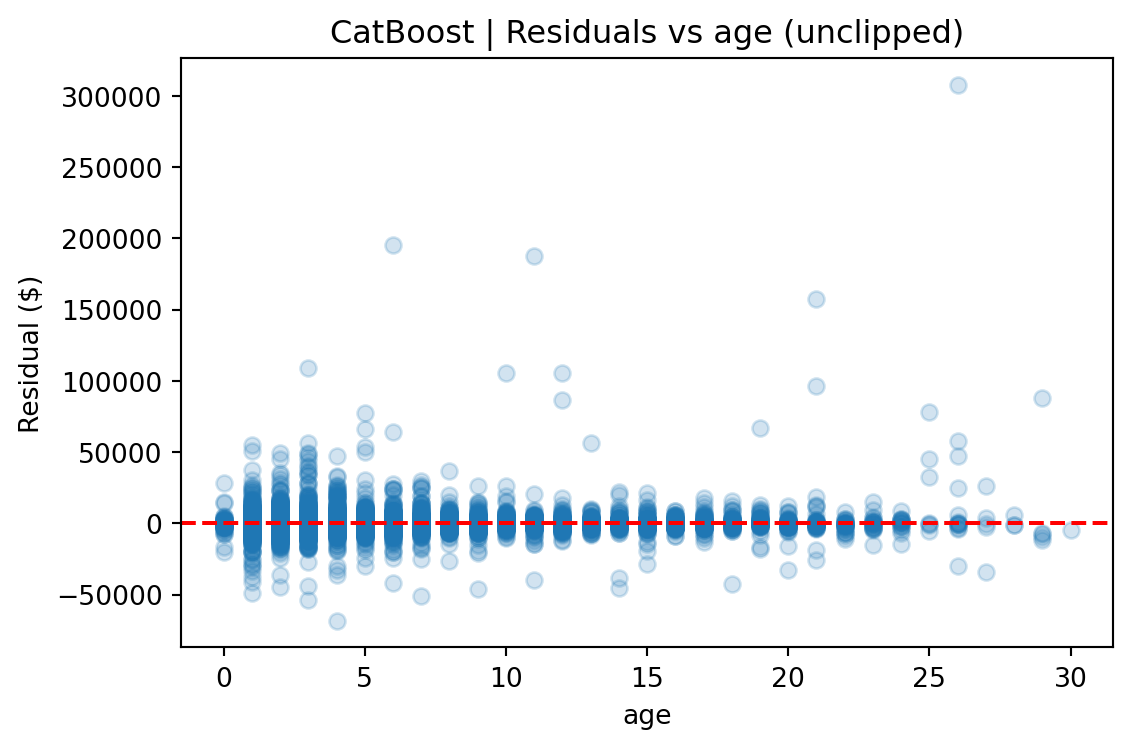
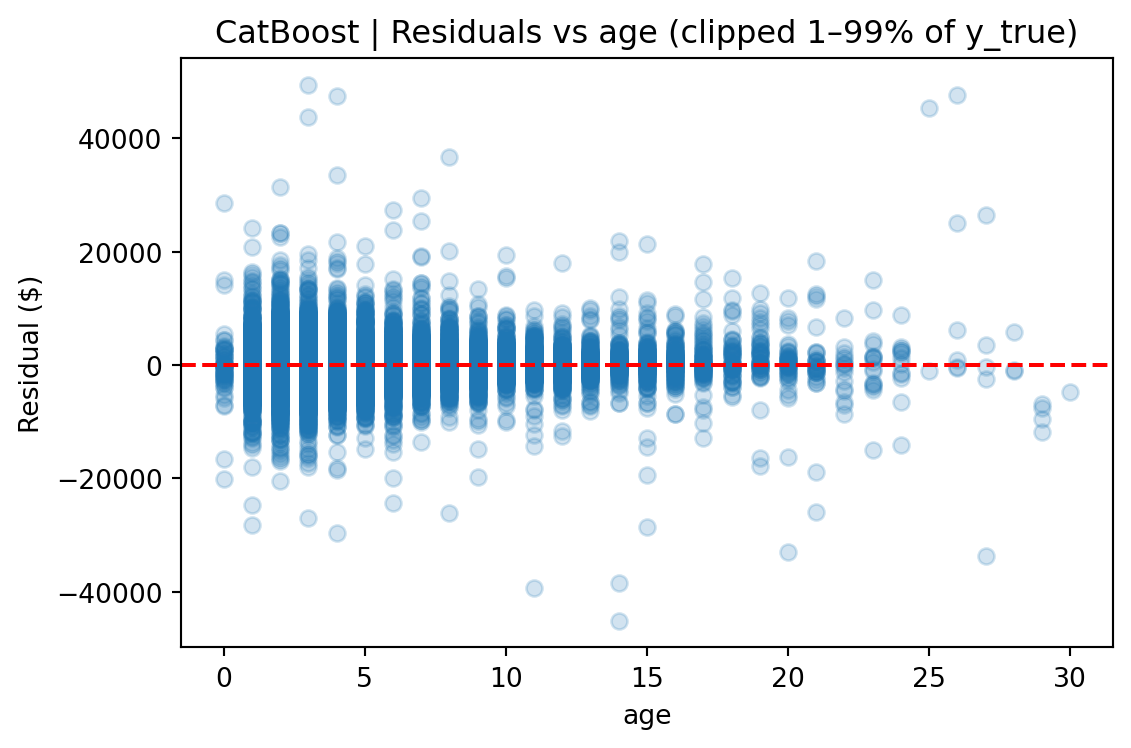
**Vehicle age and mileage are the strongest predictors of price**, reflecting standard depreciation patterns in the automotive market.
The importance of **model and manufacturer** indicates that brand and vehicle class strongly influence pricing beyond simple mechanical attributes.
Engine characteristics, such as cylinder count and displacement, also contribute to the predictive signal, reflecting differences in vehicle performance and market placement.
The model integrates both **vehicle condition factors (age, mileage)** and **brand hierarchy (manufacturer, model)** when projecting price.
### Why CatBoost Won
CatBoost's advantage comes from several sources. First, its native handling of categorical features avoids the dimensionality explosion that one-hot encoding creates for Ridge (972 dummy columns from 8 categorical features). Second, gradient-boosted trees naturally capture nonlinear interactions — such as the relationship between vehicle age, luxury status, and price — without requiring explicit interaction terms. Third, CatBoost's ordered boosting and built-in regularization made it robust to the long-tailed price distribution without additional preprocessing.
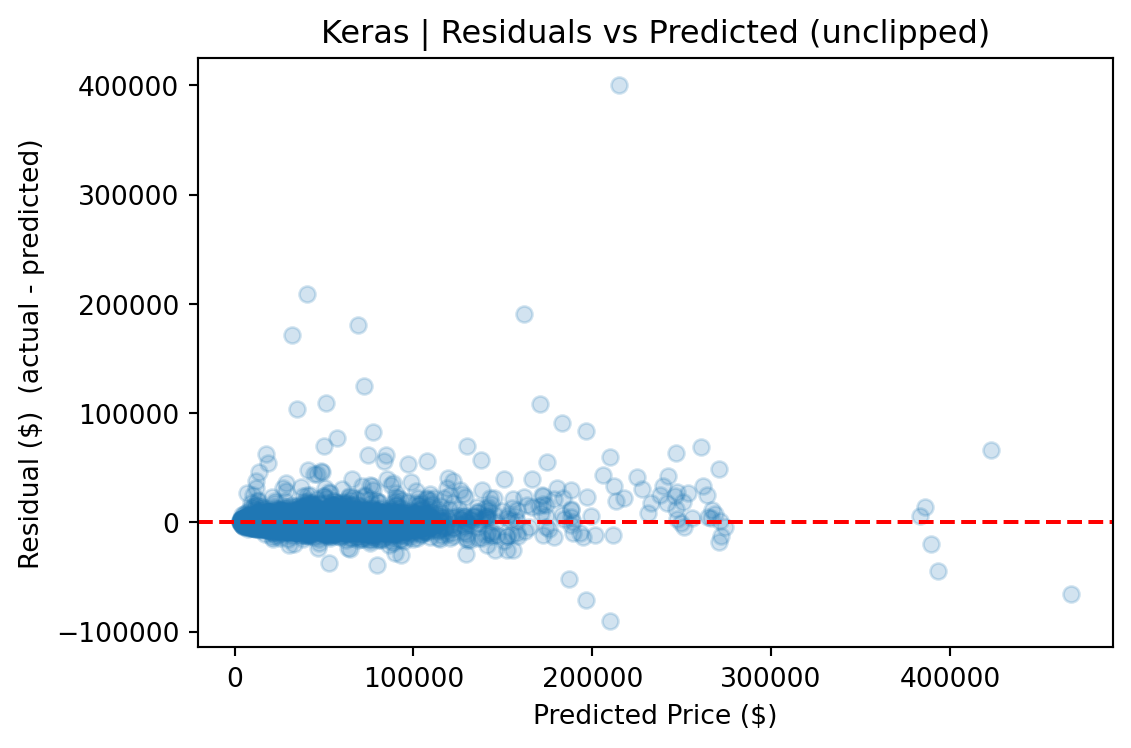
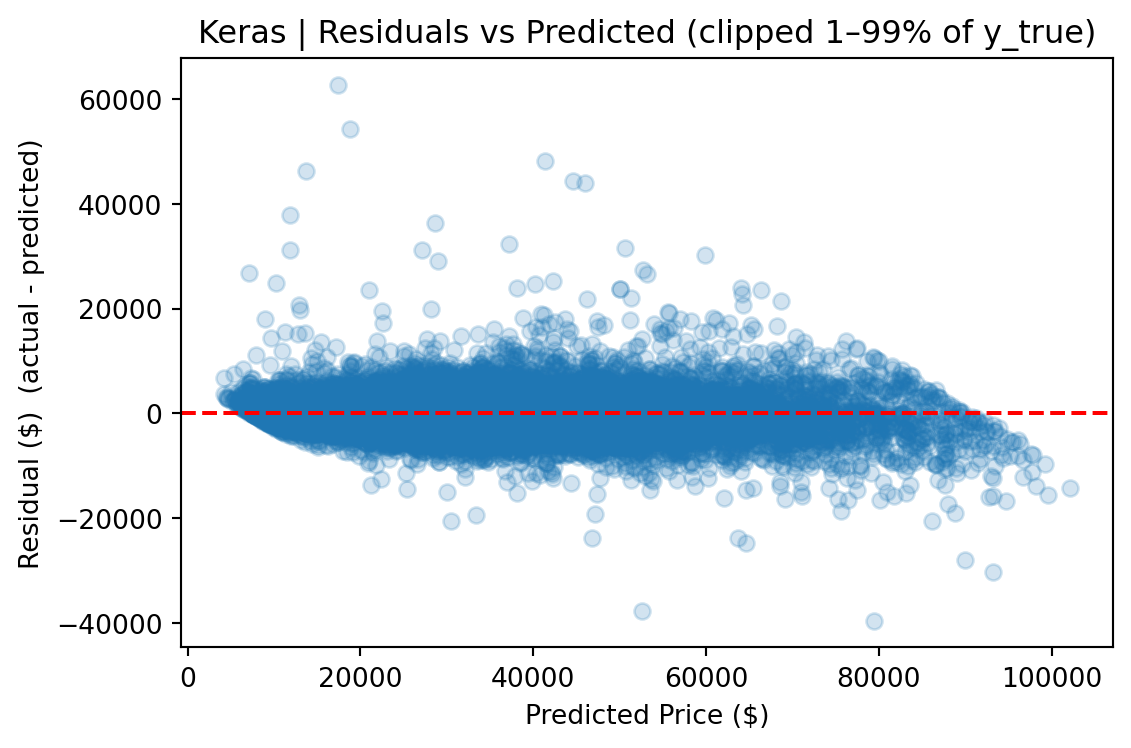
The FT-Transformer performed competitively on clipped metrics (within ~$20 of CatBoost on clipped MAE), but its full-distribution RMSE was ~8% higher, indicating greater sensitivity to rare, high-value vehicles. For a production pricing tool where dependability across the full price range matters, CatBoost is the stronger choice.
### Evaluation Methodology
The project uses a fixed 64/16/20 train/validation/test split (155,840 / 38,960 / 48,700 rows). Split indices are persisted to JSON, so all three models train and evaluate on identical rows.
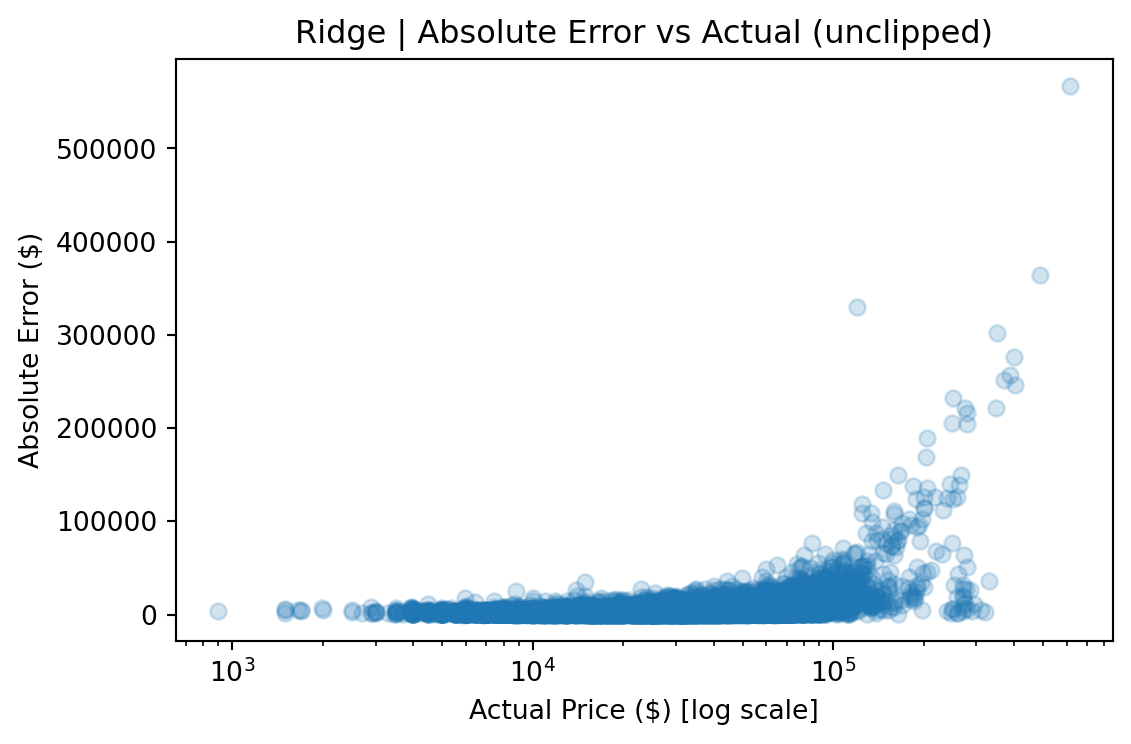
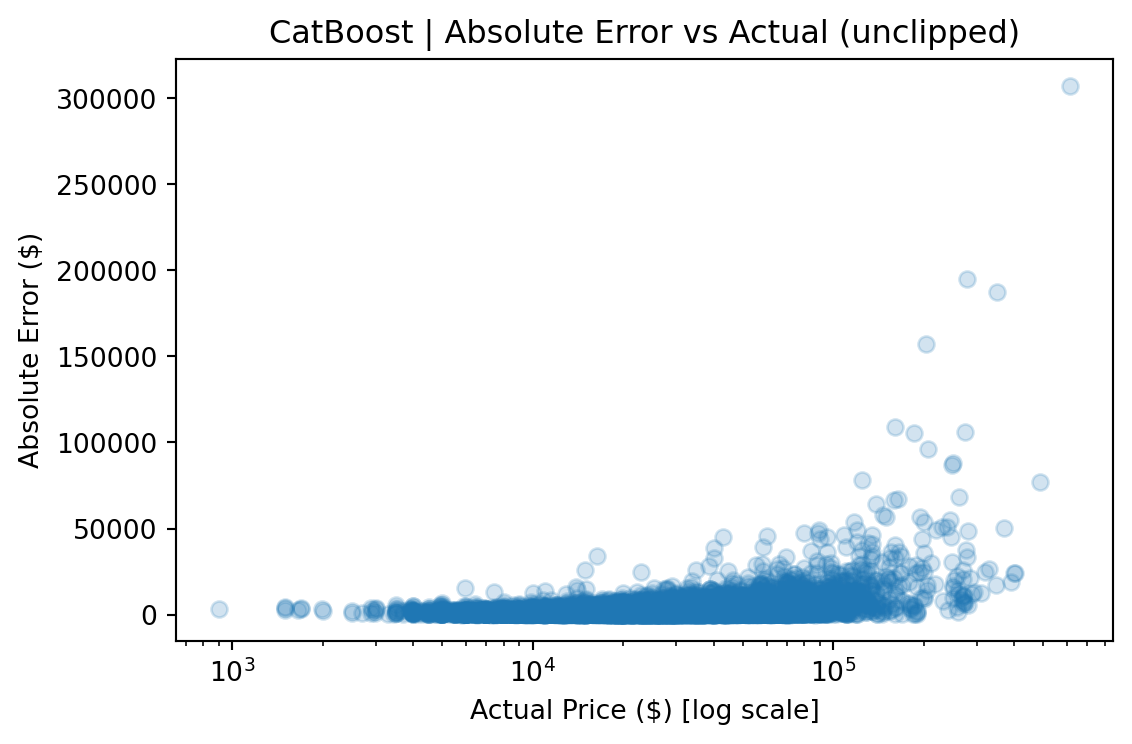
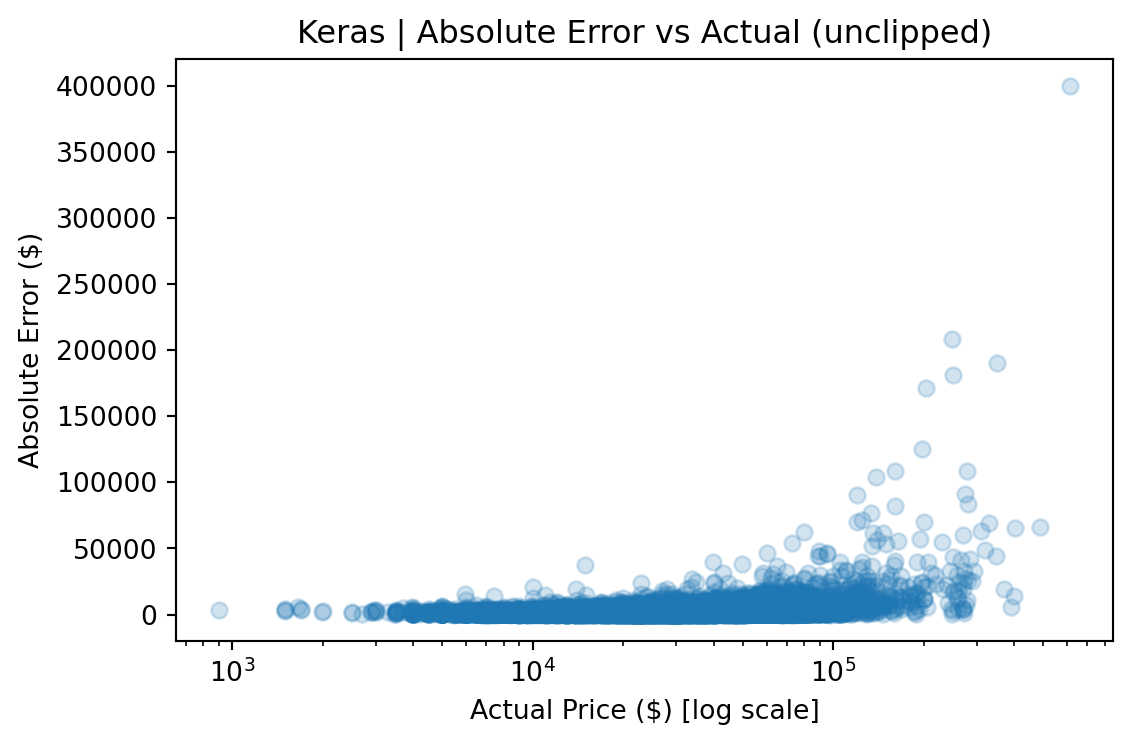
Because used-car prices are heavily skewed (median ~$27k, but a long tail past $100k, reaching $1.9M), RMSE is dominated by rare luxury vehicles priced far above the typical market price. To address this, metrics are reported in two views:
- **Full distribution** — all test rows, reflecting real-world performance, including rare luxury vehicles.
- **Clipped (1–99% of true prices)** — excludes the most extreme ~2% of listings, based on training-set price quantiles, to show performance on typical consumer vehicles.
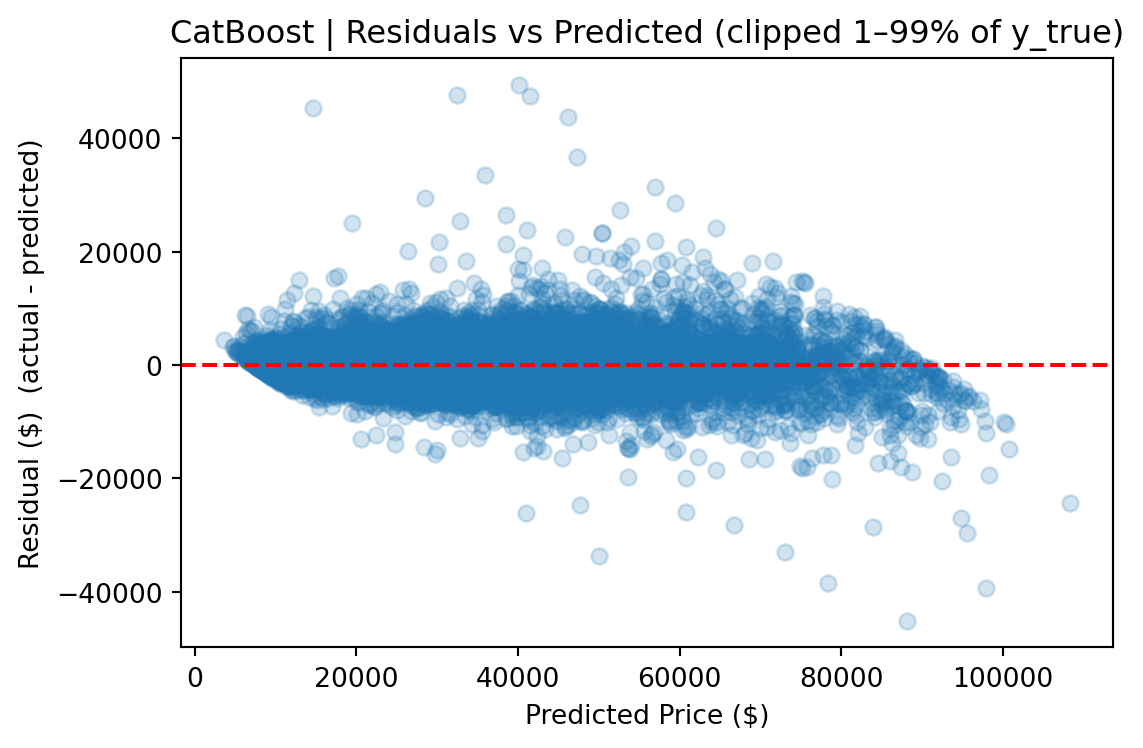
The gap between the two views (e.g., $3,935 vs. $2,665 RMSE for CatBoost) quantifies the impact of tail observations and provides a more complete picture than any single metric. The median absolute error remains stable across both views, indicating that most predictions are robust regardless of how outliers are handled.
*Note: The test set was used as a practical benchmark during iterative development across model families. Final scores should be interpreted as strong comparative results rather than a fully untouched research-grade holdout estimate.*
### Experiment Management
To maintain reproducibility, each training run writes artifacts to a timestamped run directory (e.g., `models/catboost/run_YYYYMMDD_HHMMSS/`). Each run stores model weights, hyperparameters, metrics, and schema metadata. A "latest pointer" is updated only during full training runs, and smoke runs never overwrite production artifacts.
Training behavior is controlled by two mechanisms: a global `TRAIN_MODE` flag and per-model `RETRAIN_*` flags.
`TRAIN_MODE` controls the scope of execution:
- **`full`** — runs the complete pipeline using the full dataset: data loading, feature engineering, model training (or checkpoint loading), evaluation, and artifact saving. This is the standard mode for production runs. Latest pointers are only updated in this mode.
- **`smoke`** — a quick sanity check on a small data subset with reduced hyperparameter grids and fewer training epochs. Useful for validating code changes end-to-end without committing to a full training run. Smoke runs write versioned artifacts but never updates the latest pointers.
- **`skip`** — bypasses all training logic and loads the latest existing artifacts directly for evaluation. Useful for regenerating plots or metrics without retraining.
Per-model `RETRAIN_*` flags (`RETRAIN_RIDGE`, `RETRAIN_CATBOOST`, `RETRAIN_KERAS`) provide finer control within `full` or `smoke` modes. When set to `False` (the default), the pipeline loads existing checkpoints for that model. When set to `True`, it forces fresh training while preserving prior model versions in their timestamped run directories. This allows retraining a single model without touching the others.
Additional metadata files (such as `ridge_run_info.json` and `catboost_run_info.json`) record the expected feature schema and pipeline version. When loading saved models, the code validates that the current feature pipeline matches the schema used during training, preventing accidental evaluation against incompatible feature sets.
### Data Pipeline Versioning
Cleaning and feature engineering results are cached as Parquet files. A version flag (`FEATURE_PIPELINE_VERSION`) controls cache invalidation for cleaned datasets, engineered feature tables, and the shared train/validation/test split indices. When the feature logic changes, the version is incremented to automatically rebuild stale artifacts.
## Setup and Reproducibility
### Data Setup Explanation
This project uses the Kaggle dataset
**andreinovikov/used-cars-dataset**
The raw dataset is expected at:
data/raw/cars.csv
#### Automatic download (recommended)
If `data/raw/cars.csv` is not present, the notebook will automatically download and extract the dataset using the Kaggle CLI.
The download helper supports current Kaggle authentication methods.
#### One-time setup (choose ONE option)
**Option A — Kaggle API token (recommended)**
1. Go to Kaggle → Account → API → Create New API Token
2. Set the environment variable (you can place this in `~/.zshrc`):
export KAGGLE_API_TOKEN="your_token_here"
**Option B — Token file**
mkdir -p ~/.kaggle
echo "$KAGGLE_API_TOKEN" > ~/.kaggle/access_token
chmod 600 ~/.kaggle/access_token
**Option C — Legacy Kaggle credentials (still supported)**
- `~/.kaggle/kaggle.json`, or
- environment variables `KAGGLE_USERNAME` and `KAGGLE_KEY`
#### Kaggle CLI installation
pip install kaggle
Once credentials are available, the notebook will download, extract, and automatically place `cars.csv` in `data/raw/`.
#### Manual download of CSV file
If you prefer not to use the Kaggle CLI, manually download the dataset from Kaggle and place it:
cars.csv → data/raw/cars.csv
The remainder of the pipeline will run unchanged.
#### Folder Structure
> Note: This report automatically exports reusable pipeline code to `src/pipeline.py`. Additional modules in `src/` are placeholders for future CLI training and deployment.
This report runs **locally**. It uses:
- **Portable paths** (no hard-coded `/content/` paths)
- **Kaggle CLI** to download the dataset once
- **Checkpoint saves** after each stage (cleaned data, engineered features, trained models)
> **Folder structure:**
>
> - `data/`
> - `raw/` (created)
> - `cars.csv` (raw dataset)
> - `processed/` (created)
> - `cars_cleaned_v{FEATURE_PIPELINE_VERSION}.parquet` (written)
> - `cars_features_v{FEATURE_PIPELINE_VERSION}.parquet` (written)
> - `splits_indices_v{FEATURE_PIPELINE_VERSION}.json` (written; shared train/val/test indices)
>
> - `models/` (created)
> - `metrics/` (created)
> - `metrics_latest.json` (written)
> - `metrics_{timestamp}.json` (written)
>
> - `ridge/` (created)
> - `ridge_pipeline.joblib` (latest pointer; written only on `TRAIN_MODE="full"`)
> - `ridge_run_info.json` (latest metadata; used for schema validation)
> - `run_{timestamp}_{train_mode}/` (created)
> - `ridge_pipeline.joblib` (versioned)
> - `run_info.json` (written)
> - `ridge_metrics.json` (written)
>
> - `catboost/` (created)
> - `catboost_final.cbm` (latest pointer; written only on `TRAIN_MODE="full"`)
> - `catboost_run_info.json` (latest metadata; used for schema validation)
> - `catboost_final_params.json` (latest final hyperparameters)
> - `catboost_stage1_best_params.json` (latest Stage 1 best params)
> - `catboost_stage1_done.txt` (Stage 1 completion marker)
> - `catboost_stage2_best_params.json` (latest Stage 2 best params)
> - `catboost_stage2_done.txt` (Stage 2 completion marker)
> - `catboost_done.txt` (final training completion marker)
> - `feature_columns.json` (latest feature column list)
> - `run_{timestamp}_{train_mode}/` (created)
> - `catboost_final.cbm` (versioned)
> - `run_info.json` (written)
> - `final_params.json` (written)
> - `final_training_summary.json` (written)
> - `feature_columns.json` (written)
> - `metrics.json` (written)
> - `stage1_best_params.json` (written)
> - `stage1_done.txt` (written)
> - `stage2_best_params.json` (written)
> - `stage2_done.txt` (written)
> - `catboost_done.txt` (written)
>
> - `keras/` (created)
> - `keras_model.weights.h5` (latest pointer; written only on `TRAIN_MODE="full"`)
> - `keras_run_info.json` (latest metadata)
> - `keras_train_medians.json` (latest numeric imputation values)
> - `keras_num_norm_stats.json` (latest normalization statistics)
> - `keras_lookup_vocabs.json` (latest categorical vocabularies)
> - `keras_history.json` (latest training history)
> - `keras_training_loss.png` (latest training loss curve)
> - `keras_training_rmse.png` (latest training RMSE curve)
> - `tuning_history.json` (cumulative tuning log across all rounds)
> - `runs/`
> - `run_{timestamp}_{train_mode}/` (created)
> - `keras_model.weights.h5` (versioned trained weights)
> - `run_info.json` (written)
> - `keras_metrics.json` (written)
> - `keras_history.json` (training history for this run)
> - `keras_training_loss.png` (training loss curve for this run)
> - `keras_training_rmse.png` (training RMSE curve for this run)
> - `train_medians.json` (numeric imputation values)
> - `num_norm_stats.json` (normalization mean/standard deviation)
> - `lookup_vocabs.json` (categorical vocabularies)
> - `tuner/`
> - `ft_{tuner_kind}_{mode}_{timestamp}/` (KerasTuner project directories)
> - `best_hp_{mode}_ft_{tuner_kind}_{mode}_{timestamp}.json` (best hyperparameters per tuning run)
>
> - `api_artifacts/` (created)
> - `categorical_vocabularies.json` (known values per categorical feature)
> - `models_by_manufacturer.json` (valid model names grouped by manufacturer)
> - `numeric_medians.json` (median imputation values for optional numeric fields)
> - `model_metadata.json` (feature columns, clip bounds, drivetrain map, luxury brands, pipeline version)
>
> - `notebooks/`
> - `01_used_car_price_regression.qmd` (this report)
> - `01_used_car_price_regression.html` (rendered output)
>
> - `src/`
> - `__init__.py`
> - `pipeline.py` (exported cleaning and feature engineering code)
> - `data_prep.py` (scaffolded for containerized pipeline)
> - `features.py` (scaffolded for containerized pipeline)
> - `train_ridge.py` (scaffolded for containerized pipeline)
> - `train_catboost.py` (scaffolded for containerized pipeline)
> - `train_keras.py` (scaffolded for containerized pipeline)
>
> - `.gitignore`
> - `pyproject.toml` (project metadata and tool configuration)
> - `README.md`
> - `requirements.in` (direct dependencies)
> - `requirements.txt` (pinned dependencies)
> - `requirements.freeze.txt` (full environment snapshot)
### Project Setup
The setup cell loads all dependencies, defines project paths, configures training control flags, and includes a Kaggle CLI download helper that automatically fetches the raw dataset if it's not already present locally. All artifact paths follow the versioning system described in the folder structure above. The project root is also added to the Python path, allowing modules in `src/` to be imported.
```{python}
#| code-summary: "Libraries, paths, training flags, Kaggle download helper, and artifact utilities"
# ===============================
# Load libraries
# ===============================
from pathlib import Path
import os, json, re
import numpy as np
import pandas as pd
from datetime import datetime
import gc
import sys
import shutil
import subprocess
import zipfile
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.ticker as mtick
from sklearn.model_selection import train_test_split, KFold, GridSearchCV
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_absolute_error, mean_squared_error
from catboost import CatBoostRegressor
import joblib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import keras_tuner as kt
# ===============================
# Fix macOS / networked FS h5py lock issues
# ===============================
os.environ["HDF5_USE_FILE_LOCKING"] = "FALSE"
# ===============================
# Training control flags
# ===============================
# TRAIN_MODE behavior:
# smoke → quick sanity run on a small subset of the data
# full → normal pipeline execution
# skip → load existing artifacts and evaluate only
# NOTE:
# In practice, running TRAIN_MODE="full" with RETRAIN_* flags set to False
# behaves similarly to "skip": existing artifacts are loaded and evaluated.
# The difference is that "full" still executes the full pipeline logic,
# while "skip" bypasses most training logic entirely.
TRAIN_MODE = "full" # "smoke" | "full" | "skip"
RETRAIN_RIDGE = False
RETRAIN_CATBOOST = False
RETRAIN_KERAS = False
# ===============================
# Paths section
# ===============================
def find_project_root(start: Path) -> Path:
"""
Walk upward until it finds a project marker.
Choose markers that exist in the repo.
"""
markers = [".git", "README.md"]
p = start.resolve()
for parent in [p] + list(p.parents):
if any((parent / m).exists() for m in markers):
return parent
return p
PROJECT_ROOT = find_project_root(Path.cwd())
# Commented out for notebook render, uncomment if you want project root printed
# print("PROJECT_ROOT =", PROJECT_ROOT)
# ----------------------------
# Create project folders
# ----------------------------
DATA_DIR = PROJECT_ROOT / "data"
RAW_DIR = DATA_DIR / "raw"
PROCESSED_DIR = DATA_DIR / "processed"
MODEL_DIR = PROJECT_ROOT / "models"
for d in [RAW_DIR, PROCESSED_DIR, MODEL_DIR]:
d.mkdir(parents=True, exist_ok=True)
# ----------------------------
# Raw/processed paths
# ----------------------------
RAW_CSV = RAW_DIR / "cars.csv"
# Bump this version whenever cleaning or feature-engineering logic changes.
# This prevents stale cached parquet/split artifacts from being silently reused.
FEATURE_PIPELINE_VERSION = "v3"
CLEAN_PARQUET = PROCESSED_DIR / f"cars_cleaned_{FEATURE_PIPELINE_VERSION}.parquet"
FEATURES_PARQUET = PROCESSED_DIR / f"cars_features_{FEATURE_PIPELINE_VERSION}.parquet"
SPLITS_PATH = PROCESSED_DIR / f"splits_indices_{FEATURE_PIPELINE_VERSION}.json"
# ===============================
# Kaggle dataset download helper
# ===============================
# Kaggle dataset configuration
KAGGLE_DATASET_SLUG = "andreinovikov/used-cars-dataset"
RAW_EXPECTED_NAME = "cars.csv"
def _kaggle_cli_present() -> bool:
return shutil.which("kaggle") is not None
def _kaggle_creds_present() -> bool:
"""
Kaggle CLI auth detection.
Supports:
- NEW: env var KAGGLE_API_TOKEN
- NEW: file ~/.kaggle/access_token
- LEGACY: file ~/.kaggle/kaggle.json
- LEGACY: env vars KAGGLE_USERNAME + KAGGLE_KEY
"""
token_env = os.environ.get("KAGGLE_API_TOKEN", "").strip()
token_file = Path.home() / ".kaggle" / "access_token"
legacy_json = Path.home() / ".kaggle" / "kaggle.json"
legacy_user = os.environ.get("KAGGLE_USERNAME", "").strip()
legacy_key = os.environ.get("KAGGLE_KEY", "").strip()
return (
bool(token_env)
or token_file.exists()
or legacy_json.exists()
or (bool(legacy_user) and bool(legacy_key))
)
def ensure_raw_csv(
raw_csv_path: Path,
*,
dataset_slug: str = KAGGLE_DATASET_SLUG,
expected_name: str = RAW_EXPECTED_NAME,
force: bool = False
) -> None:
"""
Ensures data/raw/cars.csv exists.
- If present (and force=False): do nothing.
- If missing (or force=True): downloads via Kaggle CLI into data/raw and ensures filename == expected_name.
"""
raw_dir = raw_csv_path.parent
raw_dir.mkdir(parents=True, exist_ok=True)
if raw_csv_path.exists() and not force:
# Commented out for notebook, uncomment if you want the raw dataset path printed
# print(f"✅ Found raw dataset: {raw_csv_path}")
return
if not dataset_slug:
raise FileNotFoundError(
f"Raw dataset not found at: {raw_csv_path}\n\n"
"Dataset slug is not set.\n"
"Set KAGGLE_DATASET_SLUG = 'owner/dataset-name' or provide dataset_slug=... to ensure_raw_csv().\n\n"
"Manual option:\n"
f" Download from Kaggle and place '{raw_csv_path.name}' into:\n"
f" {raw_dir}/"
)
if not _kaggle_cli_present():
raise FileNotFoundError(
f"Raw dataset not found at: {raw_csv_path}\n\n"
"Kaggle CLI is not installed.\n"
"Install it in this environment with one of:\n"
" uv pip install kaggle\n"
" pip install kaggle\n\n"
"Manual option:\n"
f" Download from Kaggle and place '{raw_csv_path.name}' into:\n"
f" {raw_dir}/"
)
if not _kaggle_creds_present():
raise FileNotFoundError(
f"Raw dataset not found at: {raw_csv_path}\n\n"
"Kaggle credentials not detected.\n\n"
"Use ONE of these (one-time setup):\n"
" A) NEW (recommended): set env var\n"
" export KAGGLE_API_TOKEN='...'\n"
" (Put it in ~/.zshrc if you want it to persist)\n"
" B) NEW: create file\n"
" mkdir -p ~/.kaggle\n"
" printf \"%s\" \"$KAGGLE_API_TOKEN\" > ~/.kaggle/access_token\n"
" chmod 600 ~/.kaggle/access_token\n"
" C) LEGACY: kaggle.json\n"
" ~/.kaggle/kaggle.json (chmod 600)\n"
" D) LEGACY env vars: KAGGLE_USERNAME + KAGGLE_KEY\n\n"
"Then re-run the notebook."
)
print(f"⬇️ Downloading Kaggle dataset: {dataset_slug}")
print(f"📁 Target folder: {raw_dir}")
print(f"📄 Expected CSV: {expected_name}")
# Download zip to RAW_DIR
cmd = [
"kaggle", "datasets", "download",
"-d", dataset_slug,
"-p", str(raw_dir),
"--force",
]
subprocess.run(cmd, check=True)
# Find the newest zip in RAW_DIR
zips = sorted(raw_dir.glob("*.zip"), key=lambda p: p.stat().st_mtime, reverse=True)
if not zips:
raise RuntimeError(
"Kaggle download finished but no .zip was found in data/raw/.\n"
f"Check {raw_dir} for downloaded files."
)
zip_path = zips[0]
print(f"Extracting: {zip_path.name}")
with zipfile.ZipFile(zip_path, "r") as zf:
zf.extractall(raw_dir)
expected_path = raw_dir / expected_name
if expected_path.exists():
if expected_path != raw_csv_path:
expected_path.replace(raw_csv_path)
print(f"✅ Ready: {raw_csv_path}")
return
candidates = sorted(raw_dir.glob("*.csv"), key=lambda p: p.stat().st_mtime, reverse=True)
if not candidates:
files = sorted([p.name for p in raw_dir.glob("*") if p.is_file()])
raise FileNotFoundError(
f"Downloaded and extracted Kaggle dataset, but no CSV was found.\n\n"
f"Files now in {raw_dir}:\n - " + "\n - ".join(files)
)
# If there is exactly one CSV, rename it to expected_name
if len(candidates) == 1:
candidates[0].replace(raw_csv_path)
print(f"✅ Renamed {candidates[0].name} → {expected_name}")
print(f"✅ Ready: {raw_csv_path}")
return
# If multiple CSVs, prefer one containing "cars" in the filename
for c in candidates:
if "cars" in c.name.lower():
c.replace(raw_csv_path)
print(f"✅ Selected {c.name} → {expected_name}")
print(f"✅ Ready: {raw_csv_path}")
return
# Otherwise, fail with a helpful listing
raise FileNotFoundError(
f"Multiple CSVs found in {raw_dir}, but none named '{expected_name}'.\n"
f"Found: {[c.name for c in candidates]}\n\n"
"Fix:\n"
" - Update RAW_EXPECTED_NAME to match the correct CSV inside the zip, OR\n"
" - Manually rename the correct CSV to 'cars.csv' in data/raw/."
)
# Call once to ensure CSV is present
ensure_raw_csv(RAW_CSV, force=False)
# ===============================
# Artifact directories
# ===============================
# Artifact system design:
# Each training run writes model outputs to a timestamped run directory:
# models/<model_name>/run_YYYYMMDD_HHMMSS/
# Artifacts include:
# • trained model files
# • hyperparameters
# • evaluation metrics
# • schema metadata needed for reconstruction
# A "latest" pointer is updated only during full training runs.
# Smoke runs never overwrite production artifacts.
# This design allows:
# • reproducible historical runs
# • safe smoke testing
# • easy rollback to previous models
# ----------------------------
# Ridge artifact paths
# ----------------------------
RIDGE_DIR = MODEL_DIR / "ridge"
RIDGE_DIR.mkdir(parents=True, exist_ok=True)
RIDGE_LATEST_PATH = RIDGE_DIR / "ridge_pipeline.joblib"
RIDGE_PATH = RIDGE_LATEST_PATH
RIDGE_LATEST_RUN_INFO_PATH = RIDGE_DIR / "ridge_run_info.json"
# ----------------------------
# CatBoost artifact paths
# ----------------------------
CATBOOST_DIR = MODEL_DIR / "catboost"
CATBOOST_DIR.mkdir(parents=True, exist_ok=True)
STAGE1_PARAMS_PATH = CATBOOST_DIR / "catboost_stage1_best_params.json"
STAGE1_DONE = CATBOOST_DIR / "catboost_stage1_done.txt"
STAGE2_PARAMS_PATH = CATBOOST_DIR / "catboost_stage2_best_params.json"
STAGE2_DONE = CATBOOST_DIR / "catboost_stage2_done.txt"
FINAL_PARAMS_PATH = CATBOOST_DIR / "catboost_final_params.json"
FINAL_DONE = CATBOOST_DIR / "catboost_done.txt"
CATBOOST_FINAL_PATH = CATBOOST_DIR / "catboost_final.cbm"
FEATURE_COLS_PATH = CATBOOST_DIR / "feature_columns.json"
CATBOOST_LATEST_RUN_INFO_PATH = CATBOOST_DIR / "catboost_run_info.json"
STAGE1_INPROGRESS = CATBOOST_DIR / "catboost_stage1_in_progress.txt"
STAGE2_INPROGRESS = CATBOOST_DIR / "catboost_stage2_in_progress.txt"
FINAL_INPROGRESS = CATBOOST_DIR / "catboost_in_progress.txt"
# ----------------------------
# Keras artifact paths
# ----------------------------
KERAS_DIR = MODEL_DIR / "keras"
KERAS_DIR.mkdir(parents=True, exist_ok=True)
KERAS_RUNS_DIR = KERAS_DIR / "runs"
KERAS_RUNS_DIR.mkdir(parents=True, exist_ok=True)
KERAS_TUNING_HISTORY_PATH = KERAS_DIR / "tuning_history.json"
# Weights-based latest artifacts
KERAS_LATEST_WEIGHTS_PATH = KERAS_DIR / "keras_model.weights.h5"
KERAS_LATEST_RUN_INFO_PATH = KERAS_DIR / "keras_run_info.json"
KERAS_LATEST_TRAIN_MEDIANS_PATH = KERAS_DIR / "keras_train_medians.json"
KERAS_LATEST_NUM_NORM_STATS_PATH = KERAS_DIR / "keras_num_norm_stats.json"
KERAS_LATEST_LOOKUP_VOCABS_PATH = KERAS_DIR / "keras_lookup_vocabs.json"
KERAS_LATEST_HISTORY_PATH = KERAS_DIR / "keras_history.json"
KERAS_LATEST_LOSS_PLOT_PATH = KERAS_DIR / "keras_training_loss.png"
KERAS_LATEST_RMSE_PLOT_PATH = KERAS_DIR / "keras_training_rmse.png"
# ----------------------------
# Metrics artifact paths
# ----------------------------
METRICS_DIR = MODEL_DIR / "metrics"
METRICS_DIR.mkdir(parents=True, exist_ok=True)
METRICS_LATEST_PATH = METRICS_DIR / "metrics_latest.json"
METRICS_PATH = METRICS_LATEST_PATH
# ===============================
# Load or clean dataframes
# ===============================
def load_or_build(path: Path, build_fn, *, label: str):
"""
If `path` exists, load it. Otherwise, run build_fn() and save.
build_fn must return a DataFrame.
"""
if path.exists():
# Commenting out for notebook, but can switch to print for debugging
# print(f"Loading {label} from checkpoint: {path}")
print(f"Loading {label} from checkpoint.")
return pd.read_parquet(path)
# Commenting out for notebook, but can switch to print for debugging
# print(f"Building {label} (checkpoint not found): {path}")
print(f"Building {label} (checkpoint not found).")
df_out = build_fn()
df_out.to_parquet(path, index=False)
# Commenting out for notebook, but can switch to print for debugging
# print(f"Saved {label} checkpoint → {path}")
print(f"Saved {label} checkpoint.")
return df_out
# ===============================
# Functions for model saving
# ===============================
def run_dir_name(run_ts: str, train_mode: str) -> str:
return f"run_{run_ts}_{train_mode}"
def should_update_latest(train_mode: str) -> bool:
# smoke will not update latest
return train_mode == "full"
def atomic_write_bytes(path: Path, data: bytes):
tmp = path.with_suffix(path.suffix + ".tmp")
tmp.write_bytes(data)
tmp.replace(path)
def atomic_write_json(path: Path, obj):
atomic_write_bytes(path, json.dumps(obj, indent=2).encode("utf-8"))
def mark_done(path: Path, text: str = "ok"):
atomic_write_bytes(path, (text + "\n").encode("utf-8"))
def mark_in_progress(path: Path, text: str = "in_progress"):
atomic_write_bytes(path, (text + "\n").encode("utf-8"))
def clear_file(path: Path):
if path.exists():
path.unlink()
def assert_saved_schema_matches(
*,
saved_feature_version,
saved_feature_columns,
current_feature_version,
current_feature_columns,
model_name: str,
):
if saved_feature_version != current_feature_version:
raise ValueError(
f"{model_name}: saved feature version {saved_feature_version!r} "
f"does not match current version {current_feature_version!r}."
)
if list(saved_feature_columns) != list(current_feature_columns):
raise ValueError(
f"{model_name}: saved feature columns do not match current feature columns. "
"This usually means the feature engineering pipeline changed or column order differs."
)
```
```{python}
#| echo: false
# Make project root importable (so src/ can be imported if/when you want)
if str(PROJECT_ROOT) not in sys.path:
sys.path.append(str(PROJECT_ROOT))
```
#### Export Reusable Code to /src
The core cleaning, feature engineering, and API inference functions are exported to `src/pipeline.py` as a standalone module. This allows the same logic to be used outside the notebook — in a CLI training script or as the preprocessing layer for a FastAPI prediction endpoint — without duplicating code. The notebook remains the primary reference version.
```{python}
#| echo: false
# -------------------------------------------------------
# Export preprocessing and inference logic to src/pipeline.py
# -------------------------------------------------------
# The full pipeline is kept directly in this notebook, so
# the rendered HTML portfolio page contains the complete
# implementation in one place.
# For modularity, the same functions are exported to
# src/pipeline.py, which serves two purposes:
# 1. Batch training: build_cleaned_df() and build_features_df()
# 2. API inference: prepare_for_prediction() — a single-entry
# transform that applies identical normalization and feature
# engineering for real-time predictions via FastAPI.
# The notebook remains the primary reference version.
# NOTE: This does not change notebook execution logic; it just keeps a reusable copy in src/.
# NOTE: If cleaning or feature-engineering logic changes, bump FEATURE_PIPELINE_VERSION.
# Also keep the exported src/pipeline.py copy aligned with the notebook version.
PIPELINE_PY = PROJECT_ROOT / "src" / "pipeline.py"
PIPELINE_PY.parent.mkdir(parents=True, exist_ok=True)
pipeline_code = r'''
from __future__ import annotations
import re
import json
import numpy as np
import pandas as pd
from pathlib import Path
# ===============================
# Constants
# ===============================
REFERENCE_YEAR = 2023 # The dataset ends at the beginning of 2023
TEXT_COLUMNS = [
"manufacturer", "model", "drivetrain", "fuel_type",
"engine", "transmission", "exterior_color", "interior_color",
]
DRIVETRAIN_MAP = {
"all wheel drive": "awd",
"awd": "awd",
"four wheel drive": "4wd",
"4wd": "4wd",
"front wheel drive": "fwd",
"fwd": "fwd",
"rear wheel drive": "rwd",
"rwd": "rwd",
}
LUXURY_BRANDS = {
"acura", "alfa romeo", "aston martin", "audi", "bentley",
"bmw", "bugatti", "cadillac", "ferrari", "genesis",
"infiniti", "jaguar", "lamborghini", "land rover", "lexus",
"lincoln", "lotus", "maserati", "mclaren", "mercedes benz",
"polestar", "porsche", "rolls royce", "tesla", "volvo",
}
# ===============================
# Text normalization
# ===============================
def normalize_text_basic(s: pd.Series) -> pd.Series:
"""Normalize a pandas Series of strings: lowercase, strip,
replace hyphens/slashes with spaces, pad &, collapse whitespace."""
return (
s.astype(str)
.str.strip()
.str.lower()
.str.replace(r'[-/]', ' ', regex=True)
.str.replace(r'&', ' & ', regex=False)
.str.replace(r'\s+', ' ', regex=True)
.str.strip()
)
def normalize_text_single(s: str) -> str:
"""Normalize a single string. Same logic as normalize_text_basic
but for scalar values (used by the API inference path)."""
s = str(s).strip().lower()
s = re.sub(r'[-/]', ' ', s)
s = s.replace('&', ' & ')
s = re.sub(r'\s+', ' ', s)
return s.strip()
# ===============================
# Engine parsing
# ===============================
def parse_engine(engine: str) -> pd.Series:
"""Extract structured features from a pre-normalized engine string."""
s = str(engine)
m_l = re.search(r"(\d(?:\.\d)?)\s*l\b", s)
liters = float(m_l.group(1)) if m_l else np.nan
m_c = re.search(r"\b([ivh])\s*(\d+)\b", s)
if m_c:
layout = m_c.group(1)
cylinders = int(m_c.group(2))
else:
layout = np.nan
cylinders = np.nan
turbo = int(("turbo" in s) or ("twin turbo" in s) or ("supercharg" in s))
hybrid = int(
("hybrid" in s) or
("gas electric" in s) or
("phev" in s) or
("plug in" in s) or
("electric" in s and "gas" in s)
)
return pd.Series({
"engine_liters": liters,
"engine_cylinders": cylinders,
"engine_layout": layout,
"engine_turbo": turbo,
"engine_hybrid": hybrid,
})
# ===============================
# Transmission parsing
# ===============================
def normalize_transmission(t: str) -> str:
if pd.isna(t):
return "unknown"
t = str(t)
t = t.replace("a t", "automatic")
t = t.replace("auto", "automatic")
return t
def transmission_type(t: str) -> str:
t = normalize_transmission(t)
if t == "unknown" or "not specified" in t:
return "unknown"
if "manual" in t:
return "manual"
if ("cvt" in t) or ("variable" in t) or ("ivt" in t) or ("ecvt" in t):
return "cvt"
return "automatic"
def transmission_gears(t: str) -> float:
t = normalize_transmission(t)
match = re.search(r"(\d+)\s?speed", t)
return int(match.group(1)) if match else np.nan
# ===============================
# Color collapsing
# ===============================
def base_color(c: str) -> str:
c = str(c)
if "black" in c or "ebony" in c:
return "black"
if "blue" in c or "deep cerulean" in c:
return "blue"
if "red" in c or "scarlet ember" in c or "maroon" in c or "dark cherry" in c:
return "red"
if "green" in c or "army green" in c or "f8 green" in c or "dark moss" in c or "sarge green clearcoat" in c:
return "green"
if "white" in c or "pearl" in c or "whiite" in c:
return "white"
if "gray" in c or "silver" in c or "grey" in c or "gun" in c or "steel" in c or "magnetic" in c or " metal " in c or "carbon" in c or "granite" in c or "graphite" in c:
return "gray"
return "other"
def interior_color_base(c: str) -> str:
c = str(c)
if "black" in c or "ebony" in c or "jet" in c:
return "black"
if "red" in c:
return "red"
if "gray" in c or "grey" in c or "graphite" in c or "charcoal" in c or "shale" in c or "steel" in c or "pewter" in c or "slate" in c:
return "gray"
if "brown" in c or "cappuccino" in c or "mocha" in c or "espresso" in c or "cocoa" in c or "coffee" in c or "nutmeg" in c or "walnut" in c or "chestnut" in c or "hazelnut" in c or "roast" in c:
return "brown"
if "beige" in c or "tan" in c or "taupe" in c or "sand" in c or "ash" in c or "camel" in c or "cognac" in c or "parchment" in c or "stone" in c or "wheat" in c or "sandstone" in c or "cement" in c or "almond" in c or "blond" in c or "neutral" in c:
return "beige"
if "white" in c or "ivory" in c or "cream" in c:
return "white"
return "other"
# ===============================
# Batch pipeline: build_cleaned_df
# ===============================
def build_cleaned_df(raw_csv_path) -> pd.DataFrame:
"""Load raw CSV, compute mpg_avg, drop nulls, cast binary flags,
normalize text columns, map drivetrain."""
df_local = pd.read_csv(raw_csv_path)
df_cleaned = df_local.copy()
mpg_split = df_cleaned["mpg"].astype(str).str.split("-", expand=True)
df_cleaned["mpg_avg"] = (
mpg_split
.apply(pd.to_numeric, errors="coerce")
.mean(axis=1)
)
df_cleaned = df_cleaned.drop(columns="mpg")
df_cleaned = df_cleaned.dropna().reset_index(drop=True)
bin_cols = ["accidents_or_damage", "one_owner", "personal_use_only"]
for c in bin_cols:
if c in df_cleaned.columns:
df_cleaned[c] = df_cleaned[c].round().astype("Int64")
for col in TEXT_COLUMNS:
df_cleaned[col] = normalize_text_basic(df_cleaned[col])
df_cleaned["drivetrain"] = df_cleaned["drivetrain"].replace(DRIVETRAIN_MAP)
return df_cleaned
# ===============================
# Batch pipeline: build_features_df
# ===============================
def build_features_df(df_cleaned: pd.DataFrame) -> pd.DataFrame:
"""Transform cleaned dataframe into model-ready features + target."""
y = np.log1p(df_cleaned["price"])
X = df_cleaned.drop(columns=["price", "seller_name"], errors="ignore").copy()
# Age and mileage per year
X["age"] = REFERENCE_YEAR - X["year"]
X["age_for_mpy"] = X["age"].clip(lower=1)
X["mileage_per_year"] = X["mileage"] / X["age_for_mpy"]
X = X.drop(columns=["age_for_mpy", "year"])
# Luxury brand flag + interaction
X["is_luxury_brand"] = X["manufacturer"].isin(LUXURY_BRANDS).astype("int64")
X["luxury_age_interaction"] = X["is_luxury_brand"] * X["age"]
# Parse engine
engine_features = X["engine"].apply(parse_engine)
X = pd.concat([X.drop(columns=["engine"]), engine_features], axis=1)
X["engine_layout"] = X["engine_layout"].fillna("unknown")
# Parse transmission
X["transmission_clean"] = X["transmission"].apply(transmission_type)
X["transmission_gears"] = X["transmission"].apply(transmission_gears)
X = X.drop(columns=["transmission"])
X["transmission_gears_missing"] = X["transmission_gears"].isna().astype(int)
# Collapse colors
X["exterior_color_base"] = X["exterior_color"].apply(base_color)
X = X.drop(columns=["exterior_color"])
X["interior_color_base"] = X["interior_color"].apply(interior_color_base)
X = X.drop(columns=["interior_color"])
# Type casts
numeric_casts = {
"age": "int64",
"mileage_per_year": "float64",
"engine_liters": "float64",
"engine_cylinders": "float64",
"transmission_gears": "float64",
"engine_turbo": "int64",
"engine_hybrid": "int64",
"transmission_gears_missing": "int64",
}
for col, dtype in numeric_casts.items():
if col in X.columns:
X[col] = X[col].astype(dtype)
for col in ["engine_layout", "transmission_clean", "exterior_color_base", "interior_color_base"]:
if col in X.columns:
X[col] = X[col].astype("object")
features_df = X.copy()
features_df["target_log1p_price"] = y.values
return features_df
# ===============================
# API inference: prepare_for_prediction
# ===============================
def prepare_for_prediction(
raw_input: dict,
feature_columns: list[str],
) -> pd.DataFrame:
"""Transform a single raw API input dict into a feature DataFrame
matching the training schema.
Parameters
----------
raw_input : dict
Raw vehicle attributes from the API request. Expected keys:
manufacturer, model, year, mileage, engine, transmission,
drivetrain, fuel_type, exterior_color, interior_color,
mpg (string like "30-32" or numeric), price_drop,
seller_rating, driver_rating, driver_reviews_num,
accidents_or_damage, one_owner, personal_use_only
feature_columns : list[str]
Ordered list of feature column names from training.
Used to ensure the output matches the model's expected schema.
Returns
-------
pd.DataFrame
Single-row DataFrame with columns in feature_columns order,
ready for model.predict().
"""
df = pd.DataFrame([raw_input])
# --- MPG: handle "30-32" string or plain numeric ---
if "mpg" in df.columns:
mpg_split = df["mpg"].astype(str).str.split("-", expand=True)
df["mpg_avg"] = (
mpg_split
.apply(pd.to_numeric, errors="coerce")
.mean(axis=1)
)
df = df.drop(columns=["mpg"])
# --- Binary flags ---
bin_cols = ["accidents_or_damage", "one_owner", "personal_use_only"]
for c in bin_cols:
if c in df.columns:
df[c] = pd.to_numeric(df[c], errors="coerce").round().astype("Int64")
# --- Normalize text ---
for col in TEXT_COLUMNS:
if col in df.columns:
df[col] = df[col].astype(str).apply(normalize_text_single)
# --- Drivetrain mapping ---
if "drivetrain" in df.columns:
df["drivetrain"] = df["drivetrain"].replace(DRIVETRAIN_MAP)
# --- Drop seller_name if present ---
df = df.drop(columns=["seller_name"], errors="ignore")
# --- Age and mileage per year ---
df["age"] = REFERENCE_YEAR - df["year"].astype(int)
age_for_mpy = df["age"].clip(lower=1)
df["mileage_per_year"] = df["mileage"].astype(float) / age_for_mpy
df = df.drop(columns=["year"], errors="ignore")
# --- Luxury brand flag + interaction ---
df["is_luxury_brand"] = df["manufacturer"].isin(LUXURY_BRANDS).astype("int64")
df["luxury_age_interaction"] = df["is_luxury_brand"] * df["age"]
# --- Parse engine ---
engine_parsed = parse_engine(df["engine"].iloc[0])
df[engine_parsed.index] = engine_parsed.values
df = df.drop(columns=["engine"])
df["engine_layout"] = df["engine_layout"].fillna("unknown")
# --- Parse transmission ---
trans_val = df["transmission"].iloc[0]
df["transmission_clean"] = transmission_type(trans_val)
df["transmission_gears"] = transmission_gears(trans_val)
df = df.drop(columns=["transmission"])
df["transmission_gears_missing"] = int(pd.isna(df["transmission_gears"].iloc[0]))
# --- Collapse colors ---
df["exterior_color_base"] = base_color(df["exterior_color"].iloc[0])
df = df.drop(columns=["exterior_color"])
df["interior_color_base"] = interior_color_base(df["interior_color"].iloc[0])
df = df.drop(columns=["interior_color"])
# --- Type casts ---
numeric_casts = {
"age": "int64",
"mileage_per_year": "float64",
"engine_liters": "float64",
"engine_cylinders": "float64",
"transmission_gears": "float64",
"engine_turbo": "int64",
"engine_hybrid": "int64",
"transmission_gears_missing": "int64",
}
for col, dtype in numeric_casts.items():
if col in df.columns:
df[col] = df[col].astype(dtype)
for col in ["engine_layout", "transmission_clean", "exterior_color_base", "interior_color_base"]:
if col in df.columns:
df[col] = df[col].astype("object")
# --- Reorder columns to match training schema ---
df = df[feature_columns]
return df
'''
PIPELINE_PY.write_text(pipeline_code, encoding="utf-8");
# Commented out for notebook render
# print("✅ Wrote:", PIPELINE_PY)
```
## Methodology
### Data Cleaning
#### Philosophy
Because the dataset is large (~762k rows), the project begins by restricting to fully observed records. This simplifies early feature engineering while retaining more than enough data for training (243,500 rows after cleaning). Later feature engineering steps (e.g., parsing engine specs from free text) reintroduce sparse missing values, which are handled downstream using missingness indicators and model-specific imputations.
This is a deliberate choice: rather than imputing hundreds of thousands of missing values before understanding the data, the pipeline starts clean and adds complexity only where it improves the signal.
#### Key Cleaning Decisions
- **MPG field**: The raw `mpg` column contained hyphenated ranges (e.g., "39-38"). These were split and averaged into a single `mpg_avg` numeric feature.
- **Binary flags**: `accidents_or_damage`, `one_owner`, and `personal_use_only` were cast to integer binary columns.
- **Dropped rows with nulls**: After computing `mpg_avg`, rows with any remaining missing values were dropped. This reduced the dataset from ~762k to ~243k rows — a substantial reduction, but the remaining dataset is still large enough to support reliable modeling.
- **Log-transformed target**: Raw prices are heavily right-skewed (median ~$27k, long tail past $100k). A `log1p` transformation stabilizes variance and allows models to optimize on relative rather than absolute errors. Predictions are converted back to dollars via `expm1` at evaluation time.
#### Import Raw and Display Original Data
The raw dataset contains 762,091 listings across 20 columns. Missing values are concentrated in a few columns — `price_drop` (46% of rows missing), `seller_rating` (28%), and `mpg` (19%):
```{python}
#| code-summary: "Load raw CSV and display column info"
df_raw = pd.read_csv(RAW_CSV)
df_raw.info()
```
```{python}
#| code-summary: "Missing values by column"
display(df_raw.isnull().sum().sort_values(ascending=False))
```
A sample of the raw data shows the heterogeneous text formatting in columns like `engine` and `transmission` — these will be parsed into structured features during feature engineering:
```{python}
#| code-summary: "Raw data preview"
#| column: page
display(df_raw.head())
```
#### Clean Dataset, Save to Parquet, and Display Cleaned Dataframe
The cleaning function computes `mpg_avg`, drops incomplete rows, and casts binary flags to integers. Results are cached as a Parquet checkpoint.
```{python}
#| code-summary: "Cleaning function: compute mpg_avg, drop nulls, cast binary flags"
def normalize_text_basic(s: pd.Series) -> pd.Series:
"""Normalize a pandas Series of strings: lowercase, strip,
replace hyphens/slashes with spaces, pad &, collapse whitespace."""
return (
s.astype(str)
.str.strip()
.str.lower()
.str.replace(r'[-/]', ' ', regex=True) # hyphens & slashes → space
.str.replace(r'&', ' & ', regex=False) # pad & so "x&y" → "x & y"
.str.replace(r'\s+', ' ', regex=True) # collapse runs of whitespace
.str.strip() # trim again after replacements
)
DRIVETRAIN_MAP = {
"all wheel drive": "awd",
"awd": "awd",
"four wheel drive": "4wd",
"4wd": "4wd",
"front wheel drive": "fwd",
"fwd": "fwd",
"rear wheel drive": "rwd",
"rwd": "rwd",
}
def build_cleaned_df():
df_local = pd.read_csv(RAW_CSV)
df_cleaned = df_local.copy()
mpg_split = df_cleaned["mpg"].astype(str).str.split("-", expand=True)
df_cleaned["mpg_avg"] = (
mpg_split
.apply(pd.to_numeric, errors="coerce")
.mean(axis=1)
)
df_cleaned = df_cleaned.drop(columns="mpg")
# For this project, it intentionally starts with a fully observed subset
# of the dataset to simplify early feature engineering and modeling.
# The dataset is large enough that dropping incomplete rows does not
# materially reduce training data.
# Some later feature engineering steps reintroduced sparse missing
# values (e.g., parsed engine specs), which are handled downstream
# using missingness indicators and model-specific imputations.
df_cleaned = df_cleaned.dropna().reset_index(drop=True)
bin_cols = ["accidents_or_damage", "one_owner", "personal_use_only"]
for c in bin_cols:
if c in df_cleaned.columns:
df_cleaned[c] = df_cleaned[c].round().astype("Int64")
TEXT_COLUMNS = [
"manufacturer", "model", "drivetrain", "fuel_type",
"engine", "transmission", "exterior_color", "interior_color"]
for col in TEXT_COLUMNS:
df_cleaned[col] = normalize_text_basic(df_cleaned[col])
df_cleaned["drivetrain"] = df_cleaned["drivetrain"].replace(DRIVETRAIN_MAP)
return df_cleaned
df_cleaned = load_or_build(CLEAN_PARQUET, build_cleaned_df, label="cleaned dataset")
```
After cleaning, the dataset has 243,500 fully observed rows with no missing values:
```{python}
#| code-summary: "Cleaned data preview"
#| column: page
display(df_cleaned.head())
```
```{python}
#| code-summary: "Confirm zero missing values after cleaning"
display(df_cleaned.isnull().sum())
```
### Exploratory Data Analysis
> NOTE: All exploration below is performed on the cleaned dataset, before feature engineering.
Column cardinality ranges from 2 (binary flags) to 104,507 (mileage), revealing which features will need dimensionality reduction:
```{python}
#| code-summary: "Unique value counts and dtypes per column"
summary = (
df_cleaned
.nunique()
.rename("n_unique")
.to_frame()
.join(df_cleaned.dtypes.rename("dtype"))
.sort_values("n_unique", ascending=False)
)
display(summary.head(20))
```
Key dataset dimensions:
```{python}
#| code-summary: "Dataset summary statistics"
n_entries = len(df_cleaned)
n_manu = df_cleaned["manufacturer"].nunique()
n_model = df_cleaned[["manufacturer", "model"]].drop_duplicates().shape[0]
n_engine = df_cleaned["engine"].nunique()
year_min = df_cleaned["year"].min()
year_max = df_cleaned["year"].max()
most_year = int(df_cleaned["year"].value_counts().idxmax())
print(f"Number of entries: {n_entries:,}")
print(f"Unique manufacturers: {n_manu:,}")
print(f"Unique make/models: {n_model:,}")
print(f"Unique engine entries: {n_engine:,}")
print(f"Oldest year: {year_min}, newest year: {year_max}")
print(f"Most common year: {most_year}")
```
Price distribution summary — the mean ($30,680) is pulled well above the median ($27,500) by the right tail:
```{python}
#| code-summary: "Price distribution statistics"
desc = df_cleaned["price"].describe()
formatted = desc.astype(object)
formatted.loc["count"] = f"{int(desc.loc['count']):,}"
formatted.loc[formatted.index != "count"] = formatted.loc[formatted.index != "count"].map(lambda x: f"${x:,.2f}")
display(formatted)
```
#### Exploratory Graphs
```{python}
#| code-summary: "Price distribution (full range)"
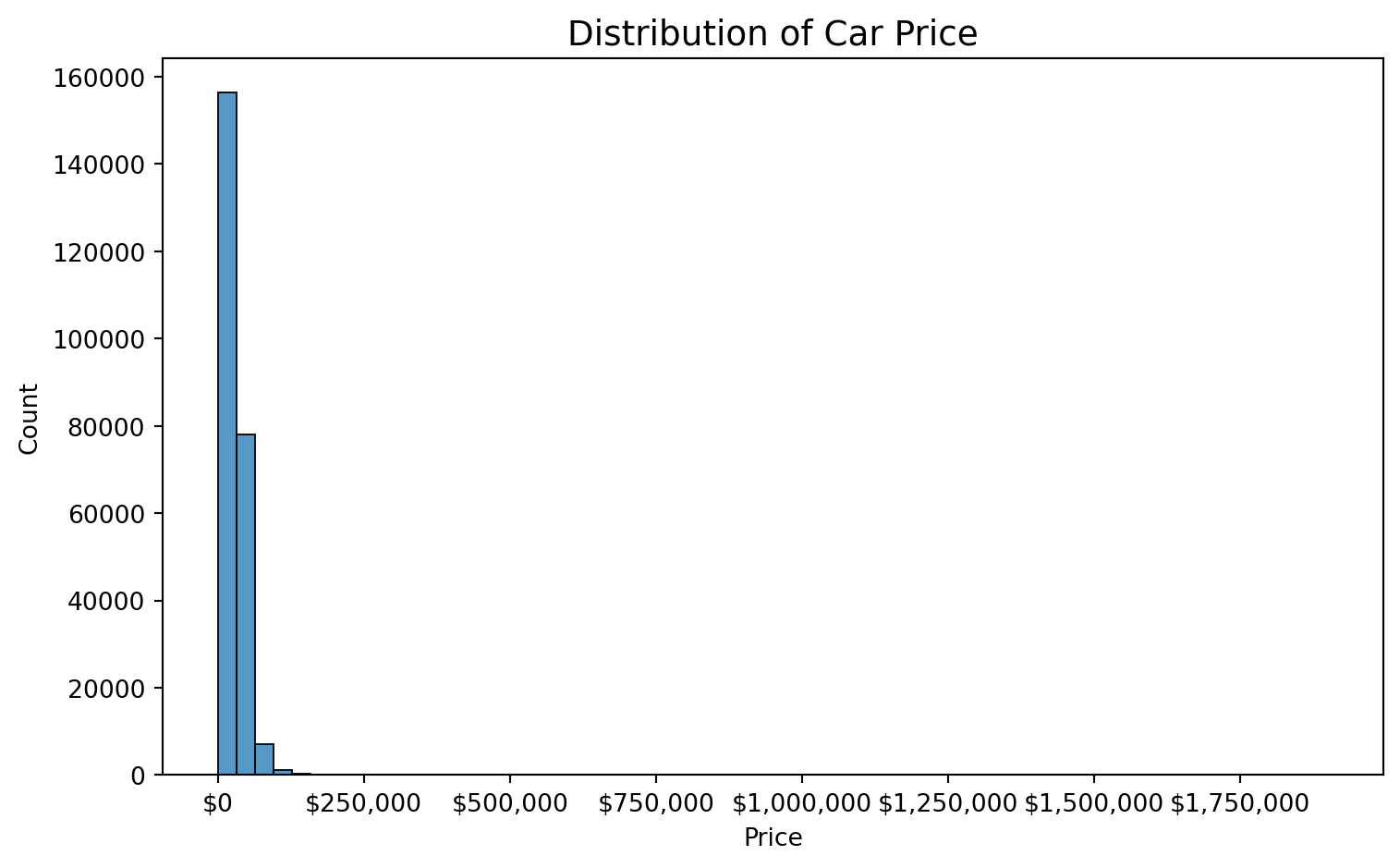
#| fig-cap: "The vast majority of listings fall below $100k, with a long tail extending past $1M — motivating the log-transform of the target variable."
fig, ax = plt.subplots(figsize=(8, 5))
sns.histplot(df_cleaned["price"], bins=60, ax=ax)
ax.xaxis.set_major_formatter(mtick.StrMethodFormatter("${x:,.0f}"))
ax.set_title("Distribution of Car Price", fontsize=14)
ax.set_xlabel("Price")
plt.tight_layout()
plt.show()
```
```{python}
#| code-summary: "Price distribution (1–99% clipped)"
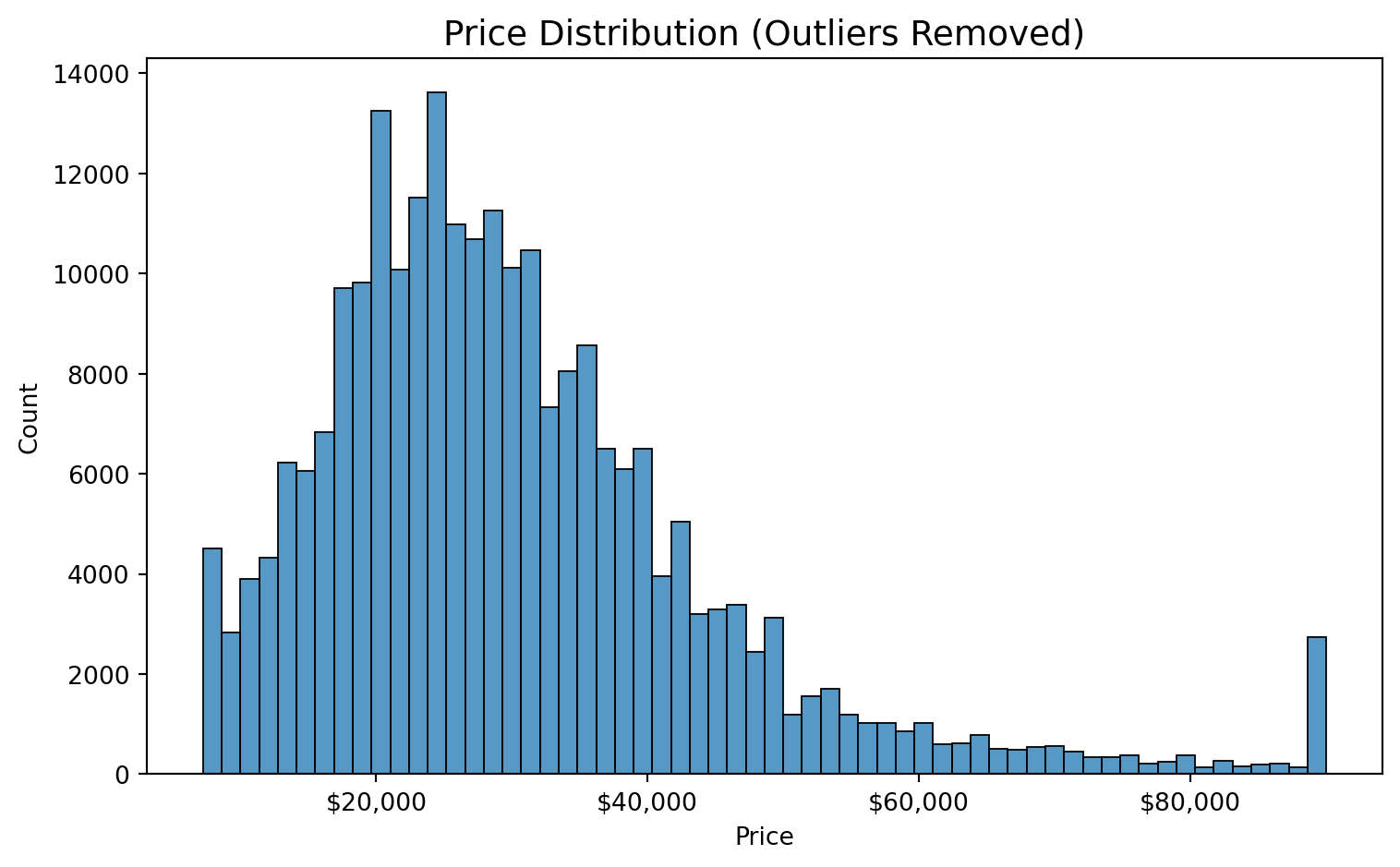
#| fig-cap: "With outliers removed, the distribution is right-skewed but roughly unimodal, peaking around $22k–$25k."
low, high = df_cleaned["price"].quantile([0.01, 0.99])
price_filtered = df_cleaned["price"].clip(lower=low, upper=high)
fig, ax = plt.subplots(figsize=(8, 5))
sns.histplot(price_filtered, bins=60, ax=ax)
ax.xaxis.set_major_formatter(mtick.StrMethodFormatter("${x:,.0f}"))
ax.set_title("Price Distribution (Outliers Removed)", fontsize=14)
ax.set_xlabel("Price")
plt.tight_layout()
plt.show()
```
```{python}
#| code-summary: "Manufacturer frequency"
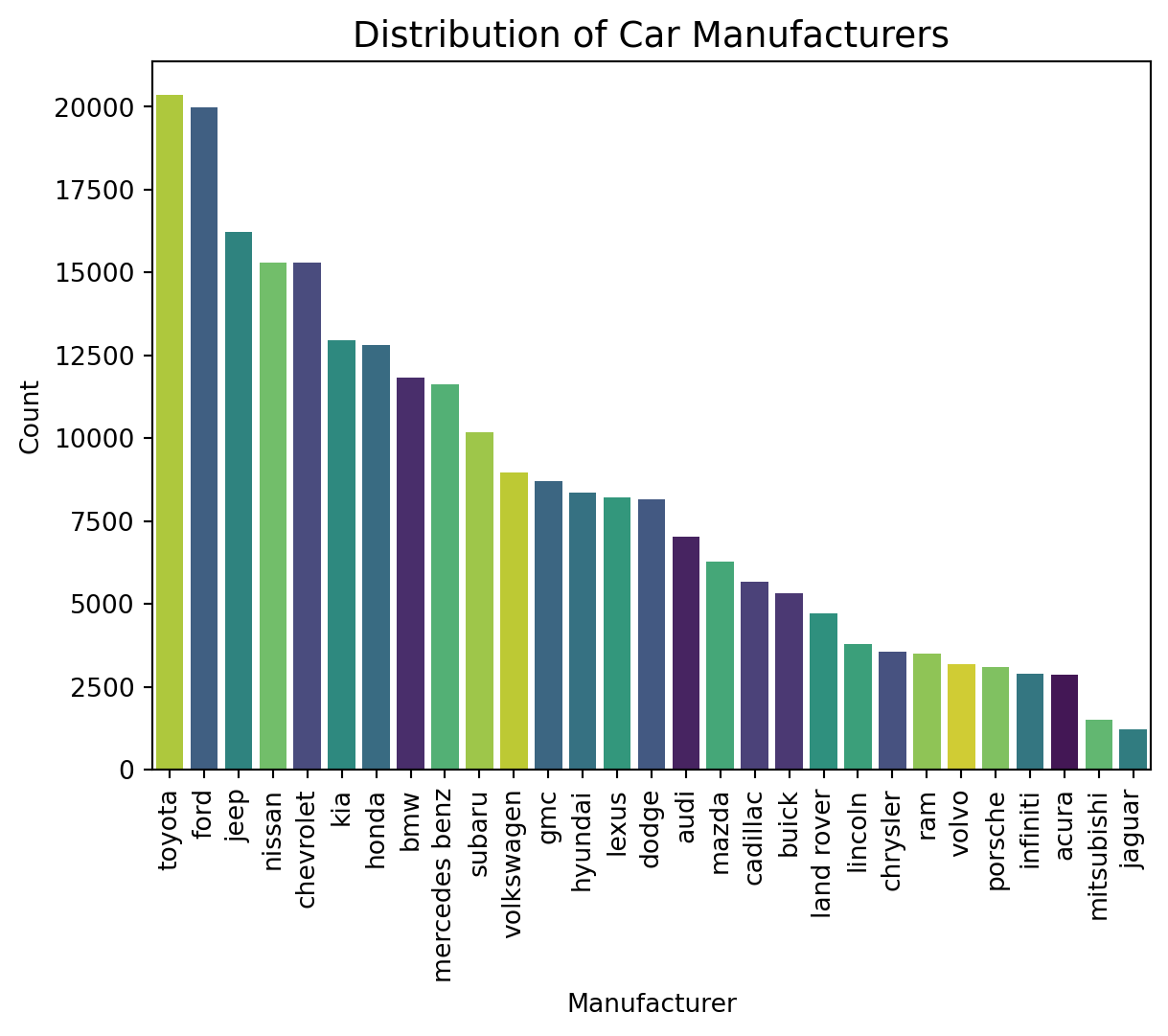
#| fig-cap: "Toyota, Ford, and Jeep dominate the dataset. Rare brands like Jaguar and Mitsubishi have under 3,000 listings."
order = df_cleaned["manufacturer"].value_counts(ascending=False).index
sns.countplot(x="manufacturer", data=df_cleaned, hue="manufacturer", order=order, palette="viridis")
plt.title("Distribution of Car Manufacturers", fontsize=14)
plt.xlabel("Manufacturer")
plt.ylabel("Count")
plt.xticks(rotation=90)
plt.show()
```
```{python}
#| code-summary: "Year distribution"
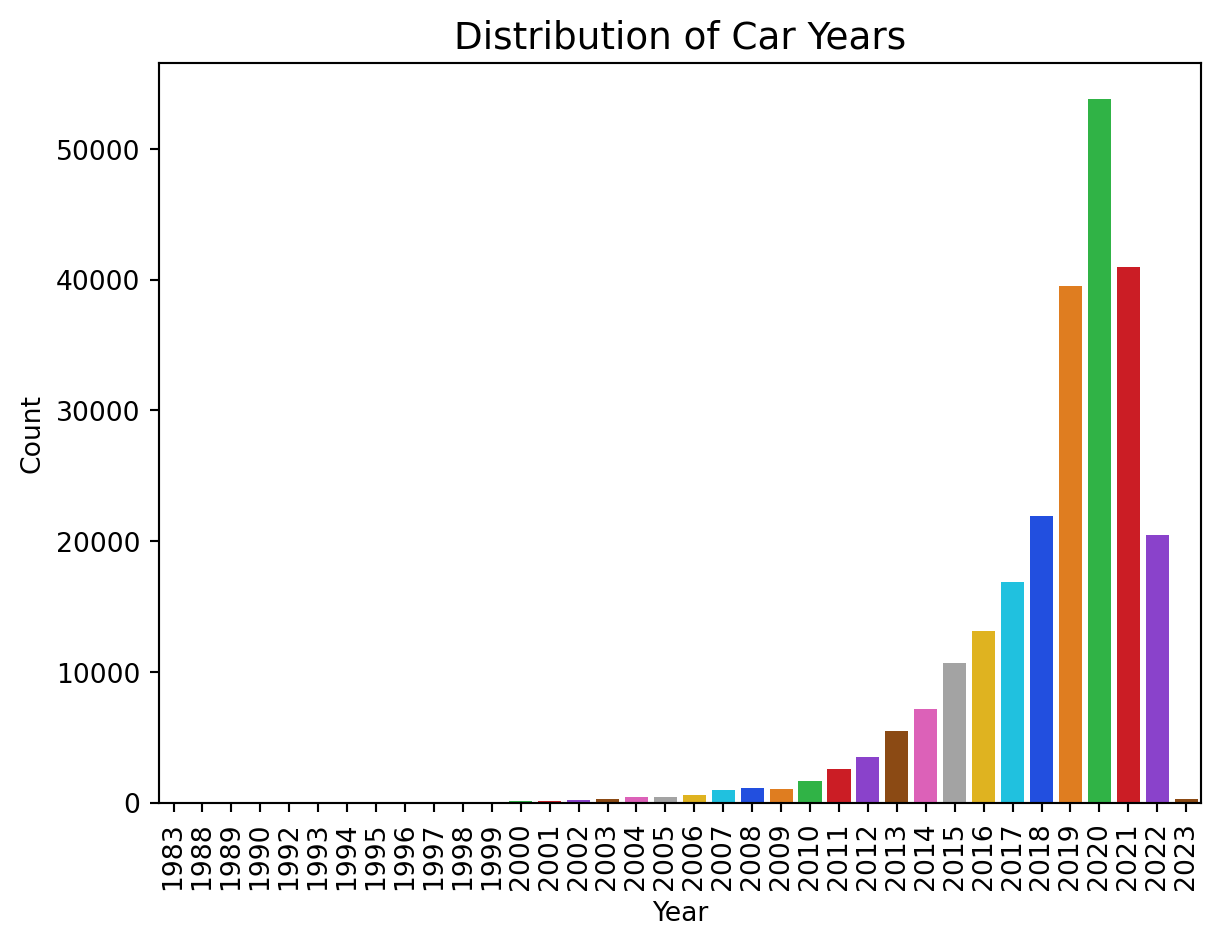
#| fig-cap: "Listings grow sharply from 2010 onward, with 2020 as the most common model year. Pre-2010 vehicles are sparse."
sns.countplot(x="year", data=df_cleaned, hue="year", palette="bright", legend=False)
plt.title("Distribution of Car Years", fontsize=14)
plt.xlabel("Year")
plt.ylabel("Count")
plt.xticks(rotation=90)
plt.show()
```
```{python}
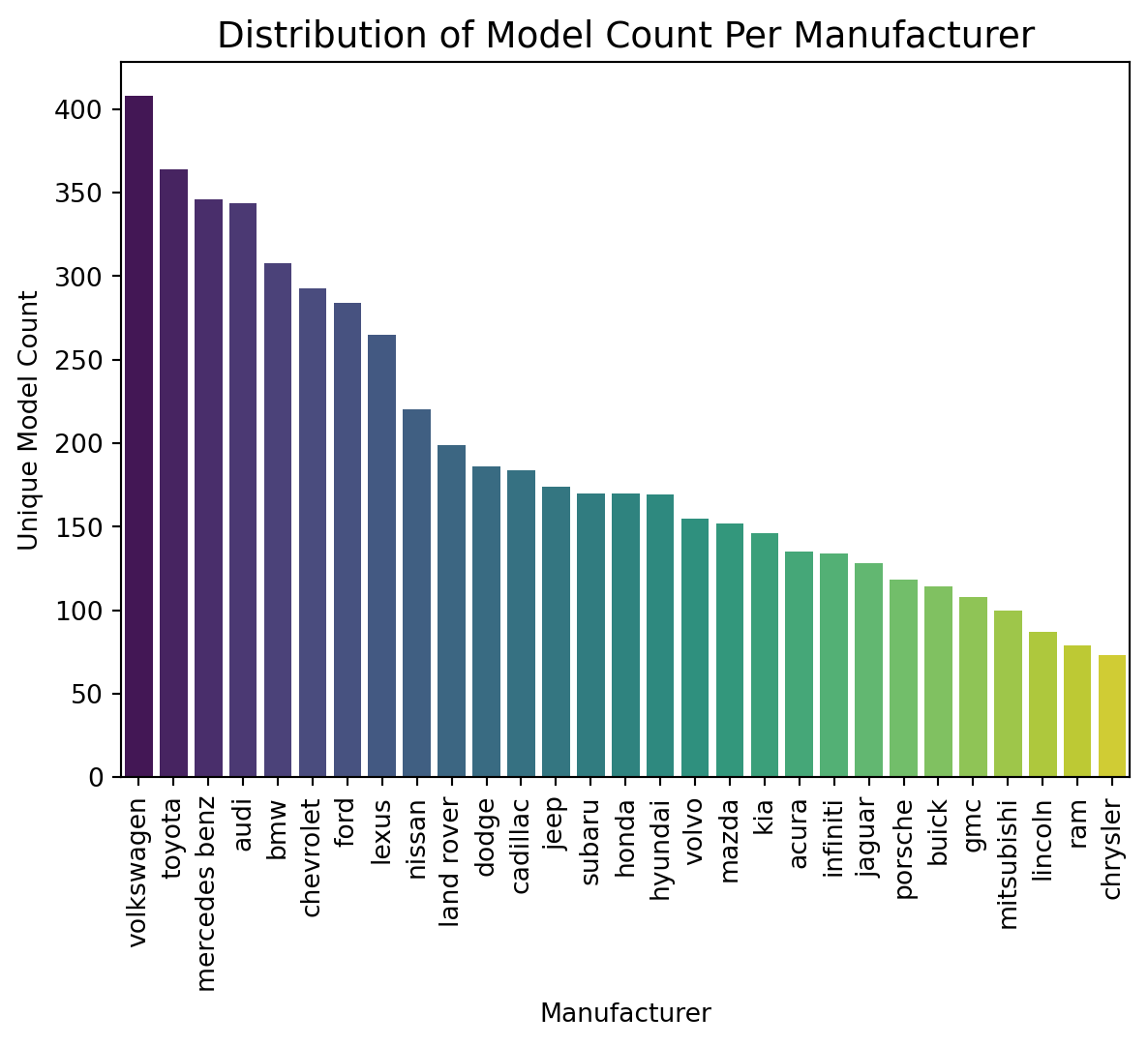
#| code-summary: "Unique model count per manufacturer"
#| fig-cap: "Volkswagen and Toyota each have 350+ unique model names — a major source of categorical cardinality."
df_models = (
df_cleaned.groupby("manufacturer")["model"]
.nunique()
.sort_values(ascending=False)
.reset_index(name="unique_model_count")
)
sns.barplot(
data=df_models,
x="manufacturer",
y="unique_model_count",
hue="manufacturer",
palette="viridis"
)
plt.xticks(rotation=90)
plt.ylabel("Unique Model Count")
plt.xlabel("Manufacturer")
plt.title("Distribution of Model Count Per Manufacturer", fontsize=14)
plt.show()
```
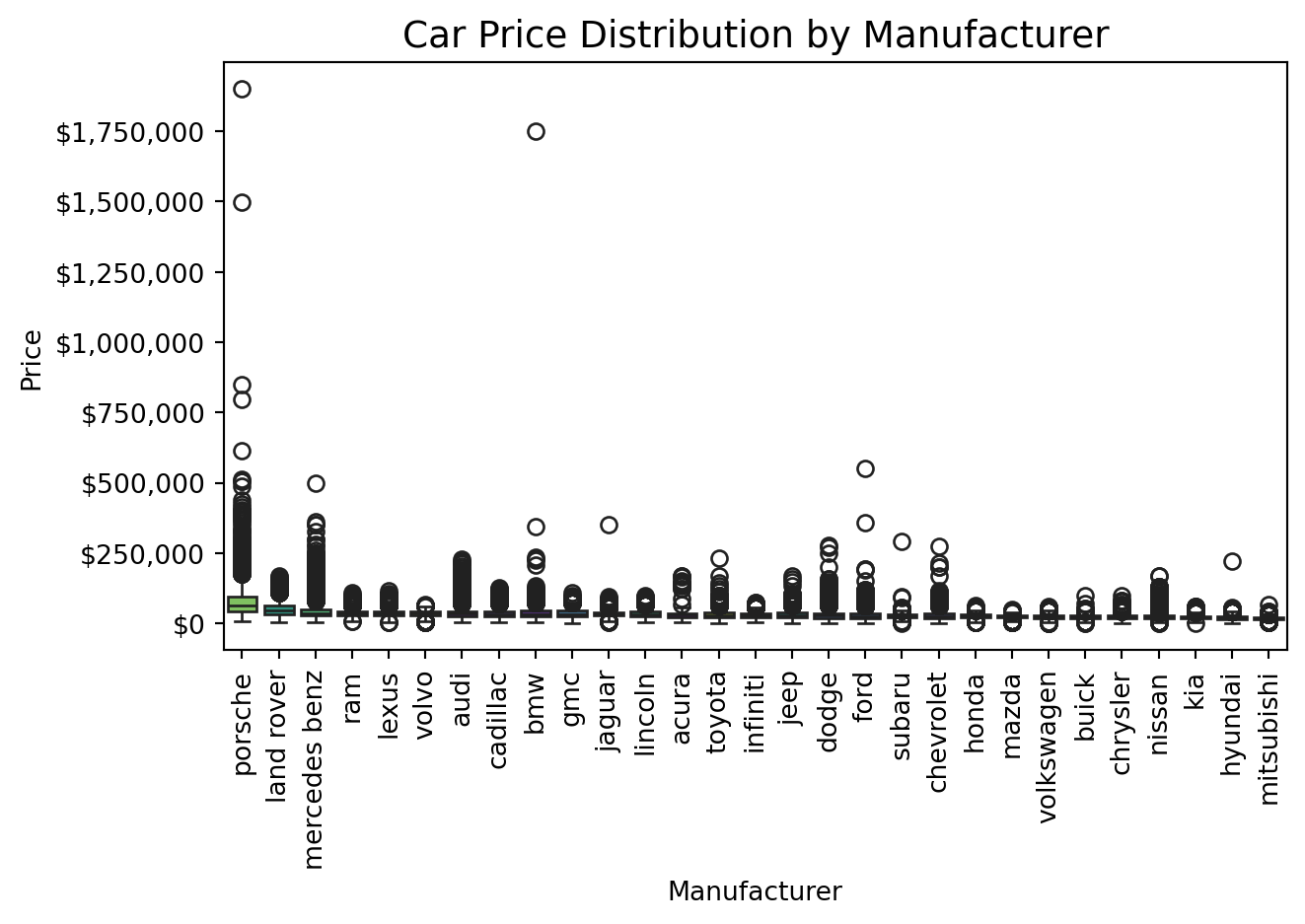
```{python}
#| code-summary: "Price by manufacturer (full range)"
#| fig-cap: "Porsche and BMW show extreme outliers above $1M. Most brands cluster below $100k."
order = (
df_cleaned
.groupby("manufacturer")["price"]
.median()
.sort_values(ascending=False)
.index
)
sns.boxplot(data=df_cleaned, x="manufacturer", y="price", order=order, palette="viridis", hue="manufacturer")
plt.title("Car Price Distribution by Manufacturer", fontsize=14)
plt.xlabel("Manufacturer")
plt.ylabel("Price")
plt.gca().yaxis.set_major_formatter(mtick.StrMethodFormatter("${x:,.0f}"))
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
```
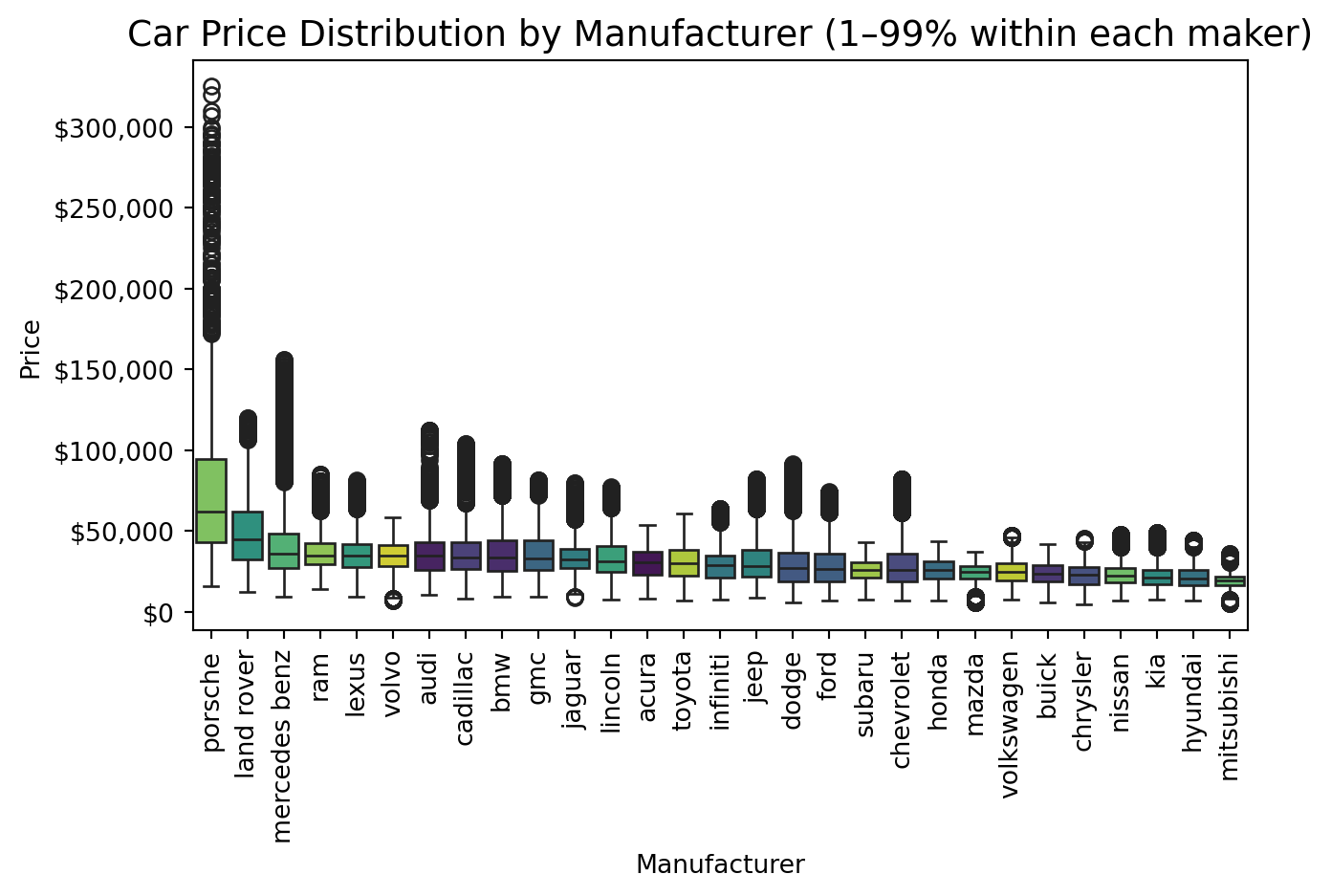
```{python}
#| code-summary: "Price by manufacturer (1–99% within each brand)"
#| fig-cap: "After removing extreme outliers within each brand, luxury manufacturers still show substantially wider price ranges than mass-market brands."
def filter_group(g):
low, high = g["price"].quantile([0.01, 0.99])
return g[g["price"].between(low, high)]
df_cleaned_filtered = (
df_cleaned
.groupby("manufacturer", group_keys=False)[["manufacturer", "price"]]
.apply(filter_group)
)
order = (
df_cleaned_filtered
.groupby("manufacturer")["price"]
.median()
.sort_values(ascending=False)
.index
)
sns.boxplot(data=df_cleaned_filtered, x="manufacturer", y="price", order=order, palette="viridis", hue="manufacturer")
plt.title("Car Price Distribution by Manufacturer (1–99% within each maker)", fontsize=14)
plt.xlabel("Manufacturer")
plt.ylabel("Price")
plt.gca().yaxis.set_major_formatter(mtick.StrMethodFormatter("${x:,.0f}"))
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
```
#### EDA Findings
Several patterns in the exploratory analysis directly informed modeling decisions:
**Price distribution is heavily right-skewed.** The raw price histogram shows the vast majority of vehicles clustered below $100k, with a long tail extending past $1M. This motivated the log-transform of the target variable and the dual-reporting strategy (full vs. clipped metrics). Without the log-transform, models would disproportionately optimize for expensive outliers at the expense of typical vehicles.
**Toyota, Ford, and Jeep dominate the dataset.** The manufacturer distribution is imbalanced — the top 3 brands each have 15,000+ listings, while brands like Jaguar and Mitsubishi have fewer than 3,000. This imbalance means model performance will naturally be better for well-represented brands, while rare-brand predictions carry more uncertainty.
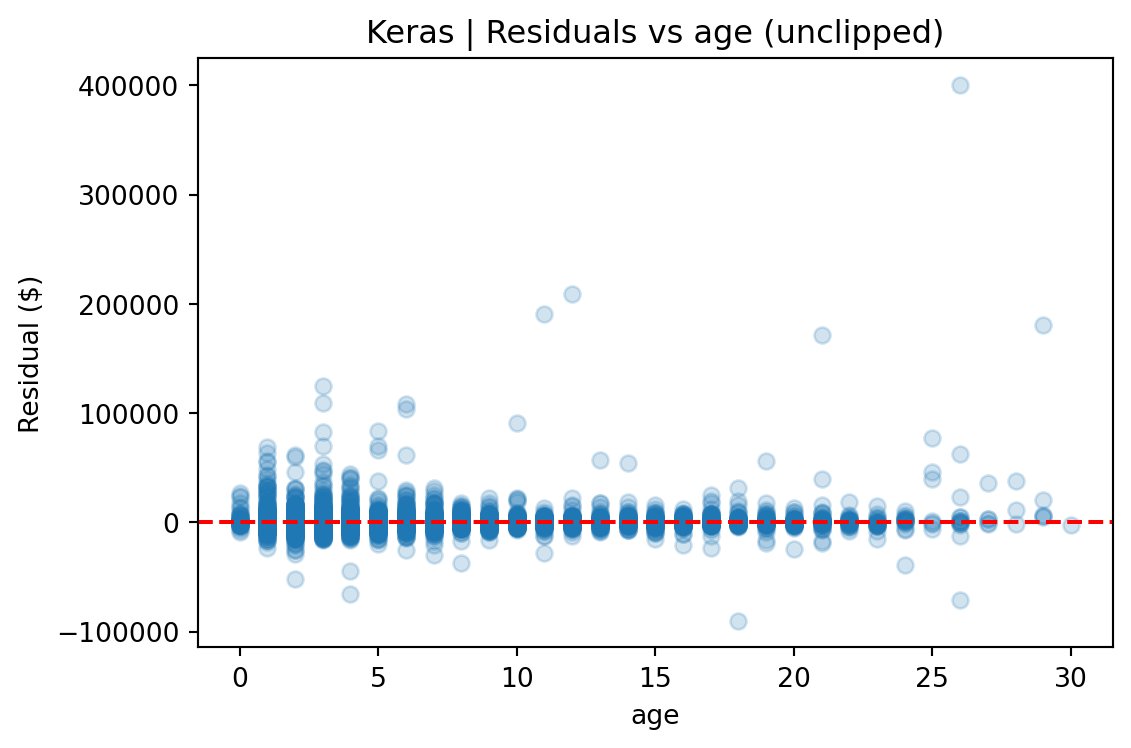
**Recent model years are overrepresented.** The year distribution shows sharp growth in listings from 2010 onward, with 2020 as the most common model year. Pre-2010 vehicles are sparse, which means predictions for older vehicles are based on substantially less training data.
**Luxury brands have higher price variance.** The box plot of price by manufacturer (clipped to 1–99%) shows that Porsche, Land Rover, and Mercedes-Benz have substantially wider interquartile ranges than mass-market brands. This motivated the `is_luxury_brand` flag and the `luxury_age_interaction` feature, allowing models to learn separate depreciation curves for luxury vs. non-luxury vehicles.
**Several text columns have very high cardinality.** Exterior color (4,040 unique values), interior color (1,855), engine (1,808), and transmission (221) are all free-text fields with OEM-specific naming conventions. These require structured extraction and consolidation before modeling — addressed in the [Feature Engineering](#feature-engineering) section below.
**Model count varies widely by manufacturer.** Volkswagen and Toyota each have 350+ unique model names, while Chrysler has fewer than 100. Combined with the 5,613 unique model values across all manufacturers, this high cardinality is one reason CatBoost's native categorical handling outperforms Ridge's one-hot encoding approach.
### Feature Engineering
The raw dataset contains several high-cardinality text fields that need structured extraction before modeling. The goal is to collapse noisy text categories into a few semantically meaningful features so that even the linear model (Ridge) sees signal rather than thousands of brittle dummy variables.
The `seller_name` column was dropped entirely — with thousands of unique sellers, the feature has high cardinality but minimal generalizable signal. A specific dealer's name is unlikely to predict price in a way that transfers to new listings.
#### Engine Parsing
The raw `engine` column is a free-text field with inconsistent formatting (e.g., "2.0L I4 Turbo", "V8 Flex Fuel", "3.6L V6 24V MPFI DOHC"). Rather than one-hot encoding 1,808 unique strings, I extracted five structured features: displacement (liters), cylinder count, engine layout (I/V/H), forced induction (turbo/supercharged), and hybrid status.
Missing engine attributes arose from heterogeneous text formats rather than data loss — this is structured missingness due to information compression, not sensor failure. I preserved those rows and handled partial observability by median imputation for numeric attributes and by explicitly writing “unknown” for categories with nominal attributes.
#### Transmission Normalization
Transmission descriptions contained extensive brand-specific and marketing terminology (221 unique values). I normalized these into transmission type (manual/automatic/CVT) and gear count, which preserved predictive signal while dramatically reducing feature dimensionality.
Because gear counts were missing for a substantial fraction of automatic transmissions, I retained the feature and added an explicit missingness indicator (`transmission_gears_missing`), allowing the models to learn separate effects for known and unspecified gear counts.
#### Color Collapsing
Raw exterior colors had 4,000+ unique OEM-specific names ("Scarlet Ember", "Sarge Green Clearcoat"). These were mapped to 7 base categories (black, white, gray, blue, red, green, other) to reduce cardinality while preserving the price-relevant signal. The same approach was applied to interior colors (2,000+ unique values collapsed to 7 groups).
#### Derived Features
- **Vehicle age**: `REFERENCE_YEAR (2023) - year`. A more interpretable framing than raw years for depreciation modeling, and generalizes better if applied to future data.
- **Mileage per year**: `mileage / max(age, 1)`. Captures usage intensity — a 5-year-old car with 100k miles has been driven harder than one with 30k miles.
- **Luxury brand flag**: A binary indicator for premium manufacturers (Porsche, BMW, Mercedes-Benz, etc.).
- **Luxury × age interaction**: Allows models to learn that luxury vehicles may depreciate differently than mass-market ones.
#### Leakage Prevention
Feature engineering does not compute any global statistics that would leak label information. All features are derived from vehicle attributes, not from price. Pipelines are used to ensure all learned preprocessing steps (imputation, encoding) are fit only on training folds during cross-validation.
#### Feature Engineering Code and Save New Parquet
```{python}
#| code-summary: "Feature engineering: engine parsing, transmission normalization, color collapsing, derived features"
# NOTE: If cleaning or feature-engineering logic changes, bump FEATURE_PIPELINE_VERSION.
# Also keep the exported src/pipeline.py copy aligned with the notebook version.
def build_features_df():
# start from cleaned df already in memory
# Log-transform the target: raw prices are heavily right-skewed
# (median ~$27k, but a long tail past $100k). log1p stabilizes
# variance and let the models optimize on relative rather than
# absolute errors. Predictions are converted back to dollars
# via expm1 at evaluation time.
y = np.log1p(df_cleaned["price"])
X = df_cleaned.drop(columns=["price", "seller_name"], errors="ignore").copy()
REFERENCE_YEAR = 2023 # The dataset ends at the beginning of 2023
# age and mileage per year
X["age"] = REFERENCE_YEAR - X["year"]
X["age_for_mpy"] = X["age"].clip(lower=1)
X["mileage_per_year"] = X["mileage"] / X["age_for_mpy"]
X = X.drop(columns=["age_for_mpy", "year"])
# Luxury brands tend to hold value differently (higher base price,
# steeper or shallower depreciation). The binary flag and its
# interaction with age, let the model learn separate depreciation
# curves for luxury vs. non-luxury vehicles.
LUXURY_BRANDS = {
"acura", "alfa romeo", "aston martin", "audi", "bentley", "bmw", "bugatti", "cadillac", "ferrari", "genesis", "infiniti", "jaguar", "lamborghini", "land rover", "lexus", "lincoln", "lotus", "maserati", "mclaren", "mercedes benz", "polestar", "porsche", "rolls royce", "tesla", "volvo"
}
X["is_luxury_brand"] = (
X["manufacturer"].isin(LUXURY_BRANDS).astype("int64")
)
X["luxury_age_interaction"] = X["is_luxury_brand"] * X["age"]
# The raw 'engine' column is a free-text field with inconsistent
# formatting (e.g., "2.0L I4 Turbo", "V8 Flex Fuel", "3.6L V6 24V").
# This parser extracts structured numeric and categorical features
# (displacement, cylinder count, layout, forced induction, hybrid
# status) to replace the high-cardinality raw string.
def parse_engine(engine):
s = str(engine)
m_l = re.search(r"(\d(?:\.\d)?)\s*l\b", s)
liters = float(m_l.group(1)) if m_l else np.nan
m_c = re.search(r"\b([ivh])\s*(\d+)\b", s)
if m_c:
layout = m_c.group(1)
cylinders = int(m_c.group(2))
else:
layout = np.nan
cylinders = np.nan
turbo = int(("turbo" in s) or ("twin turbo" in s) or ("supercharg" in s))
hybrid = int(
("hybrid" in s) or
("gas electric" in s) or
("phev" in s) or
("plug in" in s) or
("electric" in s and "gas" in s)
)
return pd.Series({
"engine_liters": liters,
"engine_cylinders": cylinders,
"engine_layout": layout,
"engine_turbo": turbo,
"engine_hybrid": hybrid
})
engine_features = X["engine"].apply(parse_engine)
X = pd.concat([X.drop(columns=["engine"]), engine_features], axis=1)
X["engine_layout"] = X["engine_layout"].fillna("unknown")
def normalize_transmission(t):
if pd.isna(t):
return "unknown"
t = str(t)
t = t.replace("a t", "automatic")
t = t.replace("auto", "automatic")
return t
def transmission_type(t):
t = normalize_transmission(t)
if t == "unknown" or "not specified" in t:
return "unknown"
if "manual" in t:
return "manual"
if ("cvt" in t) or ("variable" in t) or ("ivt" in t) or ("ecvt" in t):
return "cvt"
return "automatic"
def transmission_gears(t):
t = normalize_transmission(t)
match = re.search(r"(\d+)\s?speed", t)
return int(match.group(1)) if match else np.nan
X["transmission_clean"] = X["transmission"].apply(transmission_type)
X["transmission_gears"] = X["transmission"].apply(transmission_gears)
X = X.drop(columns=["transmission"])
X["transmission_gears_missing"] = X["transmission_gears"].isna().astype(int)
# Raw exterior colors have ~200+ unique values including OEM-specific
# names ("Scarlet Ember", "Sarge Green Clearcoat"). These are mapped
# to 7 base categories (black, white, gray, blue, red, green, other)
# to reduce cardinality while preserving the price-relevant signal
# (e.g. white/black/gray dominate resale volume; unusual colors may
# carry a premium or penalty).
def base_color(c):
c = str(c)
if "black" in c or "ebony" in c:
return "black"
if "blue" in c or "deep cerulean" in c:
return "blue"
if "red" in c or "scarlet ember" in c or "maroon" in c or "dark cherry" in c:
return "red"
if "green" in c or "army green" in c or "f8 green" in c or "dark moss" in c or "sarge green clearcoat" in c:
return "green"
if "white" in c or "pearl" in c or "whiite" in c:
return "white"
if "gray" in c or "silver" in c or "grey" in c or "gun" in c or "steel" in c or "magnetic" in c or " metal " in c or "carbon" in c or "granite" in c or "graphite" in c:
return "gray"
return "other"
X["exterior_color_base"] = X["exterior_color"].apply(base_color)
X = X.drop(columns=["exterior_color"])
# Same approach as exterior: collapse OEM interior names ("Jet Black
# Leather", "Sandstone") into 7 base groups. Interior color has a
# weaker price signal than exterior but still captures preferences.
def interior_color_base(c):
c = str(c)
if "black" in c or "ebony" in c or "jet" in c:
return "black"
if "red" in c:
return "red"
if "gray" in c or "grey" in c or "graphite" in c or "charcoal" in c or "shale" in c or "steel" in c or "pewter" in c or "slate" in c:
return "gray"
if "brown" in c or "cappuccino" in c or "mocha" in c or "espresso" in c or "cocoa" in c or "coffee" in c or "nutmeg" in c or "walnut" in c or "chestnut" in c or "hazelnut" in c or "roast" in c:
return "brown"
if "beige" in c or "tan" in c or "taupe" in c or "sand" in c or "ash" in c or "camel" in c or "cognac" in c or "parchment" in c or "stone" in c or "wheat" in c or "sandstone" in c or "cement" in c or "almond" in c or "blond" in c or "neutral" in c:
return "beige"
if "white" in c or "ivory" in c or "cream" in c:
return "white"
return "other"
X["interior_color_base"] = X["interior_color"].apply(interior_color_base)
X = X.drop(columns=["interior_color"])
# casts
numeric_casts = {
"age": "int64",
"mileage_per_year": "float64",
"engine_liters": "float64",
"engine_cylinders": "float64",
"transmission_gears": "float64",
"engine_turbo": "int64",
"engine_hybrid": "int64",
"transmission_gears_missing": "int64",
}
for col, dtype in numeric_casts.items():
if col in X.columns:
X[col] = X[col].astype(dtype)
for col in ["engine_layout", "transmission_clean", "exterior_color_base", "interior_color_base"]:
if col in X.columns:
X[col] = X[col].astype("object")
# Save X and y
features_df = X.copy()
features_df["target_log1p_price"] = y.values
return features_df
features_df = load_or_build(FEATURES_PARQUET, build_features_df, label="feature table")
# Split back out into X and y for modeling
y = features_df["target_log1p_price"]
X = features_df.drop(columns=["target_log1p_price"])
```
#### Display Dataframe After Feature Engineering
The engineered feature set has 27 columns — replacing the raw dataset's high-cardinality text fields with structured, model-ready features:
```{python}
#| code-summary: "Feature table preview"
#| column: page
display(X.head())
```
Sparse missingness remains in three parsed engine columns; these are handled by model-specific imputation:
```{python}
#| code-summary: "Missing values after feature engineering"
display(X.isnull().sum().sort_values(ascending=False))
```
## Models
### Modeling Approach
To understand the strengths and limitations of different model families for tabular data, three approaches were compared:
1. **Regularized Linear Model (Ridge)**
- Provides an interpretable baseline.
- Requires extensive feature engineering and one-hot encoding.
- Establishes a performance floor, showing what's achievable with a purely linear approach.
2. **Gradient Boosted Decision Trees (CatBoost)**
- Designed for tabular data with categorical variables.
- Automatically captures nonlinear feature interactions.
- Handles categorical variables efficiently without high-dimensional one-hot encoding.
3. **Neural Network (FT-Transformer)**
- Uses learned embeddings for categorical features.
- Applies attention mechanisms to model feature interactions.
- Evaluates whether deep learning architectures can outperform traditional tree models on structured tabular data.
Comparing these approaches highlights the tradeoffs between **interpretability, feature engineering complexity, and predictive performance**.
### Model Setup
#### Model Evaluation Methodology
The dataset was split into three partitions:
- **Training set:** used to fit model parameters
- **Validation set:** used for hyperparameter tuning and early stopping
- **Test set:** held out for final evaluation
Performance is reported using:
- **MAE (Mean Absolute Error)** — average dollar prediction error
- **RMSE (Root Mean Squared Error)** — more sensitive to large errors than MAE due to squaring
- **Median Absolute Error** — robust measure of typical error, unaffected by outliers
Because the price distribution contains rare luxury vehicles priced far above the median market value,
metrics are also reported on a **1–99% clipped subset** based on training-set price quantiles.
This provides a more representative view of typical used-vehicle predictions.
#### Make Train/Val/Test Splits
```{python}
# ----------------------------
# Reproducible train/val/test split
# ----------------------------
SPLIT_SEED = 42
def make_or_load_splits(X, y, path=SPLITS_PATH, seed=SPLIT_SEED, test_size=0.2, val_size=0.2):
"""
Creates:
- test split: test_size (e.g., 0.2)
- then splits the remaining into train/val with val_size fraction of the remaining
Persists indices so Ridge/CatBoost/Keras always use the exact same rows.
"""
if path.exists():
split_idx = json.loads(path.read_text())
train_idx = np.array(split_idx["train_idx"])
val_idx = np.array(split_idx["val_idx"])
test_idx = np.array(split_idx["test_idx"])
return train_idx, val_idx, test_idx
# First- hold out test
idx_all = np.arange(len(X))
trainval_idx, test_idx = train_test_split(
idx_all, test_size=test_size, random_state=seed
)
# Second- split trainval into train and val
# val_size is fraction of trainval (so overall val fraction is (1-test_size)*val_size
train_idx, val_idx = train_test_split(
trainval_idx, test_size=val_size, random_state=seed
)
split_idx = {
"seed": seed,
"test_size": test_size,
"val_size_of_trainval": val_size,
"train_idx": train_idx.tolist(),
"val_idx": val_idx.tolist(),
"test_idx": test_idx.tolist(),
}
path.write_text(json.dumps(split_idx, indent=2))
print("✅ Saved split indices:", path)
return train_idx, val_idx, test_idx
train_idx, val_idx, test_idx = make_or_load_splits(X, y)
X_train, y_train = X.iloc[train_idx], y.iloc[train_idx]
X_val, y_val = X.iloc[val_idx], y.iloc[val_idx]
X_test, y_test = X.iloc[test_idx], y.iloc[test_idx]
print("Rows:", {"train": len(X_train), "val": len(X_val), "test": len(X_test)})
# Shared clip bounds for clipped metrics (computed from training set only)
train_true_dollars = np.expm1(y_train)
CLIP_LO, CLIP_HI = np.quantile(train_true_dollars, [0.01, 0.99])
print(f"Clip bounds (from train): ${CLIP_LO:,.0f} – ${CLIP_HI:,.0f}")
```
#### Feature schema
```{python}
# ===============================
# Feature schema (shared across models)
# ===============================
NUMERIC_FEATURES = [
"mileage", "mpg_avg", "price_drop", "seller_rating", "driver_rating",
"driver_reviews_num", "accidents_or_damage", "one_owner", "personal_use_only",
"age", "mileage_per_year", "engine_liters", "engine_cylinders",
"engine_turbo", "engine_hybrid", "transmission_gears", "transmission_gears_missing",
"is_luxury_brand", "luxury_age_interaction",
]
CATEGORICAL_FEATURES = [
"manufacturer", "model", "drivetrain", "fuel_type", "engine_layout",
"transmission_clean", "exterior_color_base", "interior_color_base",
]
# Filter to columns that actually exist as a safety check
num_cols = [c for c in NUMERIC_FEATURES if c in X_train.columns]
cat_cols = [c for c in CATEGORICAL_FEATURES if c in X_train.columns]
# Keras aliases
num_cols_nn = list(num_cols)
cat_cols_nn = list(cat_cols)
print("Shared numeric cols:", len(num_cols), num_cols)
print("Shared categorical cols:", len(cat_cols), cat_cols)
print("Keras numeric cols:", len(num_cols_nn), num_cols_nn)
print("Keras categorical cols:", len(cat_cols_nn), cat_cols_nn)
```
#### Export Vocabularies and Model Metadata
Part 2 of this project builds a FastAPI prediction endpoint around the best model from Part 1 (Catboost). To ensure consistent preprocessing and validation, the notebook exports three reference artifacts to `models/api_artifacts/`: (1) categorical vocabularies containing known values for each categorical feature, (2) numeric medians for imputing missing optional fields, and (3) a model metadata file. The model metadata file records the feature column order, clip bounds, drivetrain mapping, luxury brand list, and pipeline version. These artifacts are loaded once at API startup so that no training-time information is hardcoded in the serving layer.
```{python}
# ===============================================================
# Export vocabularies and model metadata
# ===============================================================
# These artifacts give the API everything it needs to validate
# incoming requests and reconstruct features at inference time.
# ===============================================================
API_ARTIFACTS_DIR = MODEL_DIR / "api_artifacts"
API_ARTIFACTS_DIR.mkdir(parents=True, exist_ok=True)
# ---------------------------------------------------------------
# 1. Categorical vocabularies — known values from training data
# ---------------------------------------------------------------
# Used by the API to validate incoming categorical values and
# reject or fuzzy-match unknown inputs before they reach the model.
cat_vocabs = {}
for col in cat_cols:
cat_vocabs[col] = sorted(X_train[col].dropna().unique().tolist())
atomic_write_json(
API_ARTIFACTS_DIR / "categorical_vocabularies.json",
cat_vocabs,
)
print(f"✅ Saved categorical vocabularies ({len(cat_vocabs)} columns)")
for col, vals in cat_vocabs.items():
print(f" {col}: {len(vals)} unique values")
# ---------------------------------------------------------------
# 1b. Models by manufacturer — for conditional validation
# ---------------------------------------------------------------
# Allows the API to validate that a given model is valid for the
# specified manufacturer (e.g., reject manufacturer=toyota, model=civic).
models_by_manufacturer = (
X_train[["manufacturer", "model"]]
.drop_duplicates()
.sort_values(["manufacturer", "model"])
.groupby("manufacturer")["model"]
.apply(list)
.to_dict()
)
atomic_write_json(
API_ARTIFACTS_DIR / "models_by_manufacturer.json",
models_by_manufacturer,
)
print(f"✅ Saved models_by_manufacturer ({len(models_by_manufacturer)} manufacturers)")
# ---------------------------------------------------------------
# 2. Numeric medians from training data — for imputation
# ---------------------------------------------------------------
# At inference, if optional numeric fields are missing, the API
# can fill them with the training median (same strategy the
# models use internally).
numeric_medians = {}
for col in num_cols:
median_val = X_train[col].median()
numeric_medians[col] = None if pd.isna(median_val) else float(median_val)
atomic_write_json(
API_ARTIFACTS_DIR / "numeric_medians.json",
numeric_medians,
)
print(f"✅ Saved numeric medians ({len(numeric_medians)} features)")
# ---------------------------------------------------------------
# 3. Model metadata — everything the API needs to load and use
# the model correctly
# ---------------------------------------------------------------
model_metadata = {
"feature_pipeline_version": FEATURE_PIPELINE_VERSION,
"reference_year": 2023,
"feature_columns": list(X_train.columns),
"numeric_features": list(num_cols),
"categorical_features": list(cat_cols),
"clip_bounds": {
"q_low": 0.01,
"q_high": 0.99,
"clip_lo": float(CLIP_LO),
"clip_hi": float(CLIP_HI),
},
"drivetrain_map": {
"all wheel drive": "awd",
"awd": "awd",
"four wheel drive": "4wd",
"4wd": "4wd",
"front wheel drive": "fwd",
"fwd": "fwd",
"rear wheel drive": "rwd",
"rwd": "rwd",
},
"luxury_brands": sorted(list({
"acura", "alfa romeo", "aston martin", "audi", "bentley",
"bmw", "bugatti", "cadillac", "ferrari", "genesis",
"infiniti", "jaguar", "lamborghini", "land rover", "lexus",
"lincoln", "lotus", "maserati", "mclaren", "mercedes benz",
"polestar", "porsche", "rolls royce", "tesla", "volvo",
})),
"target_transform": "log1p",
"inverse_transform": "expm1",
}
atomic_write_json(
API_ARTIFACTS_DIR / "model_metadata.json",
model_metadata,
)
print(f"✅ Saved model_metadata.json")
print(f" Feature columns: {len(model_metadata['feature_columns'])}")
print(f" Clip bounds: ${model_metadata['clip_bounds']['clip_lo']:,.0f} – ${model_metadata['clip_bounds']['clip_hi']:,.0f}")
print(f"📁 All API artifacts: {API_ARTIFACTS_DIR}")
```
#### Evaluation Functions
```{python}
#| code-summary: "Evaluation functions: RMSE, MAE, MedianAE, full and clipped metrics"
def rmse(y_true, y_pred) -> float:
return float(np.sqrt(mean_squared_error(y_true, y_pred)))
def regression_metrics(y_true, y_pred) -> dict:
y_true = np.asarray(y_true)
y_pred = np.asarray(y_pred)
return {
"mae": float(mean_absolute_error(y_true, y_pred)),
"rmse": rmse(y_true, y_pred),
"median_ae": float(np.median(np.abs(y_true - y_pred))),
"n": int(len(y_true)),
}
def metrics_full_and_clipped(y_true, y_pred, q_low=0.01, q_high=0.99,
clip_lo=None, clip_hi=None) -> dict:
y_true = np.asarray(y_true)
y_pred = np.asarray(y_pred)
out = {}
out["full"] = regression_metrics(y_true, y_pred)
# Use provided bounds, or fall back to computing from y_true
if clip_lo is None or clip_hi is None:
lo, hi = np.quantile(y_true, [q_low, q_high])
else:
lo, hi = clip_lo, clip_hi
mask = (y_true >= lo) & (y_true <= hi)
out["clipped"] = regression_metrics(y_true[mask], y_pred[mask])
out["clipped"]["clip_q_low"] = float(q_low)
out["clipped"]["clip_q_high"] = float(q_high)
out["clipped"]["clip_lo"] = float(lo)
out["clipped"]["clip_hi"] = float(hi)
return out
def metrics_to_df(metrics_dict, model_name: str) -> pd.DataFrame:
"""
Convert output from metrics_full_and_clipped into a DataFrame.
"""
rows = []
for view in ["full", "clipped"]:
m = metrics_dict[view]
rows.append({
"model": model_name,
"view": view,
"n": m["n"],
"MAE ($)": m["mae"],
"RMSE ($)": m["rmse"],
"MedianAE ($)": m["median_ae"],
**({} if view == "full" else {
"clip_lo($)": m["clip_lo"],
"clip_hi($)": m["clip_hi"],
"q_low": m["clip_q_low"],
"q_high": m["clip_q_high"],
})
})
df = pd.DataFrame(rows).set_index(["model", "view"])
return df
```
### Ridge Regression (Pipeline + Grid Search)
#### Ridge Training
```{python}
#| code-summary: "Ridge: GridSearchCV with 5-fold CV, refit on train+val, save artifacts"
# ==========================================================
# RIDGE: Train (CV on train) → Refit (train+val) → Evaluate (test)
# Uses the shared X_train/X_val/X_test and y_train/y_val/y_test
# ==========================================================
best_ridge = None
if RIDGE_PATH.exists() and not RETRAIN_RIDGE:
print("✅ Loading existing Ridge model (RETRAIN_RIDGE=False)")
if not RIDGE_LATEST_RUN_INFO_PATH.exists():
raise FileNotFoundError(
f"Ridge latest metadata file not found: {RIDGE_LATEST_RUN_INFO_PATH}. "
"Retrain Ridge once to create matching schema metadata."
)
ridge_saved_info = json.loads(RIDGE_LATEST_RUN_INFO_PATH.read_text())
assert_saved_schema_matches(
saved_feature_version=ridge_saved_info["feature_pipeline_version"],
saved_feature_columns=ridge_saved_info["feature_columns"],
current_feature_version=FEATURE_PIPELINE_VERSION,
current_feature_columns=list(X_train.columns),
model_name="Ridge",
)
best_ridge = joblib.load(RIDGE_PATH)
else:
if RIDGE_PATH.exists() and RETRAIN_RIDGE:
print("🔁 RETRAIN_RIDGE=True — retraining Ridge while keeping old model")
else:
print("🔁 Training Ridge (no existing model found)")
numeric_pipe = Pipeline(steps=[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler())
])
categorical_pipe = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("ohe", OneHotEncoder(handle_unknown="ignore", min_frequency=50, sparse_output=True))
])
preprocess = ColumnTransformer(
transformers=[
("num", numeric_pipe, num_cols),
("cat", categorical_pipe, cat_cols),
],
remainder="drop"
)
ridge_model = Pipeline(steps=[
("prep", preprocess),
("ridge", Ridge()),
])
cv = KFold(n_splits=5, shuffle=True, random_state=42)
param_grid = {"ridge__alpha": np.logspace(-3, 3, 13)}
gs = GridSearchCV(
ridge_model,
param_grid=param_grid,
scoring="neg_root_mean_squared_error",
cv=cv,
n_jobs=-1,
verbose=1
)
gs.fit(X_train, y_train)
best_ridge = gs.best_estimator_
print("Best alpha:", gs.best_params_["ridge__alpha"])
print("Best CV RMSE (log space):", -gs.best_score_)
X_trainval = pd.concat([X_train, X_val], axis=0)
y_trainval = pd.concat([y_train, y_val], axis=0)
best_ridge.fit(X_trainval, y_trainval)
# ----------------------------
# Save Ridge artifacts to a run folder
# ----------------------------
run_ts = datetime.now().strftime("%Y%m%d_%H%M%S")
RIDGE_RUN_DIR = RIDGE_DIR / run_dir_name(run_ts, TRAIN_MODE)
RIDGE_RUN_DIR.mkdir(parents=True, exist_ok=True)
versioned_path = RIDGE_RUN_DIR / "ridge_pipeline.joblib"
# Save the trained pipeline
joblib.dump(best_ridge, versioned_path)
ridge_run_info = {
"run_ts": run_ts,
"train_mode": TRAIN_MODE,
"retrain_ridge": bool(RETRAIN_RIDGE),
"best_params": gs.best_params_ if "gs" in locals() else None,
"best_cv_rmse_log": float(-gs.best_score_) if "gs" in locals() else None,
"num_cols": list(num_cols),
"cat_cols": list(cat_cols),
"feature_pipeline_version": FEATURE_PIPELINE_VERSION,
"feature_columns": list(X_train.columns),
}
atomic_write_json(RIDGE_RUN_DIR / "run_info.json", ridge_run_info)
# Update "latest" ONLY for full mode
if TRAIN_MODE == "full":
joblib.dump(best_ridge, RIDGE_LATEST_PATH)
atomic_write_json(RIDGE_LATEST_RUN_INFO_PATH, ridge_run_info)
print("✅ Updated latest Ridge:", RIDGE_LATEST_PATH)
else:
print("🚫 Smoke run: NOT updating latest Ridge pointer.")
print("💾 Saved Ridge model:")
print(" - Versioned:", versioned_path)
print(" - Run folder:", RIDGE_RUN_DIR)
```
#### Ridge Evaluation
```{python}
#| code-summary: "Ridge evaluation: test metrics, train+val metrics, largest residuals"
# ==========================================================
# RIDGE EVALUATION (+ write run metrics.json)
# ==========================================================
# 0) Resolve paths
RIDGE_LATEST = RIDGE_LATEST_PATH if "RIDGE_LATEST_PATH" in globals() else RIDGE_PATH
# 1) If we're in skip mode, try to load "latest" Ridge if needed
if ("TRAIN_MODE" in globals()) and (TRAIN_MODE == "skip"):
if best_ridge is None:
if RIDGE_LATEST.exists():
print("✅ TRAIN_MODE='skip' — loading latest Ridge model for evaluation:\n ", RIDGE_LATEST)
if not RIDGE_LATEST_RUN_INFO_PATH.exists():
raise FileNotFoundError(
f"Ridge latest metadata file not found: {RIDGE_LATEST_RUN_INFO_PATH}. "
"Retrain Ridge once to create matching schema metadata."
)
ridge_saved_info = json.loads(RIDGE_LATEST_RUN_INFO_PATH.read_text())
assert_saved_schema_matches(
saved_feature_version=ridge_saved_info["feature_pipeline_version"],
saved_feature_columns=ridge_saved_info["feature_columns"],
current_feature_version=FEATURE_PIPELINE_VERSION,
current_feature_columns=list(X_train.columns),
model_name="Ridge",
)
best_ridge = joblib.load(RIDGE_LATEST)
else:
print("⏭️ TRAIN_MODE='skip' — no saved Ridge model found; skipping Ridge evaluation.")
best_ridge = None
# 2) If we still don't have a model, we can't evaluate
if best_ridge is None:
print("⚠️ Ridge model is not available — cannot evaluate.")
else:
# ----------------------------
# TEST metrics
# ----------------------------
ridge_pred_log_test = best_ridge.predict(X_test)
ridge_pred_test = np.expm1(ridge_pred_log_test)
ridge_true_test = np.expm1(y_test)
ridge_m = metrics_full_and_clipped(ridge_true_test, ridge_pred_test, clip_lo=CLIP_LO, clip_hi=CLIP_HI)
print(f"RIDGE TEST RMSE ($): {ridge_m['full']['rmse']:,.0f}")
# Feature count
try:
prep = best_ridge.named_steps["prep"]
ohe = prep.named_transformers_["cat"].named_steps["ohe"]
n_ohe_features = len(ohe.get_feature_names_out(cat_cols))
print("One-hot features:", n_ohe_features)
print("Total features (num + ohe):", len(num_cols) + n_ohe_features)
except Exception as e:
print("⚠️ Could not compute one-hot feature count:", e)
display(metrics_to_df(ridge_m, "Ridge (Test)"))
# ----------------------------
# TRAIN+VAL metrics
# ----------------------------
X_trainval = pd.concat([X_train, X_val], axis=0)
y_trainval = pd.concat([y_train, y_val], axis=0)
ridge_pred_trainval_log = best_ridge.predict(X_trainval)
ridge_pred_trainval = np.expm1(ridge_pred_trainval_log)
ridge_true_trainval = np.expm1(y_trainval)
ridge_tv = metrics_full_and_clipped(ridge_true_trainval, ridge_pred_trainval, clip_lo=CLIP_LO, clip_hi=CLIP_HI)
display(metrics_to_df(ridge_tv, "Ridge (Train+Val)"))
# Largest abs residuals on Train+Val
# These rare ultra-high-value vehicles explain why full-distribution
# RMSE is much larger than clipped RMSE — a handful of $500k+ cars
# dominate the error metric.
print("Largest absolute residuals (Train+Val):")
ridge_residuals_trainval = ridge_true_trainval - ridge_pred_trainval
ridge_outliers_trainval = (
pd.DataFrame({
"actual": ridge_true_trainval,
"predicted": ridge_pred_trainval,
"abs_error": np.abs(ridge_residuals_trainval),
})
.sort_values("abs_error", ascending=False)
.head(10)
)
display(ridge_outliers_trainval)
# Globals for metrics writer (clipped + full)
ridge_test_full = ridge_m["full"]
ridge_test_clipped = ridge_m["clipped"]
ridge_trainval_full = ridge_tv["full"]
ridge_trainval_clipped = ridge_tv["clipped"]
# ----------------------------------------------------------
# 3) Write Ridge metrics into the current run folder (if any)
# ----------------------------------------------------------
if ("RIDGE_RUN_DIR" in globals()) and (globals().get("RIDGE_RUN_DIR", None) is not None):
ridge_metrics_payload = {
"_meta": {
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"train_mode": TRAIN_MODE if "TRAIN_MODE" in globals() else None,
"latest_pointer": str(RIDGE_LATEST),
"run_dir": str(RIDGE_RUN_DIR),
"split_policy": str(SPLITS_PATH.name) if "SPLITS_PATH" in globals() else None,
"clip_policy": {
"basis": "y_train_quantiles",
"q_low": 0.01,
"q_high": 0.99,
"clip_lo": float(CLIP_LO),
"clip_hi": float(CLIP_HI),
},
},
"ridge": {
"trainval": {"full": ridge_trainval_full, "clipped": ridge_trainval_clipped},
"test": {"full": ridge_test_full, "clipped": ridge_test_clipped},
},
}
atomic_write_json(RIDGE_RUN_DIR / "ridge_metrics.json", ridge_metrics_payload)
print("🧾 Wrote Ridge run metrics:", RIDGE_RUN_DIR / "ridge_metrics.json")
else:
pass # Expected: Ridge loaded from checkpoint, no new run directory to write to
```
#### Ridge Interpretation
The Ridge regression achieved a test MAE of ~$3,011 and a test RMSE of ~$7,824, serving as a linear baseline. The gap between MAE and RMSE indicates that while typical pricing errors are modest (~$1,759 median absolute error), a few high-value or atypical vehicles contribute disproportionately to total error.
When clipped to the 1–99% price range ($7k–$91k), Ridge's RMSE drops to $4,211 — nearly half the full-distribution value. This confirms that the linear model handles the bulk of the market well but struggles with rare luxury vehicles, where pricing is driven by factors not well captured by additive features.
The Ridge model used 991 total features (19 numeric + 972 one-hot encoded categorical dummies). This high dimensionality from one-hot encoding is one reason tree-based models, which handle categories natively, have an architectural advantage on this dataset.
### CatBoost (Grid Search → Early Stopping Refit)
#### Catboost Setup Functions
```{python}
#| code-summary: "CatBoost helper functions: status display, staged grid search, early stopping refit"
def _status_label(done: Path, prog: Path) -> str:
if done.exists(): return "✅ done"
if prog.exists(): return "🟡 in progress"
return "—"
def print_catboost_status_global_and_latest_run(catboost_dir: Path):
# ---- Global ----
print("CatBoost checkpoint status (GLOBAL):")
print(" Stage 1:", _status_label(STAGE1_DONE, STAGE1_INPROGRESS))
print(" Stage 2:", _status_label(STAGE2_DONE, STAGE2_INPROGRESS))
print(" Final: ", _status_label(FINAL_DONE, FINAL_INPROGRESS))
# ---- Latest run folder ----
run_dirs = [p for p in catboost_dir.glob("run_*") if p.is_dir()]
if not run_dirs:
print("CatBoost checkpoint status (LATEST RUN):")
print(" (no run_* folders found)")
return
latest = max(run_dirs, key=lambda p: p.stat().st_mtime)
print(f"CatBoost checkpoint status (LATEST RUN): {latest.name}")
s1_done = latest / "stage1_done.txt"
s1_prog = latest / "stage1_in_progress.txt"
s2_done = latest / "stage2_done.txt"
s2_prog = latest / "stage2_in_progress.txt"
f_done = latest / "catboost_done.txt"
f_prog = latest / "final_in_progress.txt"
print(" Stage 1:", _status_label(s1_done, s1_prog))
print(" Stage 2:", _status_label(s2_done, s2_prog))
print(" Final: ", _status_label(f_done, f_prog))
# Point out whether the model file exists in that run
model_path = latest / "catboost_final.cbm"
print(" Model file:", "✅ present" if model_path.exists() else "— missing")
```
```{python}
# ==========================================================
# CatBoost helper - Get data for smoke vs. full
# ==========================================================
def get_catboost_training_data(X, y, *, mode="full"):
"""
Returns X_train_sm, X_val_sm, X_test_sm,
y_train_sm, y_val_sm, y_test_sm,
cat_cols_cb, param_grid_1, param_grid_2,
final_iterations, early_stop, cv1_splits, cv2_splits,
refit_on_trainval, refit_iteration_buffer
using the shared split variables already created earlier in the notebook.
It adjusts smoke/full behavior and returns grids + settings.
"""
cat_cols_cb = [c for c in cat_cols if c in X_train.columns]
if mode == "smoke":
# small subset for quick validation
n = min(5000, len(X_train))
X_train_sm = X_train.sample(n=n, random_state=42)
y_train_sm = y_train.loc[X_train_sm.index]
n2 = min(2000, len(X_val))
X_val_sm = X_val.sample(n=n2, random_state=42)
y_val_sm = y_val.loc[X_val_sm.index]
n3 = min(2000, len(X_test))
X_test_sm = X_test.sample(n=n3, random_state=42)
y_test_sm = y_test.loc[X_test_sm.index]
param_grid_1 = {
"depth": [4],
"learning_rate": [0.05],
"l2_leaf_reg": [3],
"iterations": [200],
}
param_grid_2 = {
"iterations": [300],
"subsample": [1.0],
"rsm": [1.0],
"random_strength": [1.0],
"min_data_in_leaf": [1],
"bagging_temperature": [0.0],
}
final_iterations = 800
early_stop = 50
cv1_splits = 2
cv2_splits = 2
refit_on_trainval = True
refit_iteration_buffer = 1.05
return (
X_train_sm, X_val_sm, X_test_sm,
y_train_sm, y_val_sm, y_test_sm,
cat_cols_cb, param_grid_1, param_grid_2,
final_iterations, early_stop, cv1_splits, cv2_splits,
refit_on_trainval, refit_iteration_buffer,
)
else:
# full run
# Two-stage grid search strategy:
# Stage 1 searches the structural hyperparameters (depth, learning
# rate, L2 regularization) that have the largest effect on the model
# capacity. Running these first narrows the search space so that
# Stage 2 can focus on finer regularization knobs (subsampling,
# feature fraction, bagging temperature) around the Stage 1 winner.
# This is more efficient than a single large grid, which would be
# prohibitively expensive with CatBoost's native categorical handling.
# Stage 1: broader structural search
param_grid_1 = {
"depth": [4, 5, 6, 7, 8], # selected 8
"learning_rate": [0.02, 0.03, 0.05, 0.07], # selected 0.07
"l2_leaf_reg": [3, 10, 30], # selected 3
"iterations": [2000],
}
# Stage 2: refinement / regularization search around Stage 1 winner
param_grid_2 = {
"iterations": [3000],
"subsample": [0.85, 1.0], # selected 1.0
"rsm": [0.85, 1.0], # selected 0.85
"random_strength": [1.0, 2.0], # selected 2.0
"min_data_in_leaf": [1, 5], # selected 1
"bagging_temperature": [0.0, 1.0], # selected 0.0
}
final_iterations = 8000
early_stop = 400
cv1_splits = 3
cv2_splits = 2
# After best_iteration is found using VAL, optionally refit on train+val
# After finding best_iteration via early stopping on the validation
# set, optionally refit the final model on the combined train+val.
# This uses ~20% more data for the production model. The risk is
# that the optimal iteration count may differ slightly without a
# held-out stopping signal, so refit_iteration_buffer (e.g. 1.05)
# adds a small margin to the early-stopped iteration count.
# The test set remains fully untouched for final evaluation.
refit_on_trainval = True
refit_iteration_buffer = 1.05
return (
X_train, X_val, X_test,
y_train, y_val, y_test,
cat_cols_cb, param_grid_1, param_grid_2,
final_iterations, early_stop, cv1_splits, cv2_splits,
refit_on_trainval, refit_iteration_buffer,
)
```
```{python}
def _stage_paths(run_dir: Path, stage: str):
"""
Return run-scoped marker/param paths so smoke runs never touch global files.
stage: "stage1" | "stage2" | "final"
"""
if stage == "stage1":
return {
"params": run_dir / "stage1_best_params.json",
"done": run_dir / "stage1_done.txt",
"inprog": run_dir / "stage1_in_progress.txt",
}
if stage == "stage2":
return {
"params": run_dir / "stage2_best_params.json",
"done": run_dir / "stage2_done.txt",
"inprog": run_dir / "stage2_in_progress.txt",
}
if stage == "final":
return {
"params": run_dir / "final_params.json",
"done": run_dir / "catboost_done.txt",
"inprog": run_dir / "final_in_progress.txt",
}
raise ValueError(f"Unknown stage: {stage}")
```
#### Catboost Training
```{python}
#| code-summary: "CatBoost: staged hyperparameter search, early stopping, final refit on train+val"
print_catboost_status_global_and_latest_run(CATBOOST_DIR)
# ==========================================================
# CatBoost training / loading
# ==========================================================
# CatBoost training is performed in three stages:
# 1) Coarse grid search for structural hyperparameters
# 2) Refinement grid search around the best region
# 3) Final training with early stopping, optionally refit on train+val
final_cb = None
RUN_DIR = None
# ---------------------------
# Global "skip" mode
# ---------------------------
if TRAIN_MODE == "skip":
print("⏭️ Skipping CatBoost training (TRAIN_MODE='skip').")
if CATBOOST_FINAL_PATH.exists():
if not CATBOOST_LATEST_RUN_INFO_PATH.exists():
raise FileNotFoundError(
f"CatBoost latest metadata file not found: {CATBOOST_LATEST_RUN_INFO_PATH}. "
"Retrain CatBoost once to create matching schema metadata."
)
cb_saved_info = json.loads(CATBOOST_LATEST_RUN_INFO_PATH.read_text())
assert_saved_schema_matches(
saved_feature_version=cb_saved_info["feature_pipeline_version"],
saved_feature_columns=cb_saved_info["feature_columns"],
current_feature_version=FEATURE_PIPELINE_VERSION,
current_feature_columns=list(X_train.columns),
model_name="CatBoost",
)
final_cb = CatBoostRegressor()
final_cb.load_model(str(CATBOOST_FINAL_PATH))
print("✅ Loaded CatBoost final model:", CATBOOST_FINAL_PATH)
else:
print("⚠️ No final CatBoost model found at:", CATBOOST_FINAL_PATH)
else:
# --------------------------------------------
# Full mode can load existing latest model or train
# --------------------------------------------
if (TRAIN_MODE == "full") and CATBOOST_FINAL_PATH.exists() and (not RETRAIN_CATBOOST):
print("✅ Loading existing CatBoost final model (RETRAIN_CATBOOST=False, TRAIN_MODE='full'):")
# Commenting out for notebook render
# print(" ", CATBOOST_FINAL_PATH)
if not CATBOOST_LATEST_RUN_INFO_PATH.exists():
raise FileNotFoundError(
f"CatBoost latest metadata file not found: {CATBOOST_LATEST_RUN_INFO_PATH}. "
"Retrain CatBoost once to create matching schema metadata."
)
cb_saved_info = json.loads(CATBOOST_LATEST_RUN_INFO_PATH.read_text())
assert_saved_schema_matches(
saved_feature_version=cb_saved_info["feature_pipeline_version"],
saved_feature_columns=cb_saved_info["feature_columns"],
current_feature_version=FEATURE_PIPELINE_VERSION,
current_feature_columns=list(X_train.columns),
model_name="CatBoost",
)
final_cb = CatBoostRegressor()
final_cb.load_model(str(CATBOOST_FINAL_PATH))
else:
# We are training (either smoke, or full retrain, or no model exists)
if TRAIN_MODE == "smoke":
print("Smoke mode: quick end-to-end training sanity check (will NOT update latest).")
elif CATBOOST_FINAL_PATH.exists() and RETRAIN_CATBOOST:
print("🔁 RETRAIN_CATBOOST=True — retraining while keeping old versions.")
else:
print("Training CatBoost (no final checkpoint found).")
# Prepare data + mode-specific settings
(
X_train_cb, X_val_cb, X_test_cb,
y_train_cb, y_val_cb, y_test_cb,
cat_cols_cb, param_grid_1, param_grid_2,
final_iterations, early_stop, cv1_splits, cv2_splits,
refit_on_trainval, refit_iteration_buffer
) = get_catboost_training_data(X, y, mode=TRAIN_MODE)
print("TRAIN_MODE:", TRAIN_MODE)
print("CatBoost categorical columns:", cat_cols_cb)
# Timestamp for versioned artifacts for this run
run_ts = datetime.now().strftime("%Y%m%d_%H%M%S")
RUN_DIR = CATBOOST_DIR / run_dir_name(run_ts, TRAIN_MODE)
RUN_DIR.mkdir(parents=True, exist_ok=True)
# Run metadata
run_info = {
"run_ts": run_ts,
"train_mode": TRAIN_MODE,
"retrain_catboost": bool(RETRAIN_CATBOOST),
"data_rows_total": int(len(X)),
"train_rows": int(len(X_train_cb)),
"val_rows": int(len(X_val_cb)),
"test_rows": int(len(X_test_cb)),
"cv_stage1_splits": int(cv1_splits),
"cv_stage2_splits": int(cv2_splits),
"catboost_categorical_columns": list(cat_cols_cb),
"stage1_param_grid": param_grid_1,
"stage2_param_grid_base": param_grid_2,
"final_iterations_cap": int(final_iterations),
"early_stopping_rounds": int(early_stop),
"refit_on_trainval": bool(refit_on_trainval),
"refit_iteration_buffer": float(refit_iteration_buffer),
"updates_latest": bool(should_update_latest(TRAIN_MODE)),
"feature_pipeline_version": FEATURE_PIPELINE_VERSION,
"feature_columns": list(X_train_cb.columns),
}
atomic_write_json(RUN_DIR / "run_info.json", run_info)
print("📝 Wrote run metadata:", RUN_DIR / "run_info.json")
if TRAIN_MODE == "smoke":
atomic_write_bytes(
RUN_DIR / "SMOKE_RUN_DO_NOT_USE.txt",
b"This is a smoke test run. Do not use as production/latest.\n"
)
# --------------------------------------------
# Decide if allowed to touch GLOBAL
# --------------------------------------------
TOUCH_GLOBAL = (TRAIN_MODE == "full")
# Run-scoped stage files
s1 = _stage_paths(RUN_DIR, "stage1")
s2 = _stage_paths(RUN_DIR, "stage2")
sf = _stage_paths(RUN_DIR, "final")
# -------------------------
# Stage 1: coarse tuning
# -------------------------
# Preference order for FULL mode:
# (a) use global stage1 params if done and not retraining
# (b) otherwise run stage1 and save to RUN_DIR (and global if FULL)
if TOUCH_GLOBAL and STAGE1_DONE.exists() and STAGE1_PARAMS_PATH.exists() and (not RETRAIN_CATBOOST):
print("✅ Stage 1 already done (GLOBAL) — loading best params.")
best1 = json.loads(STAGE1_PARAMS_PATH.read_text())
# also write into run folder for auditability
atomic_write_json(s1["params"], best1)
mark_done(s1["done"], "ok (loaded global)")
else:
print("🧪 Stage 1: coarse tuning")
mark_in_progress(s1["inprog"], "stage1 started")
if TOUCH_GLOBAL:
mark_in_progress(STAGE1_INPROGRESS, "stage1 started (global)")
try:
cv1 = KFold(n_splits=cv1_splits, shuffle=True, random_state=42)
cb_base = CatBoostRegressor(
loss_function="RMSE",
random_seed=42,
verbose=0,
allow_writing_files=False
)
gs1 = GridSearchCV(
estimator=cb_base,
param_grid=param_grid_1,
scoring="neg_root_mean_squared_error",
cv=cv1,
n_jobs=1, # n_jobs=1 because CatBoost handles its own internal parallelism
verbose=2
)
gs1.fit(X_train_cb, y_train_cb, cat_features=cat_cols_cb)
best1 = gs1.best_params_
print("Stage 1 best params:", best1)
print("Stage 1 best CV RMSE (log):", -gs1.best_score_)
# Always save run-scoped
atomic_write_json(s1["params"], best1)
mark_done(s1["done"])
# Only FULL updates global artifacts
if TOUCH_GLOBAL:
atomic_write_json(STAGE1_PARAMS_PATH, best1)
mark_done(STAGE1_DONE)
finally:
clear_file(s1["inprog"])
if TOUCH_GLOBAL:
clear_file(STAGE1_INPROGRESS)
# -------------------------
# Stage 2: refinement
# -------------------------
if TOUCH_GLOBAL and STAGE2_DONE.exists() and STAGE2_PARAMS_PATH.exists() and (not RETRAIN_CATBOOST):
print("✅ Stage 2 already done (GLOBAL) — loading refined params.")
best2 = json.loads(STAGE2_PARAMS_PATH.read_text())
atomic_write_json(s2["params"], best2)
mark_done(s2["done"], "ok (loaded global)")
else:
print("🧪 Stage 2: refinement")
mark_in_progress(s2["inprog"], "stage2 started")
if TOUCH_GLOBAL:
mark_in_progress(STAGE2_INPROGRESS, "stage2 started (global)")
try:
cv2 = KFold(n_splits=cv2_splits, shuffle=True, random_state=42)
stage2_grid = {
"depth": [best1["depth"]],
"learning_rate": [best1["learning_rate"]],
"l2_leaf_reg": [best1["l2_leaf_reg"]],
**param_grid_2
}
cb_base2 = CatBoostRegressor(
loss_function="RMSE",
random_seed=42,
verbose=0,
allow_writing_files=False
)
gs2 = GridSearchCV(
estimator=cb_base2,
param_grid=stage2_grid,
scoring="neg_root_mean_squared_error",
cv=cv2,
n_jobs=1,
verbose=2
)
gs2.fit(X_train_cb, y_train_cb, cat_features=cat_cols_cb)
best2 = gs2.best_params_
best_cb = gs2.best_estimator_
print("Stage 2 best params:", best2)
print("Stage 2 best CV RMSE (log):", -gs2.best_score_)
y_pred_log = best_cb.predict(X_val_cb)
y_pred = np.expm1(y_pred_log)
y_true = np.expm1(y_val_cb)
mae_cv = mean_absolute_error(y_true, y_pred)
rmse_cv = np.sqrt(mean_squared_error(y_true, y_pred))
print(f"CV-BEST VAL MAE ($): {mae_cv:,.0f}")
print(f"CV-BEST VAL RMSE ($): {rmse_cv:,.0f}")
atomic_write_json(s2["params"], best2)
mark_done(s2["done"])
if TOUCH_GLOBAL:
atomic_write_json(STAGE2_PARAMS_PATH, best2)
mark_done(STAGE2_DONE)
finally:
clear_file(s2["inprog"])
if TOUCH_GLOBAL:
clear_file(STAGE2_INPROGRESS)
# -------------------------
# Stage 3: final fit on TRAIN with VAL early stopping
# then optional refit on TRAIN+VAL
# -------------------------
print("🏁 Stage 3: final fit with early stopping on VAL")
mark_in_progress(sf["inprog"], "final refit started")
if TOUCH_GLOBAL:
mark_in_progress(FINAL_INPROGRESS, "final refit started (global)")
try:
# --------------------------------------------
# 3A) Fit on TRAIN, early stop on VAL
# --------------------------------------------
final_params = best2.copy()
final_params["iterations"] = final_iterations # cap; early stopping decides
cb_train_val = CatBoostRegressor(
**final_params,
loss_function="RMSE",
random_seed=42,
verbose=200,
allow_writing_files=False
)
cb_train_val.fit(
X_train_cb, y_train_cb,
cat_features=cat_cols_cb,
eval_set=(X_val_cb, y_val_cb),
early_stopping_rounds=early_stop,
use_best_model=True
)
assert cb_train_val.is_fitted(), "CatBoost train/val model not fitted; refusing to continue."
best_iteration_raw = cb_train_val.get_best_iteration()
if best_iteration_raw is None or int(best_iteration_raw) < 0:
best_iteration_raw = final_iterations
best_iteration = int(best_iteration_raw)
print("Best iteration from TRAIN/VAL fit:", best_iteration)
# --------------------------------------------
# 3B) Optional refit on TRAIN+VAL
# --------------------------------------------
refit_meta = {
"did_refit_on_trainval": False,
"best_iteration_from_train_val_fit": int(best_iteration),
"refit_iteration_buffer": float(refit_iteration_buffer),
"refit_iterations_used": int(best_iteration),
}
if refit_on_trainval:
print("🔁 Refit enabled: training final CatBoost on TRAIN+VAL")
X_trainval_cb = pd.concat([X_train_cb, X_val_cb], axis=0)
y_trainval_cb = pd.concat([y_train_cb, y_val_cb], axis=0)
refit_iterations = max(
1,
int(np.ceil(best_iteration * float(refit_iteration_buffer)))
)
refit_iterations = min(refit_iterations, int(final_iterations))
refit_params = best2.copy()
refit_params["iterations"] = refit_iterations
final_cb = CatBoostRegressor(
**refit_params,
loss_function="RMSE",
random_seed=42,
verbose=200,
allow_writing_files=False
)
final_cb.fit(
X_trainval_cb, y_trainval_cb,
cat_features=cat_cols_cb
)
assert final_cb.is_fitted(), "CatBoost refit model not fitted; refusing to save."
refit_meta = {
"did_refit_on_trainval": True,
"best_iteration_from_train_val_fit": int(best_iteration),
"refit_iteration_buffer": float(refit_iteration_buffer),
"refit_iterations_used": int(refit_iterations),
}
print("✅ Refit complete on TRAIN+VAL")
print("Refit iterations used:", refit_iterations)
else:
print("ℹ️ Refit disabled — using TRAIN/VAL early-stopped model as final model.")
final_cb = cb_train_val
refit_meta = {
"did_refit_on_trainval": False,
"best_iteration_from_train_val_fit": int(best_iteration),
"refit_iteration_buffer": float(refit_iteration_buffer),
"refit_iterations_used": int(best_iteration),
}
cb_best_iteration_from_train_val_fit = int(refit_meta["best_iteration_from_train_val_fit"])
cb_refit_on_trainval_used = bool(refit_meta["did_refit_on_trainval"])
cb_refit_iterations_used = int(refit_meta["refit_iterations_used"])
# --------------------------------------------
# 3C) Save metadata + artifacts
# --------------------------------------------
final_params_to_save = dict(best2)
final_params_to_save["iterations"] = int(refit_meta["refit_iterations_used"])
final_training_summary = {
"base_best2_params": best2,
"train_val_fit_iterations_cap": int(final_iterations),
"early_stopping_rounds": int(early_stop),
**refit_meta,
}
atomic_write_json(RUN_DIR / "feature_columns.json", list(X_train_cb.columns))
if TOUCH_GLOBAL:
atomic_write_json(FEATURE_COLS_PATH, list(X_train_cb.columns))
atomic_write_json(sf["params"], final_params_to_save)
atomic_write_json(RUN_DIR / "final_params.json", final_params_to_save)
atomic_write_json(RUN_DIR / "final_training_summary.json", final_training_summary)
if TOUCH_GLOBAL:
atomic_write_json(FINAL_PARAMS_PATH, final_params_to_save)
# Save model versioned always
versioned_model_path = RUN_DIR / "catboost_final.cbm"
final_cb.save_model(str(versioned_model_path))
# Only FULL updates "latest"
if should_update_latest(TRAIN_MODE):
final_cb.save_model(str(CATBOOST_FINAL_PATH))
atomic_write_json(CATBOOST_LATEST_RUN_INFO_PATH, run_info)
print("✅ Updated latest:", CATBOOST_FINAL_PATH)
else:
print("🚫 Smoke run: NOT updating latest pointer.")
mark_done(sf["done"])
if TOUCH_GLOBAL:
mark_done(FINAL_DONE)
print("💾 Saved CatBoost model:")
print(" - Latest:", CATBOOST_FINAL_PATH)
print(" - Versioned:", versioned_model_path)
print(" - Run folder:", RUN_DIR)
finally:
clear_file(sf["inprog"])
if TOUCH_GLOBAL:
clear_file(FINAL_INPROGRESS)
```
#### Catboost Evaluation
```{python}
#| code-summary: "CatBoost evaluation: train/val/test metrics, feature importance"
# ==========================================================
# CATBOOST EVALUATION
# ==========================================================
if final_cb is None:
print("⚠️ CatBoost model not available — skipping evaluation.")
else:
# ----------------------------
# Report final training metadata
# ----------------------------
cb_refit_used = bool(globals().get("cb_refit_on_trainval_used", False))
cb_best_iter_tv = globals().get("cb_best_iteration_from_train_val_fit", None)
cb_refit_iters = globals().get("cb_refit_iterations_used", None)
if cb_best_iter_tv is not None:
print("Best iteration from TRAIN/VAL fit:", cb_best_iter_tv)
if cb_refit_used:
print("Final CatBoost model was refit on TRAIN+VAL.")
if cb_refit_iters is not None:
print("Refit iterations used:", cb_refit_iters)
else:
print("Final CatBoost model is the TRAIN-only model with VAL early stopping.")
# ----------------------------
# TEST split metrics
# ----------------------------
cb_pred_test = np.expm1(final_cb.predict(X_test))
cb_true_test = np.expm1(y_test)
cb_m = metrics_full_and_clipped(cb_true_test, cb_pred_test, clip_lo=CLIP_LO, clip_hi=CLIP_HI)
print(f"CATBOOST TEST RMSE ($): {cb_m['full']['rmse']:,.0f}")
display(metrics_to_df(cb_m, "CatBoost (Test)"))
# ----------------------------
# TRAIN split metrics
# ----------------------------
cb_pred_train = np.expm1(final_cb.predict(X_train))
cb_true_train = np.expm1(y_train)
cb_tr = metrics_full_and_clipped(cb_true_train, cb_pred_train, clip_lo=CLIP_LO, clip_hi=CLIP_HI)
display(metrics_to_df(cb_tr, "CatBoost (Train)"))
# ----------------------------
# VAL split metrics
# If final model was refit on TRAIN+VAL, this is no longer an untouched
# early-stopping set; it is just a diagnostic slice of the final model.
# ----------------------------
cb_pred_val = np.expm1(final_cb.predict(X_val))
cb_true_val = np.expm1(y_val)
cb_v = metrics_full_and_clipped(cb_true_val, cb_pred_val, clip_lo=CLIP_LO, clip_hi=CLIP_HI)
if cb_refit_used:
display(metrics_to_df(cb_v, "CatBoost (Val Diagnostic)"))
else:
display(metrics_to_df(cb_v, "CatBoost (Val)"))
# ----------------------------
# Train+Val metrics for comparison
# ----------------------------
X_trainval_cb = pd.concat([X_train, X_val], axis=0)
y_trainval_cb = pd.concat([y_train, y_val], axis=0)
cb_pred_trainval = np.expm1(final_cb.predict(X_trainval_cb))
cb_true_trainval = np.expm1(y_trainval_cb)
cb_tv = metrics_full_and_clipped(cb_true_trainval, cb_pred_trainval, clip_lo=CLIP_LO, clip_hi=CLIP_HI)
display(metrics_to_df(cb_tv, "CatBoost (Train+Val)"))
# ----------------------------
# Feature Importance
# ----------------------------
feature_names_cb = None
feature_cols_path_eval = RUN_DIR / "feature_columns.json" if RUN_DIR is not None else None
if feature_cols_path_eval is not None and feature_cols_path_eval.exists():
feature_names_cb = json.loads(feature_cols_path_eval.read_text())
elif FEATURE_COLS_PATH.exists():
feature_names_cb = json.loads(FEATURE_COLS_PATH.read_text())
else:
feature_names_cb = list(X_train.columns)
importances = final_cb.get_feature_importance()
fi = (
pd.DataFrame({"feature": feature_names_cb, "importance": importances})
.sort_values("importance", ascending=False)
.reset_index(drop=True)
)
display(fi.head(25))
# ----------------------------
# Globals for metrics writer
# ----------------------------
cb_test_full = cb_m["full"]
cb_test_clipped = cb_m["clipped"]
cb_trainval_full = cb_tv["full"]
cb_trainval_clipped = cb_tv["clipped"]
cb_train_full = cb_tr["full"]
cb_train_clipped = cb_tr["clipped"]
cb_val_full = cb_v["full"]
cb_val_clipped = cb_v["clipped"]
```
#### CatBoost Interpretation
CatBoost is the **selected final model** for this project, achieving the best performance across all metrics.
**Training process**: Hyperparameters were selected using the training split with cross-validation via a staged grid search to balance performance and computational cost. A validation split was then used for early stopping to automatically select the optimal ensemble size. After model selection was finalized, the final model was refit on the combined train+validation data and evaluated on the held-out test set.
**Performance**: CatBoost cuts Ridge's test MAE by over $1,000 ($1,916 vs. $3,011) and reduces RMSE by nearly 50% ($3,935 vs. $7,824). The clipped test RMSE of $2,665 means that for the vast majority of vehicles, predictions are within ~$2,700 of the actual price — well within the normal range of market variability for used cars.
**Feature importance highlights**: CatBoost's built-in feature importance reveals that `age` (19.0%) and `mileage` (14.3%) are the dominant predictors, followed by `model` (11.0%) and `manufacturer` (9.4%). This aligns with domain knowledge — depreciation (age + mileage) is the primary driver of used-car pricing, while make and model capture brand and segment effects.
Notably, `mpg_avg` (8.1%) ranks higher than `engine_cylinders` (6.1%), suggesting that fuel efficiency carries a meaningful price signal beyond what engine size alone captures. The `luxury_age_interaction` feature (3.2%) provides modest additional signal beyond the `is_luxury_brand` flag (6.4%) and `age` (12.0%) alone, suggesting that luxury depreciation patterns differ enough from those of mass-market vehicles to justify the interaction term.
### FT-Transformer (Learned Embeddings + Attention)
#### FT-Transformer Setup
```{python}
#| code-summary: "FT-Transformer setup: reproducibility seeds and configuration"
# ----------------------------
# Step 0: Reproducibility
# ----------------------------
SEED = 42
tf.keras.utils.set_random_seed(SEED)
np.random.seed(SEED)
```
```{python}
# ----------------------------
# Step 1: Config
# ----------------------------
FT_CFG = {
# training
"batch_full": 512,
"epochs_full": 120,
"batch_smoke": 512,
"epochs_smoke": 5,
# early stopping
"es_patience_full": 20,
"es_patience_smoke": 3,
# optimization
"lr": 4e-4, # base LR (peak after warmup)
"min_lr": 1e-6, # floor for cosine tail
"weight_decay": 1e-4,
"clipnorm": 1.0,
# Huber loss instead of MSE: the dataset has price outliers (exotics,
# collector cars) that can dominate squared-error gradients. Huber
# transitions from quadratic to linear loss beyond delta, making
# training more robust to extreme residuals without fully discarding
# them the way MAE would.
"huber_delta": 1.0,
# transformer
"d_token": 96,
"n_blocks": 3,
"n_heads": 8,
"attn_dropout": 0.10,
"ff_dropout": 0.10,
"resid_dropout": 0.05,
"ff_mult": 4, # FFN hidden = ff_mult * d_token
# numeric tokenization
"num_tokens": 1,
# embedding handling
"embed_dropout": 0.0,
"head_dropout": 0.1,
# warmup
"warmup_frac": 0.05,
# prediction
"pred_batch": 4096,
# optional smoke subsample
"smoke_subsample": True,
"smoke_train_n": 15000,
"smoke_val_n": 5000,
}
# ----------------------------
# Tuning controls
# ----------------------------
TUNE = False # master switch
TUNE_WHEN = "full" # "smoke" | "full" | "both"
TUNER_KIND = "bayes" # "bayes" or "random"
ACTIVE_TUNING_ROUND = "round_4" # or "round_1", "round_2a", "round_2b", "round_3", "round_4"
TUNER_MAX_TRIALS = 8 # start small; increase later -- did 20 for full run
TUNER_EXECUTIONS_PER_TRIAL = 1
# how long each tuning trial trains (keep short; Step 6 is the real training)
TUNER_EPOCHS_SMOKE = 6
TUNER_EPOCHS_FULL = 15 # was 25 for full run
# early stopping inside trials (short + stable)
TUNER_PATIENCE_SMOKE = 2
TUNER_PATIENCE_FULL = 4 # was 6 for full run
# what to optimize during tuning
TUNER_OBJECTIVE = "val_loss" # keep aligned with restore_best_weights on val_loss
# ----------------------------
# Paths Check Helpers
# ----------------------------
def _keras_latest_exists() -> bool:
return (
KERAS_LATEST_WEIGHTS_PATH.exists()
and KERAS_LATEST_RUN_INFO_PATH.exists()
and KERAS_LATEST_TRAIN_MEDIANS_PATH.exists()
and KERAS_LATEST_NUM_NORM_STATS_PATH.exists()
and KERAS_LATEST_LOOKUP_VOCABS_PATH.exists()
)
def _touches_latest() -> bool:
return TRAIN_MODE == "full"
```
#### FT-Transformer Model Preprocessing
```{python}
#| code-summary: "FT-Transformer preprocessing: numeric normalization, categorical vocabulary encoding"
# ----------------------------
# Step 2: Prepare train/val/test (NN copies) + imputations
# ----------------------------
# Model architecture: FT-Transformer style tabular model
# Numeric features are projected into token embeddings and combined
# with categorical embeddings before passing through transformer blocks.
X_train_nn = X_train.copy()
X_val_nn = X_val.copy()
X_test_nn = X_test.copy()
missing_indicator_cols = []
for col in ["engine_liters", "engine_cylinders"]:
if col in X_train_nn.columns:
miss = f"{col}_missing"
for df_ in (X_train_nn, X_val_nn, X_test_nn):
df_[miss] = df_[col].isna().astype("int64")
missing_indicator_cols.append(miss)
for miss in missing_indicator_cols:
if miss not in num_cols_nn:
num_cols_nn.append(miss)
# Numeric impute using TRAIN medians only
train_medians = X_train_nn[num_cols_nn].median(numeric_only=True)
for df_ in (X_train_nn, X_val_nn, X_test_nn):
df_[num_cols_nn] = df_[num_cols_nn].fillna(train_medians)
# Manual numeric normalization using TRAIN statistics only
train_num_mean = X_train_nn[num_cols_nn].mean()
train_num_var = X_train_nn[num_cols_nn].var(ddof=0)
train_num_std = np.sqrt(np.maximum(train_num_var.to_numpy(dtype=np.float64), 1e-12))
train_num_std = pd.Series(train_num_std, index=num_cols_nn)
for df_ in (X_train_nn, X_val_nn, X_test_nn):
df_[num_cols_nn] = (df_[num_cols_nn] - train_num_mean) / train_num_std
# Categorical fill/cast
for c in cat_cols_nn:
for df_ in (X_train_nn, X_val_nn, X_test_nn):
df_[c] = df_[c].fillna("unknown").astype(str)
y_train_nn = y_train.to_numpy().astype("float32")
y_val_nn = y_val.to_numpy().astype("float32")
y_test_nn = y_test.to_numpy().astype("float32")
print("Rows:", {"train": len(X_train_nn), "val": len(X_val_nn), "test": len(X_test_nn)})
print("NN numeric cols:", len(num_cols_nn), "| NN cat cols:", len(cat_cols_nn))
# ----------------------------
# Step 3: Prepare categorical vocabularies
# ----------------------------
SHOULD_TRAIN_KERAS = (
(TRAIN_MODE == "smoke") or
(TRAIN_MODE == "full" and (RETRAIN_KERAS or (not _keras_latest_exists())))
)
LOOKUP_VOCABS = {}
if SHOULD_TRAIN_KERAS:
for c in cat_cols_nn:
lk = layers.StringLookup(
output_mode="int",
mask_token=None,
num_oov_indices=1,
name=f"{c}_lookup",
)
lk.adapt(X_train_nn[c].to_numpy(dtype=str))
vocab = lk.get_vocabulary(include_special_tokens=False)
vocab = [str(v) for v in vocab]
LOOKUP_VOCABS[c] = vocab
else:
print("⏭️ Skipping adapt — will load existing latest weights/artifacts.")
```
#### FT-Transformer Model Building
```{python}
#| code-summary: "FT-Transformer architecture: embedding layers, multi-head attention blocks, output head"
# ----------------------------
# Step 4: Convert pandas -> Keras-friendly input dicts
# ----------------------------
def to_input_dict_np(Xdf: pd.DataFrame) -> dict:
out = {"numeric": Xdf[num_cols_nn].to_numpy(dtype=np.float32, copy=True)}
for c in cat_cols_nn:
out[c] = Xdf[c].astype(str).to_numpy(copy=False) # (N,)
return out
def to_input_dict_tf(inputs_np: dict) -> dict:
out = {"numeric": tf.convert_to_tensor(inputs_np["numeric"], dtype=tf.float32)}
for c in cat_cols_nn:
out[c] = tf.convert_to_tensor(inputs_np[c].astype(str), dtype=tf.string)
return out
def assert_nonempty_inputs(inputs: dict, y: np.ndarray, name: str):
if len(y) == 0:
raise ValueError(f"{name}: y is empty")
if "numeric" not in inputs:
raise ValueError(f"{name}: missing numeric input")
if int(inputs["numeric"].shape[0]) == 0:
raise ValueError(f"{name}: numeric input has zero rows")
n_rows = int(inputs["numeric"].shape[0])
for k, v in inputs.items():
if int(v.shape[0]) != n_rows:
raise ValueError(
f"{name}: input '{k}' row count {int(v.shape[0])} does not match numeric row count {n_rows}"
)
if len(y) != n_rows:
raise ValueError(f"{name}: y row count {len(y)} does not match input row count {n_rows}")
def make_tf_dataset(
inputs: dict,
y: np.ndarray,
*,
batch_size: int,
training: bool,
drop_remainder: bool = True,
) -> tf.data.Dataset:
assert_nonempty_inputs(inputs, y, "dataset_build")
ds = tf.data.Dataset.from_tensor_slices((inputs, y))
if training:
ds = ds.shuffle(
buffer_size=min(len(y), 10000),
seed=SEED,
reshuffle_each_iteration=True,
)
ds = ds.batch(int(batch_size), drop_remainder=drop_remainder)
ds = ds.prefetch(tf.data.AUTOTUNE)
return ds
train_inputs_tf = to_input_dict_tf(to_input_dict_np(X_train_nn))
val_inputs_tf = to_input_dict_tf(to_input_dict_np(X_val_nn))
test_inputs_tf = to_input_dict_tf(to_input_dict_np(X_test_nn))
# ==========================================================
# Dollar RMSE metric
# ==========================================================
Y_LOG_MIN = float(np.min(y_train_nn))
Y_LOG_MAX = float(np.max(y_train_nn))
# optional pad
Y_LOG_MIN -= 0.5
Y_LOG_MAX += 0.5
@tf.keras.utils.register_keras_serializable()
class RMSEDollars(tf.keras.metrics.Metric):
def __init__(self, y_log_min, y_log_max, name="rmse_dollars", **kwargs):
super().__init__(name=name, **kwargs)
self.y_log_min = float(y_log_min)
self.y_log_max = float(y_log_max)
self.sse = self.add_weight(name="sse", initializer="zeros", dtype=tf.float64)
self.n = self.add_weight(name="n", initializer="zeros", dtype=tf.float64)
def update_state(self, y_true_log, y_pred_log, sample_weight=None):
y_true_log = tf.cast(y_true_log, tf.float64)
y_pred_log = tf.cast(y_pred_log, tf.float64)
# make shapes match (B,)
y_true_log = tf.reshape(y_true_log, [-1]) # (B,)
y_pred_log = tf.reshape(y_pred_log, [-1]) # (B,)
y_true_log = tf.clip_by_value(y_true_log, self.y_log_min, self.y_log_max)
y_pred_log = tf.clip_by_value(y_pred_log, self.y_log_min, self.y_log_max)
y_true = tf.math.expm1(y_true_log)
y_pred = tf.math.expm1(y_pred_log)
sq = tf.square(y_true - y_pred)
if sample_weight is not None:
w = tf.cast(sample_weight, tf.float64)
w = tf.reshape(w, [-1])
sq = sq * w
self.n.assign_add(tf.reduce_sum(w))
else:
self.n.assign_add(tf.cast(tf.size(sq), tf.float64))
self.sse.assign_add(tf.reduce_sum(sq))
def result(self):
return tf.sqrt(self.sse / tf.maximum(self.n, 1.0))
def reset_state(self):
self.sse.assign(0.0)
self.n.assign(0.0)
def get_config(self):
return {"y_log_min": self.y_log_min, "y_log_max": self.y_log_max, **super().get_config()}
# ==========================================================
# Warmup + Cosine LR schedule
# ==========================================================
# Warmup + cosine annealing schedule: the warmup phase (default 5% of
# steps) lets embeddings and layer norms stabilize before the full
# learning rate kicks in — important for transformer architectures
# where early large updates can cause training instability. The cosine
# decay provides a smooth LR reduction that avoids the sharp drops
# of step-based schedules, and typically leads to better final
# convergence for models trained with a fixed epoch budget.
@tf.keras.utils.register_keras_serializable(package="erin")
class WarmupCosine(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, base_lr, warmup_steps, total_steps, min_lr=1e-6, name=None):
super().__init__()
self.base_lr = float(base_lr)
self.warmup_steps = int(warmup_steps)
self.total_steps = int(total_steps)
self.min_lr = float(min_lr)
self.name = name
def __call__(self, step):
step = tf.cast(step, tf.float32)
warmup_steps = tf.cast(self.warmup_steps, tf.float32)
total_steps = tf.cast(self.total_steps, tf.float32)
warmup_lr = self.base_lr * (step / tf.maximum(1.0, warmup_steps))
progress = (step - warmup_steps) / tf.maximum(1.0, (total_steps - warmup_steps))
progress = tf.clip_by_value(progress, 0.0, 1.0)
cosine_lr = self.min_lr + 0.5 * (self.base_lr - self.min_lr) * (
1.0 + tf.cos(np.pi * progress)
)
return tf.where(step < warmup_steps, warmup_lr, cosine_lr)
def get_config(self):
return {
"base_lr": self.base_lr,
"warmup_steps": self.warmup_steps,
"total_steps": self.total_steps,
"min_lr": self.min_lr,
"name": self.name,
}
@classmethod
def from_config(cls, config):
return cls(**config)
# ----------------------------
# Step 5: FT-Transformer blocks + model builder
# ----------------------------
def _ffn(x, d_token: int, ff_mult: int, dropout: float, *, prefix: str):
d_hidden = int(d_token * ff_mult)
x2 = layers.Dense(
d_hidden,
activation=tf.keras.activations.gelu,
name=f"{prefix}_dense_1",
)(x)
x2 = layers.Dropout(dropout, name=f"{prefix}_inner_dropout")(x2)
x2 = layers.Dense(d_token, name=f"{prefix}_dense_2")(x2)
return x2
def _transformer_block(x, *, d_token, n_heads, attn_dropout, ff_dropout, resid_dropout, block_idx: int):
prefix = f"block_{block_idx}"
# PreNorm attention
xn = layers.LayerNormalization(name=f"{prefix}_attn_ln")(x)
attn = layers.MultiHeadAttention(
num_heads=int(n_heads),
key_dim=int(d_token // n_heads),
dropout=float(attn_dropout),
name=f"{prefix}_mha",
)(xn, xn)
attn = layers.Dropout(float(resid_dropout), name=f"{prefix}_attn_dropout")(attn)
x = layers.Add(name=f"{prefix}_attn_add")([x, attn])
# PreNorm FFN
xn = layers.LayerNormalization(name=f"{prefix}_ffn_ln")(x)
ff = _ffn(
xn,
int(d_token),
int(FT_CFG["ff_mult"]),
float(ff_dropout),
prefix=f"{prefix}_ffn",
)
ff = layers.Dropout(float(resid_dropout), name=f"{prefix}_ffn_dropout")(ff)
x = layers.Add(name=f"{prefix}_ffn_add")([x, ff])
return x
def build_ft_transformer_model(lr_schedule):
# Inputs
numeric_in = keras.Input(shape=(len(num_cols_nn),), name="numeric", dtype=tf.float32)
cat_in = {c: keras.Input(shape=(), name=c, dtype=tf.string) for c in cat_cols_nn}
# numeric_in is already standardized outside the model
x_num = numeric_in
d_token = int(FT_CFG["d_token"])
num_tokens = int(FT_CFG.get("num_tokens", 1))
# FT-Transformer architecture choices:
# - Single numeric token (num_tokens=1): all numeric features are
# projected into one d_token-dimensional vector. Tuning round 3
# tested num_tokens=4 (one token per feature group), which improved
# MAE/MedianAE but worsened full-range RMSE — the added capacity
# fit outliers more aggressively without worsening the bulk of predictions.
# - Global average pooling (not CLS token): averages across all
# token positions rather than relying on a single learned CLS
# token. This is more stable for tabular data where there's no
# natural "sequence start" and every token carries a useful signal.
# Numeric tokenization
if num_tokens == 1:
num_token_block = layers.Dense(
d_token,
name="num_token_proj",
)(x_num)
num_token_block = layers.Reshape(
(1, d_token),
name="num_token_reshape",
)(num_token_block)
else:
num_token_block = layers.Dense(
num_tokens * d_token,
name=f"num_token_proj_{num_tokens}x{d_token}",
)(x_num)
num_token_block = layers.Reshape(
(num_tokens, d_token),
name=f"num_token_reshape_{num_tokens}",
)(num_token_block)
# Categorical tokens
cat_tokens = []
for c in cat_cols_nn:
lk = layers.StringLookup(
vocabulary=LOOKUP_VOCABS[c],
output_mode="int",
mask_token=None,
num_oov_indices=1,
name=f"{c}_lookup",
)
lk.set_vocabulary(LOOKUP_VOCABS[c])
ids = lk(cat_in[c])
emb = layers.Embedding(
input_dim=lk.vocabulary_size(),
output_dim=d_token,
name=f"{c}_emb_token",
)(ids)
emb = layers.Dropout(
float(FT_CFG["embed_dropout"]),
name=f"{c}_emb_dropout",
)(emb)
emb = layers.Reshape(
(1, d_token),
name=f"{c}_emb_reshape",
)(emb)
cat_tokens.append(emb)
x = layers.Concatenate(axis=1, name="token_concat")([num_token_block] + cat_tokens)
for i in range(int(FT_CFG["n_blocks"])):
x = _transformer_block(
x,
d_token=d_token,
n_heads=int(FT_CFG["n_heads"]),
attn_dropout=float(FT_CFG["attn_dropout"]),
ff_dropout=float(FT_CFG["ff_dropout"]),
resid_dropout=float(FT_CFG["resid_dropout"]),
block_idx=i,
)
x = layers.LayerNormalization(name="final_ln")(x)
x = layers.GlobalAveragePooling1D(name="token_mean_pool")(x)
x = layers.Dense(
d_token,
activation=tf.keras.activations.gelu,
name="head_dense",
)(x)
x = layers.Dropout(
float(FT_CFG.get("head_dropout", 0.10)),
name="head_dropout",
)(x)
y0 = float(np.median(y_train_nn))
out = layers.Dense(
1,
bias_initializer=tf.keras.initializers.Constant(y0),
name="pred_log1p",
)(x)
model = keras.Model(
inputs={"numeric": numeric_in, **cat_in},
outputs=out,
name="ft_transformer_reg",
)
opt = keras.optimizers.AdamW(
learning_rate=lr_schedule,
weight_decay=float(FT_CFG["weight_decay"]),
clipnorm=float(FT_CFG["clipnorm"]),
)
model.compile(
optimizer=opt,
loss=keras.losses.Huber(delta=float(FT_CFG["huber_delta"])),
metrics=[
keras.metrics.RootMeanSquaredError(name="rmse_log"),
RMSEDollars(Y_LOG_MIN, Y_LOG_MAX, name="rmse_dollars"),
],
)
return model
```
#### FT-Transformer Model Optional Tuning
```{python}
# ==========================================================
# Step 5.5: Optional KerasTuner
# ==========================================================
# ----------------------------------------------------------
# 1) Prepare smoke/full datasets
# ----------------------------------------------------------
def get_run_data_for_mode(train_mode: str):
"""
Returns:
train_inputs_run, val_inputs_run, y_train_run, y_val_run
using your smoke subsample settings when train_mode == "smoke".
"""
if (train_mode == "smoke") and FT_CFG.get("smoke_subsample", False):
rs = np.random.RandomState(SEED)
ntr = min(int(FT_CFG["smoke_train_n"]), len(y_train_nn))
nva = min(int(FT_CFG["smoke_val_n"]), len(y_val_nn))
idx_tr = rs.choice(len(y_train_nn), size=ntr, replace=False)
idx_va = rs.choice(len(y_val_nn), size=nva, replace=False)
train_inputs_run = {k: tf.gather(v, idx_tr, axis=0) for k, v in train_inputs_tf.items()}
val_inputs_run = {k: tf.gather(v, idx_va, axis=0) for k, v in val_inputs_tf.items()}
y_train_run = y_train_nn[idx_tr]
y_val_run = y_val_nn[idx_va]
print(f"🧪 {train_mode} subsample: train={ntr:,} val={nva:,}")
return train_inputs_run, val_inputs_run, y_train_run, y_val_run
# full (or smoke without subsample)
return train_inputs_tf, val_inputs_tf, y_train_nn, y_val_nn
# ----------------------------------------------------------
# 2) One place to compute schedule + build model (same as Step 6)
# ----------------------------------------------------------
def build_model_with_cfg(cfg: dict, *, n_train_rows: int, epochs: int, batch_size: int):
"""
Builds a compiled model using the real builder:
- same steps_per_epoch/total_steps/warmup logic as Step 6
- same WarmupCosine + build_ft_transformer_model
"""
batch_eff = min(int(batch_size), int(n_train_rows))
steps_per_epoch = int(np.ceil(n_train_rows / batch_eff))
total_steps = int(steps_per_epoch * int(epochs))
warmup_steps = max(1, int(float(cfg["warmup_frac"]) * total_steps))
lr_schedule = WarmupCosine(
base_lr=float(cfg["lr"]),
warmup_steps=warmup_steps,
total_steps=total_steps,
min_lr=float(cfg["min_lr"]),
)
# IMPORTANT: build_ft_transformer_model reads global FT_CFG
# so temporarily swap it, build, then restore.
global FT_CFG
_backup = dict(FT_CFG)
FT_CFG = dict(cfg)
try:
model = build_ft_transformer_model(lr_schedule)
finally:
FT_CFG = _backup
return model
# ----------------------------------------------------------
# Tuning search space
# Note -- full tuning applies best HP to FT_CFG only for the current run.
# To make selected values the new default baseline for future runs,
# update the original FT_CFG dictionary manually.
# Smoke tuning is sanity-only and does not overwrite FT_CFG.
# ----------------------------------------------------------
TUNING_SEARCH_SPACE = {
"round_1": {
"lr": {
"choices": [1e-4, 2e-4, 3e-4],
"dtype": "float",
"selected": 3e-4,
"notes": "was 2e-4, tuner selected 3e-4",
},
"warmup_frac": {
"choices": [0.05, 0.10, 0.15],
"dtype": "float",
"selected": 0.05,
"notes": "was 0.10, tuner selected 0.05",
},
"weight_decay": {
"choices": [0.0, 1e-4, 3e-4],
"dtype": "float",
"selected": 0.0,
"notes": "was 0.0 and tuning kept it at 0.0",
},
"ff_dropout": {
"choices": [0.10, 0.15, 0.20],
"dtype": "float",
"selected": 0.10,
"notes": "was 0.15, tuner selected 0.10",
},
"attn_dropout": {
"choices": [0.05, 0.10, 0.15],
"dtype": "float",
"selected": 0.10,
"notes": "tuning kept value at 0.10",
},
"embed_dropout": {
"choices": [0.00, 0.05, 0.10],
"dtype": "float",
"selected": 0.00,
"notes": "was 0.05, tuner selected 0.00",
},
},
"round_2a": {
"batch_full": {
"choices": [512, 1024, 2048, 4096],
"dtype": "int",
"selected": 512,
"notes": "was 2048, tuner selected 512",
},
"lr": {
"choices": [1e-4, 2e-4, 3e-4, 4e-4],
"dtype": "float",
"selected": 4e-4,
"notes": "was 3e-4, tuner selected 4e-4",
},
"weight_decay": {
"choices": [0.0, 1e-5, 3e-5, 1e-4],
"dtype": "float",
"selected": 1e-4,
"notes": "was 0.0, tuner selected 1e-4",
},
},
"round_2b": {
"notes_1": "Did not select due to higher performance cost and no meaningful improvement.",
"notes_2": "larger-capacity variant, better MAE / clipped performance, worse full test RMSE",
"d_token": {
"choices": [96, 128],
"dtype": "int",
"selected": 128,
"notes": "baseline was 96",
},
"n_blocks": {
"choices": [3, 4],
"dtype": "int",
"selected": 4,
"notes": "baseline was 3",
},
"resid_dropout": {
"choices": [0.0, 0.05, 0.10],
"dtype": "float",
"selected": 0.0,
"notes": "baseline was 0.05",
},
"head_dropout": {
"choices": [0.0, 0.05, 0.10, 0.15],
"dtype": "float",
"selected": 0.10,
"notes": "baseline already 0.10",
},
},
"round_3": {
"notes_1": "Did not select due to higher performance cost and no meaningful improvement.",
"notes_2": "better MAE / median AE / clipped performance, worse full test RMSE",
"num_tokens": {
"choices": [1, 4],
"dtype": "int",
"selected": 4,
"notes": "was 1, selected 4 -- kept at 1",
}
},
"round_4": {
"notes": "This was the new best round",
"weight_decay": {
"choices": [3e-5, 1e-4, 3e-4],
"dtype": "float",
"selected": 1e-4,
"notes": "tuning kept value at 1e-4",
},
"ff_dropout": {
"choices": [0.05, 0.10, 0.15],
"dtype": "float",
"selected": 0.1,
"notes": "tuning kept value at 0.1",
},
"huber_delta": {
"choices": [1.0, 2.0, 3.0],
"dtype": "float",
"selected": 1.0,
"notes": "was 2.0, tuner selected 1.0 -- now baked in",
},
}
}
def get_active_tuning_round_dict() -> dict:
if not TUNE:
return {}
if ACTIVE_TUNING_ROUND not in TUNING_SEARCH_SPACE:
raise ValueError(
f"ACTIVE_TUNING_ROUND='{ACTIVE_TUNING_ROUND}' not found in TUNING_SEARCH_SPACE. "
f"Available rounds: {list(TUNING_SEARCH_SPACE.keys())}"
)
round_dict = TUNING_SEARCH_SPACE[ACTIVE_TUNING_ROUND]
return {
k: v for k, v in round_dict.items()
if isinstance(v, dict) and "choices" in v
}
def apply_best_hp_to_ft_cfg(ft_cfg: dict, best_hp) -> dict:
active_round = get_active_tuning_round_dict()
applied_updates = {}
for k, param_info in active_round.items():
if k in best_hp.values:
val = best_hp.get(k)
dtype = param_info.get("dtype", None)
if dtype == "int":
val = int(val)
elif dtype == "float":
val = float(val)
ft_cfg[k] = val
applied_updates[k] = val
return applied_updates
# ----------------------------------------------------------
# 3) Tuner hyperparameter space
# - Round 1 is baked into FT_CFG already
# - Round 2 (a and b) tunes capacity + regularization + batch size
# ----------------------------------------------------------
def apply_hp_to_cfg(base_cfg: dict, hp: "kt.HyperParameters") -> dict:
cfg = dict(base_cfg)
active_round = get_active_tuning_round_dict()
for param_name, param_info in active_round.items():
val = hp.Choice(param_name, param_info["choices"])
if param_info["dtype"] == "int":
val = int(val)
elif param_info["dtype"] == "float":
val = float(val)
cfg[param_name] = val
return cfg
def summarize_tuning_changes(base_cfg: dict, tuned_cfg: dict) -> dict:
changes = {}
for k in tuned_cfg:
base_val = base_cfg.get(k)
tuned_val = tuned_cfg.get(k)
if base_val != tuned_val:
changes[k] = {
"baseline": base_val,
"selected": tuned_val,
"changed": True,
}
else:
changes[k] = {
"baseline": base_val,
"selected": tuned_val,
"changed": False,
}
return changes
def summarize_metric_improvement(baseline_metrics: dict, tuned_metrics: dict) -> dict:
out = {}
for k in tuned_metrics:
if k in baseline_metrics:
base = baseline_metrics[k]
tuned = tuned_metrics[k]
if base is not None and tuned is not None:
out[k] = {
"baseline": base,
"tuned": tuned,
"delta": tuned - base,
"improved": tuned < base
}
return out
def get_tuning_metadata_for_run(
best_hp=None,
mode=None,
trial_epochs=None,
base_cfg=None,
tuned_cfg=None,
baseline_metrics=None,
tuned_metrics=None,
) -> dict:
active_round_dict = get_active_tuning_round_dict() if TUNE else {}
change_summary = None
metric_summary = None
if base_cfg and tuned_cfg:
change_summary = summarize_tuning_changes(base_cfg, tuned_cfg)
if baseline_metrics and tuned_metrics:
metric_summary = summarize_metric_improvement(
baseline_metrics,
tuned_metrics
)
return {
"enabled": bool(TUNE),
"active_round": ACTIVE_TUNING_ROUND if TUNE else None,
"mode_requested": TUNE_WHEN,
"mode_this_run": mode,
"tuner_kind": TUNER_KIND if TUNE else None,
"objective": TUNER_OBJECTIVE if TUNE else None,
"max_trials": int(TUNER_MAX_TRIALS) if TUNE else None,
"executions_per_trial": int(TUNER_EXECUTIONS_PER_TRIAL) if TUNE else None,
"epochs_per_trial": int(trial_epochs) if (TUNE and trial_epochs is not None) else None,
"patience_smoke": int(TUNER_PATIENCE_SMOKE) if TUNE else None,
"patience_full": int(TUNER_PATIENCE_FULL) if TUNE else None,
"search_space": active_round_dict,
"best_hp": dict(best_hp.values) if best_hp is not None else None,
"param_changes": change_summary,
"metric_change": metric_summary,
}
# ----------------------------------------------------------
# 4) HyperModel so we can tune batch size per trial
# ----------------------------------------------------------
class FTHyperModel(kt.HyperModel):
def __init__(self, base_cfg: dict, *, mode: str, n_train_rows: int, epochs: int):
self.base_cfg = dict(base_cfg)
self.mode = str(mode)
self.n_train_rows = int(n_train_rows)
self.epochs = int(epochs)
def build(self, hp):
tf.keras.backend.clear_session()
cfg = apply_hp_to_cfg(self.base_cfg, hp)
# batch affects steps/epoch -> total_steps -> lr schedule
batch_size = int(cfg["batch_smoke"] if self.mode == "smoke" else cfg["batch_full"])
batch_eff = min(batch_size, self.n_train_rows)
return build_model_with_cfg(
cfg,
n_train_rows=self.n_train_rows,
epochs=self.epochs,
batch_size=batch_eff,
)
def fit(self, hp, model, x, y, validation_data, **kwargs):
cfg = apply_hp_to_cfg(self.base_cfg, hp)
batch_size = int(cfg["batch_smoke"] if self.mode == "smoke" else cfg["batch_full"])
batch_eff = min(batch_size, int(len(y)))
val_x, val_y = validation_data
assert_nonempty_inputs(x, y, "tuner_train")
assert_nonempty_inputs(val_x, val_y, "tuner_val")
train_ds = make_tf_dataset(
x,
y,
batch_size=batch_eff,
training=True,
drop_remainder=True,
)
val_ds = make_tf_dataset(
val_x,
val_y,
batch_size=batch_eff,
training=False,
drop_remainder=False,
)
patience = int(TUNER_PATIENCE_SMOKE if self.mode == "smoke" else TUNER_PATIENCE_FULL)
cb = keras.callbacks.EarlyStopping(
monitor=TUNER_OBJECTIVE,
mode="min",
patience=patience,
restore_best_weights=True,
)
return model.fit(
train_ds,
validation_data=val_ds,
epochs=self.epochs,
callbacks=[cb],
verbose=0,
)
# ----------------------------------------------------------
# 5) Run tuner (reuses get_run_data_for_mode)
# ----------------------------------------------------------
def run_tuner_for_mode(mode: str):
"""
Runs tuning for 'smoke' or 'full' using the SAME run inputs the pipeline uses.
Returns best_hp (kt.HyperParameters) or None if tuning is skipped.
"""
if not TUNE:
return None
if (TUNE_WHEN == "smoke" and mode != "smoke") or (TUNE_WHEN == "full" and mode != "full"):
return None
if TUNE_WHEN not in ("smoke", "full", "both"):
return None
# Use the exact run data this mode will use
train_inputs_run, val_inputs_run, y_train_run, y_val_run = get_run_data_for_mode(mode)
# Trial epoch budget by mode
trial_epochs = int(TUNER_EPOCHS_SMOKE if mode == "smoke" else TUNER_EPOCHS_FULL)
# tuner directory
tuner_dir = KERAS_DIR / "tuner"
tuner_dir.mkdir(parents=True, exist_ok=True)
tuner_project = f"ft_{TUNER_KIND}_{mode}_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
hypermodel = FTHyperModel(
FT_CFG,
mode=mode,
n_train_rows=int(len(y_train_run)),
epochs=trial_epochs,
)
objective = kt.Objective(TUNER_OBJECTIVE, direction="min")
if TUNER_KIND == "bayes":
tuner = kt.BayesianOptimization(
hypermodel=hypermodel,
objective=objective,
max_trials=int(TUNER_MAX_TRIALS),
executions_per_trial=int(TUNER_EXECUTIONS_PER_TRIAL),
directory=str(tuner_dir),
project_name=tuner_project,
overwrite=True,
)
else:
tuner = kt.RandomSearch(
hypermodel=hypermodel,
objective=objective,
max_trials=int(TUNER_MAX_TRIALS),
executions_per_trial=int(TUNER_EXECUTIONS_PER_TRIAL),
directory=str(tuner_dir),
project_name=tuner_project,
overwrite=True,
)
print(f"🔎 Tuning START | mode={mode} | trials={TUNER_MAX_TRIALS} | epochs/trial={trial_epochs}")
tuner.search(
train_inputs_run, y_train_run,
validation_data=(val_inputs_run, y_val_run),
verbose=0,
)
best_hp = tuner.get_best_hyperparameters(1)[0]
# Save for reproducibility
active_round_dict = get_active_tuning_round_dict()
best_hp_info = {
"mode": mode,
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"active_round": ACTIVE_TUNING_ROUND,
"tuner_kind": TUNER_KIND,
"objective": TUNER_OBJECTIVE,
"max_trials": int(TUNER_MAX_TRIALS),
"executions_per_trial": int(TUNER_EXECUTIONS_PER_TRIAL),
"epochs_per_trial": int(trial_epochs),
"patience": int(TUNER_PATIENCE_SMOKE if mode == "smoke" else TUNER_PATIENCE_FULL),
"search_space": active_round_dict,
"best_hp": dict(best_hp.values),
}
atomic_write_json(Path(tuner_dir) / f"best_hp_{mode}_{tuner_project}.json", best_hp_info)
print("✅ Tuning DONE | best_hp:", best_hp.values)
return best_hp
# ----------------------------------------------------------
# 6) Apply tuning results to FT_CFG
# - smoke tuning: do NOT overwrite FT_CFG (sanity only)
# - full tuning: DO overwrite FT_CFG so Step 6 uses it
# ----------------------------------------------------------
best_hp = None
if TUNE:
if TUNE_WHEN in ("smoke", "both") and TRAIN_MODE == "smoke":
best_hp = run_tuner_for_mode("smoke")
print("ℹ️ Smoke tuning is sanity-only: FT_CFG NOT overwritten.")
elif TUNE_WHEN in ("full", "both") and TRAIN_MODE == "full":
best_hp = run_tuner_for_mode("full")
if best_hp is not None:
applied_updates = apply_best_hp_to_ft_cfg(FT_CFG, best_hp)
print("✅ FT_CFG updated (for Step 6 full training):")
print(applied_updates)
```
#### FT-Transformer Model Training
```{python}
#| code-summary: "FT-Transformer training: learning rate schedule, early stopping, checkpoint management"
# ----------------------------
# Step 6: Train or Load
# ----------------------------
history = None
KERAS_RUN_DIR = None
model = None
# Canonical evaluation references
KERAS_EVAL_ARTIFACT_DIR = None # points to KERAS_DIR for latest, or run dir for versioned run
KERAS_EVAL_ARTIFACT_KIND = None # "latest" | "run"
KERAS_MODEL_SOURCE = None # "latest_loaded" | "trained_this_run" | None
def make_callbacks(train_mode: str):
ES_PAT = FT_CFG["es_patience_smoke"] if train_mode == "smoke" else FT_CFG["es_patience_full"]
return [
keras.callbacks.EarlyStopping(
monitor="val_loss",
mode="min",
patience=int(ES_PAT),
restore_best_weights=True,
),
]
def _keras_artifact_paths(base_dir: Path, kind: str) -> dict:
if kind == "latest":
return {
"weights": KERAS_LATEST_WEIGHTS_PATH,
"run_info": KERAS_LATEST_RUN_INFO_PATH,
"train_medians": KERAS_LATEST_TRAIN_MEDIANS_PATH,
"num_norm_stats": KERAS_LATEST_NUM_NORM_STATS_PATH,
"lookup_vocabs": KERAS_LATEST_LOOKUP_VOCABS_PATH,
"history": KERAS_LATEST_HISTORY_PATH,
"loss_plot": KERAS_LATEST_LOSS_PLOT_PATH,
"rmse_plot": KERAS_LATEST_RMSE_PLOT_PATH,
}
elif kind == "run":
return {
"weights": base_dir / "keras_model.weights.h5",
"run_info": base_dir / "run_info.json",
"train_medians": base_dir / "train_medians.json",
"num_norm_stats": base_dir / "num_norm_stats.json",
"lookup_vocabs": base_dir / "lookup_vocabs.json",
"history": base_dir / "keras_history.json",
"loss_plot": base_dir / "keras_training_loss.png",
"rmse_plot": base_dir / "keras_training_rmse.png",
}
else:
raise ValueError(f"Unknown Keras artifact kind: {kind}")
def _save_keras_rebuild_artifacts(
*,
base_dir: Path,
kind: str,
run_info: dict,
train_medians_series: pd.Series,
train_num_mean_series: pd.Series,
train_num_std_series: pd.Series,
lookup_vocabs: dict,
):
p = _keras_artifact_paths(base_dir, kind)
atomic_write_json(p["run_info"], run_info)
atomic_write_json(
p["train_medians"],
{k: float(v) for k, v in train_medians_series.to_dict().items()}
)
atomic_write_json(
p["num_norm_stats"],
{
"mean": {k: float(v) for k, v in train_num_mean_series.to_dict().items()},
"std": {k: float(v) for k, v in train_num_std_series.to_dict().items()},
}
)
atomic_write_json(
p["lookup_vocabs"],
lookup_vocabs
)
def _load_keras_rebuild_artifacts(*, base_dir: Path, kind: str) -> dict:
p = _keras_artifact_paths(base_dir, kind)
run_info = json.loads(p["run_info"].read_text())
train_medians_saved = json.loads(p["train_medians"].read_text())
num_norm_stats_saved = json.loads(p["num_norm_stats"].read_text())
lookup_vocabs_saved = json.loads(p["lookup_vocabs"].read_text())
return {
"paths": p,
"run_info": run_info,
"train_medians": {k: float(v) for k, v in train_medians_saved.items()},
"num_cols": list(run_info["num_cols"]),
"cat_cols": list(run_info["cat_cols"]),
"ft_cfg": dict(run_info["ft_cfg"]),
"num_norm_mean": {k: float(v) for k, v in num_norm_stats_saved["mean"].items()},
"num_norm_std": {k: float(v) for k, v in num_norm_stats_saved["std"].items()},
"lookup_vocabs": lookup_vocabs_saved,
}
def update_tuning_history(history_path: Path, record: dict):
"""
Append one tuning record to tuning_history.json.
Creates the file if it does not exist yet.
"""
if history_path.exists():
history = json.loads(history_path.read_text())
if not isinstance(history, list):
history = []
else:
history = []
history.append(record)
atomic_write_json(history_path, history)
def _prepare_inputs_for_saved_artifacts(
Xdf: pd.DataFrame,
*,
num_cols_saved: list[str],
cat_cols_saved: list[str],
train_medians_saved: dict,
num_norm_mean_saved: dict,
num_norm_std_saved: dict,
) -> dict:
X_local = Xdf.copy()
for col in num_cols_saved:
if col not in X_local.columns and col.endswith("_missing"):
base = col[:-8]
if base in X_local.columns:
X_local[col] = X_local[base].isna().astype("int64")
missing_num = [c for c in num_cols_saved if c not in X_local.columns]
missing_cat = [c for c in cat_cols_saved if c not in X_local.columns]
if missing_num:
raise ValueError(f"Missing numeric columns required by saved Keras model: {missing_num}")
if missing_cat:
raise ValueError(f"Missing categorical columns required by saved Keras model: {missing_cat}")
X_local[num_cols_saved] = X_local[num_cols_saved].fillna(train_medians_saved)
mean_s = pd.Series(num_norm_mean_saved, index=num_cols_saved)
std_s = pd.Series(num_norm_std_saved, index=num_cols_saved)
X_local[num_cols_saved] = (X_local[num_cols_saved] - mean_s) / std_s
for c in cat_cols_saved:
X_local[c] = X_local[c].fillna("unknown").astype(str)
out = {
"numeric": tf.convert_to_tensor(
X_local[num_cols_saved].to_numpy(dtype=np.float32),
dtype=tf.float32
)
}
for c in cat_cols_saved:
out[c] = tf.convert_to_tensor(
X_local[c].astype(str).to_numpy(),
dtype=tf.string
)
return out
def _rebuild_and_load_keras_model_from_artifacts(*, base_dir: Path, kind: str):
art = _load_keras_rebuild_artifacts(base_dir=base_dir, kind=kind)
global FT_CFG, num_cols_nn, cat_cols_nn, LOOKUP_VOCABS
_FT_CFG_backup = dict(FT_CFG)
_num_cols_backup = list(num_cols_nn)
_cat_cols_backup = list(cat_cols_nn)
_LOOKUP_VOCABS_backup = LOOKUP_VOCABS
try:
tf.keras.backend.clear_session()
gc.collect()
FT_CFG = dict(art["ft_cfg"])
num_cols_nn = list(art["num_cols"])
cat_cols_nn = list(art["cat_cols"])
LOOKUP_VOCABS = art["lookup_vocabs"]
train_mode_saved = art["run_info"]["train_mode"]
n_train_rows_saved = int(art["run_info"]["train_rows"])
batch_eff = min(
int(FT_CFG["batch_smoke"] if train_mode_saved == "smoke" else FT_CFG["batch_full"]),
n_train_rows_saved
)
epochs_saved = int(FT_CFG["epochs_smoke"] if train_mode_saved == "smoke" else FT_CFG["epochs_full"])
steps_per_epoch = max(1, int(np.ceil(n_train_rows_saved / batch_eff)))
total_steps = max(1, int(steps_per_epoch * epochs_saved))
warmup_steps = max(1, int(float(FT_CFG["warmup_frac"]) * total_steps))
lr_schedule = WarmupCosine(
base_lr=float(FT_CFG["lr"]),
warmup_steps=warmup_steps,
total_steps=total_steps,
min_lr=float(FT_CFG["min_lr"]),
)
model_loaded = build_ft_transformer_model(lr_schedule)
model_loaded.load_weights(art["paths"]["weights"])
finally:
FT_CFG = _FT_CFG_backup
num_cols_nn = _num_cols_backup
cat_cols_nn = _cat_cols_backup
LOOKUP_VOCABS = _LOOKUP_VOCABS_backup
return model_loaded, art
print("FT-Transformer SHOULD_TRAIN_KERAS =", SHOULD_TRAIN_KERAS, "| latest exists =", _keras_latest_exists())
def _history_to_serializable_dict(history_obj) -> dict:
"""
Convert a Keras History object (or dict-like history) into plain Python
lists/floats so it can be safely written to JSON.
"""
if history_obj is None:
return {}
hist = history_obj.history if hasattr(history_obj, "history") else dict(history_obj)
out = {}
for k, v in hist.items():
if v is None:
out[k] = []
else:
out[k] = [float(x) for x in v]
return out
def _save_keras_history(history_obj, history_path: Path):
hist = _history_to_serializable_dict(history_obj)
atomic_write_json(history_path, hist)
def _load_keras_history(history_path: Path) -> dict | None:
if not history_path.exists():
return None
data = json.loads(history_path.read_text())
if not isinstance(data, dict):
return None
return data
def plot_keras_training_curves(
hist: dict,
*,
show: bool = True,
loss_plot_path: Path | None = None,
rmse_plot_path: Path | None = None,
):
if not hist:
return
has_loss = ("loss" in hist) or ("val_loss" in hist)
has_rmse = ("rmse_dollars" in hist) or ("val_rmse_dollars" in hist)
if has_loss:
plt.figure(figsize=(7, 4))
if "loss" in hist:
plt.plot(hist["loss"], label="loss")
if "val_loss" in hist:
plt.plot(hist["val_loss"], label="val_loss")
plt.xlabel("Epoch")
plt.ylabel("Loss (log space)")
plt.title("FT-Transformer Training Curves (Loss)")
plt.legend()
plt.tight_layout()
if loss_plot_path is not None:
plt.savefig(loss_plot_path, dpi=160, bbox_inches="tight")
if show:
plt.show()
else:
plt.close()
if has_rmse:
plt.figure(figsize=(7, 4))
if "rmse_dollars" in hist:
plt.plot(hist["rmse_dollars"], label="rmse_dollars")
if "val_rmse_dollars" in hist:
plt.plot(hist["val_rmse_dollars"], label="val_rmse_dollars")
plt.xlabel("Epoch")
plt.ylabel("RMSE ($)")
plt.title("FT-Transformer Training Curves (RMSE $)")
plt.legend()
plt.tight_layout()
if rmse_plot_path is not None:
plt.savefig(rmse_plot_path, dpi=160, bbox_inches="tight")
if show:
plt.show()
else:
plt.close()
# 1) SKIP
if TRAIN_MODE == "skip":
if _keras_latest_exists():
print("✅ TRAIN_MODE='skip' — loading latest Keras weights:\n ", KERAS_LATEST_WEIGHTS_PATH)
model, latest_art = _rebuild_and_load_keras_model_from_artifacts(
base_dir=KERAS_DIR,
kind="latest",
)
KERAS_EVAL_ARTIFACT_DIR = KERAS_DIR
KERAS_EVAL_ARTIFACT_KIND = "latest"
KERAS_MODEL_SOURCE = "latest_loaded"
else:
print("⏭️ TRAIN_MODE='skip' — no latest Keras weights found, skipping.")
model = None
# 2) FULL + no retrain
elif (TRAIN_MODE == "full") and _keras_latest_exists() and (not RETRAIN_KERAS):
# Commenting out for notebook render
# print("✅ Loading existing Keras latest weights (RETRAIN_KERAS=False, TRAIN_MODE='full'):\n ", KERAS_LATEST_WEIGHTS_PATH)
print("✅ Loading existing Keras latest weights (RETRAIN_KERAS=False, TRAIN_MODE='full')")
model, latest_art = _rebuild_and_load_keras_model_from_artifacts(
base_dir=KERAS_DIR,
kind="latest",
)
KERAS_EVAL_ARTIFACT_DIR = KERAS_DIR
KERAS_EVAL_ARTIFACT_KIND = "latest"
KERAS_MODEL_SOURCE = "latest_loaded"
# 3) Otherwise: TRAIN
else:
if not SHOULD_TRAIN_KERAS:
raise RuntimeError(
"Keras training branch entered, but SHOULD_TRAIN_KERAS=False. "
"Check Keras weights-based load/train logic vs TRAIN_MODE/RETRAIN_KERAS/latest weights."
)
BATCH = FT_CFG["batch_smoke"] if TRAIN_MODE == "smoke" else FT_CFG["batch_full"]
EPOCHS = FT_CFG["epochs_smoke"] if TRAIN_MODE == "smoke" else FT_CFG["epochs_full"]
train_inputs_run, val_inputs_run, y_train_run, y_val_run = get_run_data_for_mode(TRAIN_MODE)
# Run folder
run_ts = datetime.now().strftime("%Y%m%d_%H%M%S")
KERAS_RUN_DIR = KERAS_RUNS_DIR / run_dir_name(run_ts, TRAIN_MODE)
KERAS_RUN_DIR.mkdir(parents=True, exist_ok=True)
versioned_weights_path = KERAS_RUN_DIR / "keras_model.weights.h5"
# Run info
trial_epochs_for_run = (
int(TUNER_EPOCHS_SMOKE) if TRAIN_MODE == "smoke" else int(TUNER_EPOCHS_FULL)
)
run_info = {
"run_ts": run_ts,
"train_mode": TRAIN_MODE,
"retrain_keras": bool(RETRAIN_KERAS),
"updates_latest": bool(_touches_latest()),
"train_rows": int(len(y_train_run)),
"val_rows": int(len(y_val_run)),
"num_cols": list(num_cols_nn),
"cat_cols": list(cat_cols_nn),
"ft_cfg": dict(FT_CFG),
"tuning": get_tuning_metadata_for_run(
best_hp=best_hp,
mode=TRAIN_MODE,
trial_epochs=trial_epochs_for_run,
),
"note": "FT-Transformer with WarmupCosine LR schedule and RMSE($) metric for early stopping",
}
# Save rebuild artifacts for this run before weight save/load checks.
_save_keras_rebuild_artifacts(
base_dir=KERAS_RUN_DIR,
kind="run",
run_info=run_info,
train_medians_series=train_medians,
train_num_mean_series=train_num_mean,
train_num_std_series=train_num_std,
lookup_vocabs=LOOKUP_VOCABS,
)
if TRAIN_MODE == "smoke":
atomic_write_bytes(
KERAS_RUN_DIR / "SMOKE_RUN_DO_NOT_USE.txt",
b"This is a smoke test run. Do not use as production/latest.\n"
)
# Clear session
tf.keras.backend.clear_session()
gc.collect()
# Warmup + cosine schedule: compute steps from data
batch_eff = min(int(BATCH), int(len(y_train_run)))
steps_per_epoch = int(np.ceil(len(y_train_run) / batch_eff))
total_steps = int(steps_per_epoch * int(EPOCHS))
warmup_steps = max(1, int(float(FT_CFG["warmup_frac"]) * total_steps))
lr_schedule = WarmupCosine(
base_lr=float(FT_CFG["lr"]),
warmup_steps=warmup_steps,
total_steps=total_steps,
min_lr=float(FT_CFG["min_lr"]),
)
model = build_ft_transformer_model(lr_schedule)
print(f"Training FT-Transformer | mode={TRAIN_MODE} | epochs={EPOCHS} | batch={batch_eff}")
assert_nonempty_inputs(train_inputs_run, y_train_run, "step6_train")
assert_nonempty_inputs(val_inputs_run, y_val_run, "step6_val")
train_ds = make_tf_dataset(
train_inputs_run,
y_train_run,
batch_size=batch_eff,
training=True,
drop_remainder=True,
)
val_ds = make_tf_dataset(
val_inputs_run,
y_val_run,
batch_size=batch_eff,
training=False,
drop_remainder=False,
)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=int(EPOCHS),
verbose=0,
callbacks=make_callbacks(TRAIN_MODE),
)
if TRAIN_MODE == "full":
run_paths = _keras_artifact_paths(KERAS_RUN_DIR, "run")
_save_keras_history(history, run_paths["history"])
plot_keras_training_curves(
_history_to_serializable_dict(history),
show=False,
loss_plot_path=run_paths["loss_plot"],
rmse_plot_path=run_paths["rmse_plot"],
)
# print("💾 Saved Keras training history:", run_paths["history"])
# print("💾 Saved Keras training plots:", run_paths["loss_plot"], "and", run_paths["rmse_plot"])
else:
print("ℹ️ Smoke mode: not saving Keras training history or plots.")
# Save weights only (not full model) to avoid serialization issues
# with custom layers and schedules. Reconstruction artifacts are
# saved alongside for reproducible model rebuilding.
model.save_weights(versioned_weights_path)
# print("💾 Saved versioned weights:", versioned_weights_path)
# Evaluation should use this run's saved weight/artifact bundle.
KERAS_EVAL_ARTIFACT_DIR = KERAS_RUN_DIR
KERAS_EVAL_ARTIFACT_KIND = "run"
KERAS_MODEL_SOURCE = "trained_this_run"
# Update latest ONLY for FULL, and copy the rebuild artifacts alongside latest weights.
if _touches_latest():
model.save_weights(KERAS_LATEST_WEIGHTS_PATH)
_save_keras_rebuild_artifacts(
base_dir=KERAS_DIR,
kind="latest",
run_info=run_info,
train_medians_series=train_medians,
train_num_mean_series=train_num_mean,
train_num_std_series=train_num_std,
lookup_vocabs=LOOKUP_VOCABS,
)
if TRAIN_MODE == "full" and _touches_latest():
latest_paths = _keras_artifact_paths(KERAS_DIR, "latest")
_save_keras_history(history, latest_paths["history"])
plot_keras_training_curves(
_history_to_serializable_dict(history),
show=False,
loss_plot_path=latest_paths["loss_plot"],
rmse_plot_path=latest_paths["rmse_plot"],
)
#print("✅ Updated latest Keras history:", latest_paths["history"])
#print("✅ Updated latest Keras plots:", latest_paths["loss_plot"], "and", latest_paths["rmse_plot"])
#print("✅ Updated latest Keras weights:", KERAS_LATEST_WEIGHTS_PATH)
else:
print("🚫 Smoke run: NOT updating latest pointer.")
```
#### FT-Transformer Evaluation
```{python}
#| code-summary: "FT-Transformer evaluation: test metrics, permutation importance, training curves"
# ----------------------------
# Step 7: Evaluation (dollars)
# ----------------------------
model_eval = None
if ("model" not in globals()) or (model is None):
print("⚠️ Keras model is not available — skipping evaluation.")
else:
if ("KERAS_EVAL_ARTIFACT_DIR" in globals()) and (KERAS_EVAL_ARTIFACT_DIR is not None):
# Commenting out for notebook render
# print("Loading Keras weights for evaluation from:", KERAS_EVAL_ARTIFACT_DIR)
print("Loading Keras weights for evaluation.")
print("Keras model source:", KERAS_MODEL_SOURCE)
print("Keras artifact kind:", KERAS_EVAL_ARTIFACT_KIND)
model_eval, eval_art = _rebuild_and_load_keras_model_from_artifacts(
base_dir=KERAS_EVAL_ARTIFACT_DIR,
kind=KERAS_EVAL_ARTIFACT_KIND,
)
# ⚠️ GLOBAL STATE NOTE:
# _rebuild_and_load_keras_model_from_artifacts temporarily swaps FT_CFG,
# num_cols_nn, cat_cols_nn, and LOOKUP_VOCABS to rebuild the model architecture,
# then restores them in a finally block. This means model_eval was *built* with
# the saved artifact's config, but the current globals reflect the notebook's
# live config — which may differ (e.g., after tuning or code edits).
# Any code using model_eval must pull feature names, vocab, and normalization
# stats from eval_art (the returned artifact dict), NOT from the live globals.
#
# ✅ Correct: eval_art["num_cols"], eval_art["cat_cols"], eval_art["lookup_vocabs"]
# ❌ Wrong: num_cols_nn, cat_cols_nn, LOOKUP_VOCABS (live globals, may not match model_eval)
# The permutation importance section below follows the correct pattern.
if KERAS_MODEL_SOURCE == "trained_this_run":
test_inputs_tf_eval = test_inputs_tf
X_trainval_eval_df = pd.concat([X_train_nn, X_val_nn], axis=0)
y_trainval_eval = np.concatenate([y_train_nn, y_val_nn], axis=0)
trainval_inputs_tf_eval = to_input_dict_tf(to_input_dict_np(X_trainval_eval_df))
pred_batch_eval = int(eval_art["ft_cfg"]["pred_batch"])
else:
# For loaded historical/latest artifacts, rebuild inputs from saved artifacts.
test_inputs_tf_eval = _prepare_inputs_for_saved_artifacts(
X_test,
num_cols_saved=eval_art["num_cols"],
cat_cols_saved=eval_art["cat_cols"],
train_medians_saved=eval_art["train_medians"],
num_norm_mean_saved=eval_art["num_norm_mean"],
num_norm_std_saved=eval_art["num_norm_std"],
)
X_trainval_eval_df = pd.concat([X_train, X_val], axis=0)
y_trainval_eval = np.concatenate([y_train_nn, y_val_nn], axis=0)
trainval_inputs_tf_eval = _prepare_inputs_for_saved_artifacts(
X_trainval_eval_df,
num_cols_saved=eval_art["num_cols"],
cat_cols_saved=eval_art["cat_cols"],
train_medians_saved=eval_art["train_medians"],
num_norm_mean_saved=eval_art["num_norm_mean"],
num_norm_std_saved=eval_art["num_norm_std"],
)
pred_batch_eval = int(eval_art["ft_cfg"]["pred_batch"])
else:
print("ℹ️ KERAS_EVAL_ARTIFACT_DIR not set — using in-memory model + current inputs for evaluation.")
model_eval = model
test_inputs_tf_eval = test_inputs_tf
X_trainval_eval_df = pd.concat([X_train_nn, X_val_nn], axis=0)
y_trainval_eval = np.concatenate([y_train_nn, y_val_nn], axis=0)
trainval_inputs_tf_eval = to_input_dict_tf(to_input_dict_np(X_trainval_eval_df))
pred_batch_eval = int(FT_CFG["pred_batch"])
def predict_dollars(inputs_tf: dict) -> np.ndarray:
pred_log = model_eval.predict(
inputs_tf,
batch_size=pred_batch_eval,
verbose=0
).reshape(-1)
return np.expm1(pred_log.astype("float64"))
# ----------------------------
# TEST metrics
# ----------------------------
true_test = np.expm1(y_test_nn.astype("float64"))
pred_test = predict_dollars(test_inputs_tf_eval)
keras_test_m = metrics_full_and_clipped(true_test, pred_test, clip_lo=CLIP_LO, clip_hi=CLIP_HI)
display(metrics_to_df(keras_test_m, "FT-Transformer (Test)"))
# ----------------------------
# TRAIN+VAL metrics
# ----------------------------
true_trainval = np.expm1(y_trainval_eval.astype("float64"))
pred_trainval = predict_dollars(trainval_inputs_tf_eval)
keras_trainval_m = metrics_full_and_clipped(true_trainval, pred_trainval, clip_lo=CLIP_LO, clip_hi=CLIP_HI)
display(metrics_to_df(keras_trainval_m, "FT-Transformer (Train+Val)"))
# ----------------------------
# Globals for metrics writer
# ----------------------------
keras_test_full = keras_test_m["full"]
keras_test_clipped = keras_test_m["clipped"]
keras_trainval_full = keras_trainval_m["full"]
keras_trainval_clipped = keras_trainval_m["clipped"]
# ----------------------------
# Update Keras tuning history
# ----------------------------
if TUNE and (best_hp is not None):
trial_epochs_for_run = (
int(TUNER_EPOCHS_SMOKE) if TRAIN_MODE == "smoke" else int(TUNER_EPOCHS_FULL)
)
tuning_record = {
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"run_ts": globals().get("run_ts", None),
"keras_run_dir": str(KERAS_RUN_DIR) if KERAS_RUN_DIR is not None else None,
"active_round": ACTIVE_TUNING_ROUND,
"train_mode": TRAIN_MODE,
"tuner_kind": TUNER_KIND,
"objective": TUNER_OBJECTIVE,
"max_trials": int(TUNER_MAX_TRIALS),
"executions_per_trial": int(TUNER_EXECUTIONS_PER_TRIAL),
"epochs_per_trial": int(trial_epochs_for_run),
"patience": int(TUNER_PATIENCE_SMOKE if TRAIN_MODE == "smoke" else TUNER_PATIENCE_FULL),
"search_space": get_active_tuning_round_dict(),
"best_hp": dict(best_hp.values),
"metrics": {
"trainval": {
"full": keras_trainval_full,
"clipped": keras_trainval_clipped,
},
"test": {
"full": keras_test_full,
"clipped": keras_test_clipped,
},
},
}
update_tuning_history(KERAS_TUNING_HISTORY_PATH, tuning_record)
print("🧾 Updated Keras tuning history:", KERAS_TUNING_HISTORY_PATH)
# ----------------------------
# Permutation importance (per-feature)
# ----------------------------
# Permutation importance for neural networks: unlike tree models,
# Keras doesn't have a built-in feature importance. This shuffles
# each feature independently and measures the RMSE increase on the
# test set. A larger increase means the model relies more on that
# feature. Subsampled to max_rows for speed; repeated n_repeats
# times for stability.
def permutation_importance_keras_per_feature(
base_inputs: dict,
y_true_dollars: np.ndarray,
*,
feature_names_numeric: list[str],
feature_names_categorical: list[str],
n_repeats: int = 3,
seed: int = 42,
max_rows: int | None = 20000,
include_categoricals: bool = True,
):
rs = np.random.RandomState(seed)
# Expected numeric width from current evaluation inputs
d_num = int(base_inputs["numeric"].shape[1])
cat_keys = [k for k in base_inputs.keys() if k != "numeric"]
def _force_static_shapes(inputs: dict) -> dict:
"""
Ensure model sees the exact ranks/shapes expected:
- numeric: (None, d_num) float32
- each categorical: (None,) string
"""
out = {}
# numeric
xnum = tf.convert_to_tensor(inputs["numeric"], dtype=tf.float32)
if xnum.shape.rank == 1:
xnum = tf.reshape(xnum, [-1, d_num])
elif xnum.shape.rank == 2 and xnum.shape[-1] != d_num:
xnum = tf.reshape(xnum, [-1, d_num])
xnum.set_shape([None, d_num])
out["numeric"] = xnum
# categoricals
for k in cat_keys:
x = tf.convert_to_tensor(inputs[k], dtype=tf.string)
if x.shape.rank == 2 and x.shape[-1] == 1:
x = tf.reshape(x, [-1])
elif x.shape.rank != 1:
x = tf.reshape(x, [-1])
x.set_shape([None])
out[k] = x
return out
def _gather_rows_tf(inputs: dict, idx_rows: np.ndarray) -> dict:
idx_tf = tf.convert_to_tensor(idx_rows, dtype=tf.int32)
out = {}
for k, v in inputs.items():
v = tf.convert_to_tensor(v)
out[k] = tf.gather(v, idx_tf, axis=0)
return _force_static_shapes(out)
def _predict_dollars_local(inputs_tf: dict) -> np.ndarray:
pred_log = model_eval.predict(
inputs_tf,
batch_size=pred_batch_eval,
verbose=0
).reshape(-1)
return np.expm1(pred_log.astype("float64"))
# ----------------------------
# 0) Optional subsample
# ----------------------------
N = int(len(y_true_dollars))
if (max_rows is not None) and (N > int(max_rows)):
idx_rows = rs.choice(N, size=int(max_rows), replace=False)
sub_inputs = _gather_rows_tf(base_inputs, idx_rows)
y_sub = np.asarray(y_true_dollars)[idx_rows]
else:
sub_inputs = _force_static_shapes(base_inputs)
y_sub = np.asarray(y_true_dollars)
# ----------------------------
# 1) Baseline RMSE
# ----------------------------
base_pred = _predict_dollars_local(sub_inputs)
base_rmse = float(np.sqrt(np.mean((y_sub - base_pred) ** 2)))
rows = []
# ----------------------------
# 2) Numeric feature importance
# ----------------------------
Xnum = sub_inputs["numeric"]
if len(feature_names_numeric) == d_num:
num_names = list(feature_names_numeric)
else:
num_names = [f"num_{j}" for j in range(d_num)]
for j in range(d_num):
deltas = []
for _ in range(int(n_repeats)):
idx_perm = rs.permutation(len(y_sub))
idx_tf = tf.convert_to_tensor(idx_perm, dtype=tf.int32)
col_perm = tf.gather(Xnum[:, j], idx_tf)
col_perm = tf.expand_dims(col_perm, axis=1)
left = Xnum[:, :j]
right = Xnum[:, j+1:]
Xnum_new = tf.concat([left, col_perm, right], axis=1)
Xnum_new.set_shape([None, d_num])
pert = dict(sub_inputs)
pert["numeric"] = Xnum_new
pert = _force_static_shapes(pert)
pred = _predict_dollars_local(pert)
rmse = float(np.sqrt(np.mean((y_sub - pred) ** 2)))
deltas.append(rmse - base_rmse)
rows.append({
"feature": num_names[j],
"feature_type": "numeric",
"rmse_increase": float(np.mean(deltas)),
"rmse_increase_std": float(np.std(deltas)),
})
# ----------------------------
# 3) Categorical feature importance
# ----------------------------
if include_categoricals:
for key in cat_keys:
deltas = []
Xcat = sub_inputs[key]
for _ in range(int(n_repeats)):
idx_perm = rs.permutation(len(y_sub))
idx_tf = tf.convert_to_tensor(idx_perm, dtype=tf.int32)
Xcat_new = tf.gather(Xcat, idx_tf, axis=0)
Xcat_new.set_shape([None])
pert = dict(sub_inputs)
pert[key] = Xcat_new
pert = _force_static_shapes(pert)
pred = _predict_dollars_local(pert)
rmse = float(np.sqrt(np.mean((y_sub - pred) ** 2)))
deltas.append(rmse - base_rmse)
rows.append({
"feature": key,
"feature_type": "categorical",
"rmse_increase": float(np.mean(deltas)),
"rmse_increase_std": float(np.std(deltas)),
})
df_pi = (
pd.DataFrame(rows)
.sort_values("rmse_increase", ascending=False)
.reset_index(drop=True)
)
return base_rmse, df_pi
# ----------------------------
# Keras permutation importance
# ----------------------------
try:
if ("eval_art" in locals()) and (eval_art is not None):
pi_num_names = list(eval_art["num_cols"])
pi_cat_names = list(eval_art["cat_cols"])
else:
pi_num_names = list(num_cols_nn)
pi_cat_names = list(cat_cols_nn)
base_rmse_pi, pi_df = permutation_importance_keras_per_feature(
test_inputs_tf_eval,
true_test, # dollars
feature_names_numeric=pi_num_names,
feature_names_categorical=pi_cat_names,
n_repeats=2,
seed=SEED if "SEED" in globals() else 42,
max_rows=10000,
include_categoricals=True,
)
pi_df_display = pi_df.copy()
total = pi_df_display["rmse_increase"].clip(lower=0).sum()
if total > 0:
pi_df_display["importance_pct"] = (
100 * pi_df_display["rmse_increase"].clip(lower=0) / total
)
else:
pi_df_display["importance_pct"] = 0.0
display(
pi_df_display[
["feature", "feature_type", "rmse_increase", "importance_pct", "rmse_increase_std"]
].head(30)
)
except Exception as e:
print("⚠️ Permutation importance failed:", e)
# ----------------------------
# Training Graphs
# ----------------------------
hist_to_plot = None
# First choice: in-memory history from this run
if ("history" in globals()) and (history is not None):
hist_to_plot = _history_to_serializable_dict(history)
# Fallback: load saved history from whichever artifact bundle is being evaluated
elif ("KERAS_EVAL_ARTIFACT_DIR" in globals()) and (KERAS_EVAL_ARTIFACT_DIR is not None):
history_path = _keras_artifact_paths(
KERAS_EVAL_ARTIFACT_DIR,
KERAS_EVAL_ARTIFACT_KIND,
)["history"]
hist_to_plot = _load_keras_history(history_path)
# Final fallback: latest history
elif KERAS_LATEST_HISTORY_PATH.exists():
hist_to_plot = _load_keras_history(KERAS_LATEST_HISTORY_PATH)
if hist_to_plot:
if ("loss" in hist_to_plot) or ("val_loss" in hist_to_plot) or ("rmse_dollars" in hist_to_plot) or ("val_rmse_dollars" in hist_to_plot):
plot_keras_training_curves(hist_to_plot, show=True)
else:
print("ℹ️ History file exists but does not contain expected keys.")
else:
print("ℹ️ No training history available (neither in memory nor saved artifacts).")
```
#### FT-Transformer Interpretation
The FT-Transformer was included as evidence of advanced experimentation with deep learning on tabular data, but was ultimately outperformed by CatBoost on metrics and operability.
**Architecture**: The model uses learned embeddings for each categorical feature and a Transformer-style attention mechanism to capture feature interactions. This is a more modern approach than simple dense networks for tabular data.
**Performance**: The FT-Transformer achieved competitive results — its clipped test MAE ($1,800) is within $20 of CatBoost ($1,782), showing that it learned meaningful representations. However, its full-distribution RMSE ($4,255) is ~8% higher than CatBoost's ($3,935), indicating greater sensitivity to rare, high-price vehicles.
**Permutation importance**: The permutation-based feature importance largely agrees with CatBoost's rankings — `model` (25.0%), `manufacturer` (14.4%), `mileage` (14.1%), and `age` (12.0%) are the top features. The consistency across model families suggests these are genuinely the most informative features rather than artifacts of a particular algorithm.
**Training behavior**: The Huber loss curves show rapid initial convergence, with both train and validation loss decreasing sharply through ~epoch 15. After that, train loss continues to slowly decrease while validation loss plateaus, indicating mild overfitting in later epochs — which is expected and handled by early stopping, which restores weights from the best-generalizing epoch. The RMSE (dollar) curves show more pronounced volatility, as RMSE in dollar space amplifies the effect of individual high-value predictions.
**Why CatBoost still wins**: On this dataset, CatBoost's native categorical handling and ordered boosting provide a structural advantage over learned embeddings. The FT-Transformer requires more data and tuning to match the performance of tree-based methods on tabular problems — a finding consistent with the broader ML literature (e.g., Grinsztajn et al., 2022).
**Practical considerations**: Beyond raw accuracy, the FT-Transformer required substantially more development effort. Hyperparameter tuning (embedding dimensions, attention heads, learning rate schedules, dropout) involved longer iteration cycles than CatBoost's staged grid search, and the model was more sensitive to batch size and learning rate choices — small changes that barely affected CatBoost could destabilize Keras training. Total training time was also significantly longer. For a production system where maintainability and retrainability matter, CatBoost's combination of better performance, faster training, and lower tuning fragility makes it the clear choice.
## Model Comparison
### Metrics Export
Metrics for all three models are written to a unified JSON file for downstream analysis and reproducibility. Each model's results include full-distribution and clipped variants for both train+val and test splits.
```{python}
#| code-summary: "Write unified metrics JSON for all models"
# -------------------------
# Save Metrics
# Standard schema across models:
# metrics[model]["trainval"]["full"/"clipped"]
# metrics[model]["test"]["full"/"clipped"]
# -------------------------
metrics = {}
# ---- Meta ----
metrics["_meta"] = {
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"train_mode": TRAIN_MODE if "TRAIN_MODE" in globals() else None,
"updates_latest": (TRAIN_MODE == "full") if "TRAIN_MODE" in globals() else None,
"retrain_flags": {
"ridge": bool(RETRAIN_RIDGE) if "RETRAIN_RIDGE" in globals() else None,
"catboost": bool(RETRAIN_CATBOOST) if "RETRAIN_CATBOOST" in globals() else None,
"keras": bool(RETRAIN_KERAS) if "RETRAIN_KERAS" in globals() else None,
},
"rows": {
"train": int(len(X_train)) if "X_train" in globals() else None,
"val": int(len(X_val)) if "X_val" in globals() else None,
"test": int(len(X_test)) if "X_test" in globals() else None,
"total": int(len(X)) if "X" in globals() else None,
},
"clip_policy": {
"basis": "y_train_quantiles",
"q_low": 0.01,
"q_high": 0.99,
"clip_lo": float(CLIP_LO),
"clip_hi": float(CLIP_HI),
"note": (
"Clip bounds are the 1st and 99th percentiles of the training set's "
"true prices (in dollars). The same bounds are applied to all splits "
"so clipped metrics are directly comparable across train, val, and test."
),
},
}
# Helper: safe string-or-None
def _str_or_none(x):
return str(x) if x is not None else None
# Helper: build a split metrics object from globals
def _split_payload(full_key: str, clipped_key: str):
full = globals().get(full_key, None)
clipped = globals().get(clipped_key, None)
return {
"full": full,
"clipped": clipped,
}
# -------------------------
# Ridge metrics
# Requires you to set these in Ridge eval:
# ridge_test_full, ridge_test_clipped
# ridge_trainval_full, ridge_trainval_clipped
# -------------------------
if all(k in globals() for k in [
"ridge_test_full", "ridge_test_clipped",
"ridge_trainval_full", "ridge_trainval_clipped"
]):
metrics["ridge"] = {
"trainval": _split_payload("ridge_trainval_full", "ridge_trainval_clipped"),
"test": _split_payload("ridge_test_full", "ridge_test_clipped"),
}
else:
print("ℹ️ Skipping Ridge metrics write (need ridge_*_full and ridge_*_clipped).")
# -------------------------
# CatBoost metrics
# Requires you to set these in CatBoost eval:
# cb_test_full, cb_test_clipped
# cb_trainval_full, cb_trainval_clipped
# cb_train_full/cb_train_clipped, cb_val_full/cb_val_clipped
# cb_best_iteration_from_train_val_fit, cb_refit_on_trainval_used, cb_refit_iterations_used
# -------------------------
if all(k in globals() for k in [
"cb_test_full", "cb_test_clipped",
"cb_trainval_full", "cb_trainval_clipped"
]):
metrics["catboost"] = {
"trainval": _split_payload("cb_trainval_full", "cb_trainval_clipped"),
"test": _split_payload("cb_test_full", "cb_test_clipped"),
# Updated metadata for refit-aware CatBoost workflow
"best_iteration_train_val_fit": (
int(cb_best_iteration_from_train_val_fit)
if "cb_best_iteration_from_train_val_fit" in globals()
else None
),
"refit_on_trainval": (
bool(cb_refit_on_trainval_used)
if "cb_refit_on_trainval_used" in globals()
else None
),
"refit_iterations_used": (
int(cb_refit_iterations_used)
if "cb_refit_iterations_used" in globals()
else None
),
"run_dir": _str_or_none(globals().get("RUN_DIR", None)),
}
# CV-best val metrics
if all(name in globals() for name in ["mae_cv", "rmse_cv"]):
metrics["catboost"]["val_cvbest"] = {
"mae": float(mae_cv),
"rmse": float(rmse_cv),
}
# Store explicit train/val split metrics if you created them
if all(k in globals() for k in ["cb_train_full", "cb_train_clipped"]):
metrics["catboost"]["train"] = _split_payload("cb_train_full", "cb_train_clipped")
if all(k in globals() for k in ["cb_val_full", "cb_val_clipped"]):
metrics["catboost"]["val"] = _split_payload("cb_val_full", "cb_val_clipped")
else:
print("ℹ️ Skipping CatBoost metrics write (need cb_*_full and cb_*_clipped).")
# -------------------------
# Keras metrics
# Requires you to set these in Keras eval:
# keras_test_full, keras_test_clipped
# keras_trainval_full, keras_trainval_clipped
# -------------------------
if all(k in globals() for k in [
"keras_test_full", "keras_test_clipped",
"keras_trainval_full", "keras_trainval_clipped"
]):
metrics["keras"] = {
"trainval": _split_payload("keras_trainval_full", "keras_trainval_clipped"),
"test": _split_payload("keras_test_full", "keras_test_clipped"),
"run_dir": _str_or_none(globals().get("KERAS_RUN_DIR", None)),
}
else:
print("ℹ️ Skipping Keras metrics write (need keras_*_full and keras_*_clipped).")
# -------------------------
# Write files
# -------------------------
metrics_ts = datetime.now().strftime("%Y%m%d_%H%M%S")
METRICS_VERSIONED_PATH = METRICS_DIR / f"metrics_{metrics_ts}.json"
atomic_write_json(METRICS_PATH, metrics)
# Commented out for notebook render
# print("🧾 Wrote metrics:", METRICS_PATH)
print("🧾 Wrote metrics.")
atomic_write_json(METRICS_VERSIONED_PATH, metrics)
# Commented out for notebook render
# print("🧾 Wrote versioned metrics:", METRICS_VERSIONED_PATH)
print("🧾 Wrote versioned metrics.")
# Run-specific metrics (CatBoost run dir)
if ("RUN_DIR" in globals()) and (globals().get("RUN_DIR", None) is not None):
atomic_write_json(globals()["RUN_DIR"] / "metrics.json", metrics)
print("🧾 Wrote run metrics:", globals()["RUN_DIR"] / "metrics.json")
# Run-specific metrics (Keras run dir)
if ("KERAS_RUN_DIR" in globals()) and (globals().get("KERAS_RUN_DIR", None) is not None):
keras_only = {
"_meta": metrics["_meta"],
"keras": metrics.get("keras", None),
}
atomic_write_json(globals()["KERAS_RUN_DIR"] / "keras_metrics.json", keras_only)
print("🧾 Wrote Keras-only metrics:", globals()["KERAS_RUN_DIR"] / "keras_metrics.json")
```
### Model Comparison Graphs
#### Plotting Functions for Models
```{python}
#| code-summary: "Diagnostic plot functions: pred vs actual, residuals, absolute error, pred vs pred"
# =========================
# Plot Function 1
# =========================
def clip_by_quantile(y_true, y_pred, q_low=0.01, q_high=0.99):
y_true = np.asarray(y_true)
y_pred = np.asarray(y_pred)
lo, hi = np.quantile(y_true, [q_low, q_high])
mask = (y_true >= lo) & (y_true <= hi)
return y_true[mask], y_pred[mask], mask, (lo, hi)
# =========================
# Plot Function 2
# =========================
def plot_regression_diagnostics(
y_true, y_pred,
X_ref=None, feature_for_residual="age",
clip=False, q_low=0.01, q_high=0.99,
title_prefix=""
):
"""
Plots:
1) Predicted vs Actual
2) Residuals vs Predicted
3) Residuals vs a chosen feature (e.g., age or mileage)
Clips by y_true quantiles for readability for some charts.
"""
y_true = np.asarray(y_true)
y_pred = np.asarray(y_pred)
if clip:
y_true_p, y_pred_p, mask, (lo, hi) = clip_by_quantile(y_true, y_pred, q_low, q_high)
label_suffix = f" (clipped {int(q_low*100)}–{int(q_high*100)}% of y_true)"
else:
y_true_p, y_pred_p = y_true, y_pred
mask = None
label_suffix = " (unclipped)"
# 1) Predicted vs Actual
plt.figure(figsize=(6, 6))
plt.scatter(y_true_p, y_pred_p, alpha=0.2)
mn = min(y_true_p.min(), y_pred_p.min())
mx = max(y_true_p.max(), y_pred_p.max())
plt.plot([mn, mx], [mn, mx], "r--")
plt.xlabel("Actual Price ($)")
plt.ylabel("Predicted Price ($)")
plt.title(f"{title_prefix} Predicted vs Actual{label_suffix}")
plt.tight_layout()
plt.show()
residuals = y_true_p - y_pred_p
# 2) Residuals vs Predicted
plt.figure(figsize=(6, 4))
plt.scatter(y_pred_p, residuals, alpha=0.2)
plt.axhline(0, color="red", linestyle="--")
plt.xlabel("Predicted Price ($)")
plt.ylabel("Residual ($) (actual - predicted)")
plt.title(f"{title_prefix} Residuals vs Predicted{label_suffix}")
plt.tight_layout()
plt.show()
# 3) Residuals vs Feature
if X_ref is not None and feature_for_residual in X_ref.columns:
if mask is not None:
# mask aligns to y_true/y_pred order; apply same mask to X_ref
x_feat = np.asarray(X_ref[feature_for_residual])[mask]
else:
x_feat = np.asarray(X_ref[feature_for_residual])
plt.figure(figsize=(6, 4))
plt.scatter(x_feat, residuals, alpha=0.2)
plt.axhline(0, color="red", linestyle="--")
plt.xlabel(feature_for_residual)
plt.ylabel("Residual ($)")
plt.title(f"{title_prefix} Residuals vs {feature_for_residual}{label_suffix}")
plt.tight_layout()
plt.show()
# =========================
# Plot Function 3
# =========================
def plot_abs_error_vs_actual(
y_true, y_pred,
clip=False, q_low=0.01, q_high=0.99,
title_prefix="",
log_x=True
):
"""
Plot absolute error vs actual price.
Clip based on y_true quantiles for readability (optional).
Log-scale the x-axis (actual price).
"""
y_true = np.asarray(y_true)
y_pred = np.asarray(y_pred)
if clip:
y_true_p, y_pred_p, _, _ = clip_by_quantile(y_true, y_pred, q_low, q_high)
label_suffix = f" (clipped {int(q_low*100)}–{int(q_high*100)}% of y_true)"
else:
y_true_p, y_pred_p = y_true, y_pred
label_suffix = " (unclipped)"
abs_err = np.abs(y_true_p - y_pred_p)
plt.figure(figsize=(6, 4))
plt.scatter(y_true_p, abs_err, alpha=0.2)
plt.ylabel("Absolute Error ($)")
plt.title(f"{title_prefix} Absolute Error vs Actual{label_suffix}")
if log_x:
plt.xscale("log")
plt.xlabel("Actual Price ($) [log scale]")
else:
plt.xlabel("Actual Price ($)")
plt.tight_layout()
plt.show()
# =========================
# Plot Function 4
# =========================
def plot_pred_vs_pred(
pred_a, pred_b,
*,
name_a="Model A",
name_b="Model B",
clip_by_y_true=None,
clip=False,
q_low=0.01,
q_high=0.99
):
"""
Scatter of predictions from two models against each other.
Clipping is based on y_true quantiles (optional).
"""
pred_a = np.asarray(pred_a)
pred_b = np.asarray(pred_b)
if clip:
if clip_by_y_true is None:
raise ValueError("clip=True requires clip_by_y_true (the y_true array).")
y_true = np.asarray(clip_by_y_true)
_, _, mask, _ = clip_by_quantile(y_true, pred_a, q_low=q_low, q_high=q_high)
pred_a_p = pred_a[mask]
pred_b_p = pred_b[mask]
suffix = f" (clipped {int(q_low*100)}–{int(q_high*100)}% of y_true)"
else:
pred_a_p, pred_b_p = pred_a, pred_b
suffix = " (unclipped)"
plt.figure(figsize=(6, 6))
plt.scatter(pred_a_p, pred_b_p, alpha=0.2)
mn = min(pred_a_p.min(), pred_b_p.min())
mx = max(pred_a_p.max(), pred_b_p.max())
plt.plot([mn, mx], [mn, mx], "r--")
plt.xlabel(f"{name_a} Predicted Price ($)")
plt.ylabel(f"{name_b} Predicted Price ($)")
plt.title(f"{name_a} vs {name_b} Predictions{suffix}")
plt.tight_layout()
plt.show()
```
#### Model Graph Section
The following diagnostic plots are generated for each model on the test set. Each model gets four plot types in both unclipped and clipped (1–99%) views.
```{python}
#| code-summary: "Collect test-set predictions from all available models"
if ("X_test" not in globals()) or ("y_test" not in globals()):
print("⚠️ X_test/y_test not found — cannot plot comparisons.")
else:
y_true_test = np.expm1(y_test)
# Choose feature for residual-vs-feature
feature_name = "age" if "age" in X_test.columns else ("mileage" if "mileage" in X_test.columns else None)
# Collect predictions from any models that exist
preds = {}
if ("best_ridge" in globals()) and (best_ridge is not None):
preds["Ridge"] = np.expm1(best_ridge.predict(X_test))
else:
print("ℹ️ Ridge not available — skipping Ridge plots.")
if ("final_cb" in globals()) and (final_cb is not None):
preds["CatBoost"] = np.expm1(final_cb.predict(X_test))
else:
print("ℹ️ CatBoost not available — skipping CatBoost plots.")
# Use evaluation-ready Keras objects if available
if ("model_eval" in globals()) and (model_eval is not None) and ("test_inputs_tf_eval" in globals()):
preds["Keras"] = predict_dollars(test_inputs_tf_eval)
else:
print("ℹ️ Keras evaluation model/inputs not available — skipping Keras plots.")
```
**Ridge Diagnostics**
```{python}
#| code-summary: "Ridge: predicted vs actual, residuals, absolute error (unclipped + clipped)"
if "Ridge" in preds:
plot_regression_diagnostics(
y_true_test, preds["Ridge"],
X_ref=X_test,
feature_for_residual=(feature_name or "age"),
clip=False,
title_prefix="Ridge |"
)
plot_regression_diagnostics(
y_true_test, preds["Ridge"],
X_ref=X_test,
feature_for_residual=(feature_name or "age"),
clip=True, q_low=0.01, q_high=0.99,
title_prefix="Ridge |"
)
plot_abs_error_vs_actual(
y_true_test, preds["Ridge"],
clip=False, title_prefix="Ridge |", log_x=True
)
plot_abs_error_vs_actual(
y_true_test, preds["Ridge"],
clip=True, q_low=0.01, q_high=0.99,
title_prefix="Ridge |", log_x=True
)
```
**CatBoost Diagnostics**
```{python}
#| code-summary: "CatBoost: predicted vs actual, residuals, absolute error (unclipped + clipped)"
if "CatBoost" in preds:
plot_regression_diagnostics(
y_true_test, preds["CatBoost"],
X_ref=X_test,
feature_for_residual=(feature_name or "age"),
clip=False,
title_prefix="CatBoost |"
)
plot_regression_diagnostics(
y_true_test, preds["CatBoost"],
X_ref=X_test,
feature_for_residual=(feature_name or "age"),
clip=True, q_low=0.01, q_high=0.99,
title_prefix="CatBoost |"
)
plot_abs_error_vs_actual(
y_true_test, preds["CatBoost"],
clip=False, title_prefix="CatBoost |", log_x=True
)
plot_abs_error_vs_actual(
y_true_test, preds["CatBoost"],
clip=True, q_low=0.01, q_high=0.99,
title_prefix="CatBoost |", log_x=True
)
```
**FT-Transformer Diagnostics**
```{python}
#| code-summary: "FT-Transformer: predicted vs actual, residuals, absolute error (unclipped + clipped)"
if "Keras" in preds:
plot_regression_diagnostics(
y_true_test, preds["Keras"],
X_ref=X_test,
feature_for_residual=(feature_name or "age"),
clip=False,
title_prefix="Keras |"
)
plot_regression_diagnostics(
y_true_test, preds["Keras"],
X_ref=X_test,
feature_for_residual=(feature_name or "age"),
clip=True, q_low=0.01, q_high=0.99,
title_prefix="Keras |"
)
plot_abs_error_vs_actual(
y_true_test, preds["Keras"],
clip=False, title_prefix="Keras |", log_x=True
)
plot_abs_error_vs_actual(
y_true_test, preds["Keras"],
clip=True, q_low=0.01, q_high=0.99,
title_prefix="Keras |", log_x=True
)
```
**Cross-Model Prediction Comparison**
These plots compare the raw predictions of each model pair. Points along the diagonal indicate agreement; systematic deviations reveal where models diverge.
```{python}
#| code-summary: "Pred vs pred for each model pair (unclipped + clipped)"
model_names = list(preds.keys())
if len(model_names) >= 2:
for i in range(len(model_names)):
for j in range(i + 1, len(model_names)):
a = model_names[i]
b = model_names[j]
plot_pred_vs_pred(
preds[a], preds[b],
name_a=a, name_b=b,
clip=False
)
plot_pred_vs_pred(
preds[a], preds[b],
name_a=a, name_b=b,
clip_by_y_true=y_true_test,
clip=True, q_low=0.01, q_high=0.99
)
else:
print("ℹ️ Only one model available — skipping pred-vs-pred comparison plots.")
```
#### Model Graphs Interpretation
*Note: y-axis scales differ across models to preserve detail in each plot. Refer to the metrics tables for direct numerical comparisons.*
**Predicted vs. Actual (unclipped)**: The most visible progression across models is how tightly predictions track the diagonal. Ridge shows substantial scatter above ~$100k, with predictions capping out around $300k–$350k — vehicles priced at $400k+ are severely underpredicted, some by $300k or more. This is a fundamental limitation of a linear model on a log-transformed target with extreme tail values. CatBoost and the FT-Transformer both track the diagonal much more faithfully up through ~$200k, though all three models underpredict the most expensive vehicles ($300k+). This is expected: the log-space loss treats a 2× error equally whether the car costs $20k or $200k, so the models optimize for relative accuracy rather than chasing rare ultra-luxury outliers.
**Residuals vs. Predicted**: Ridge shows the widest residual spread at low-to-moderate predicted prices ($0–$150k), with large positive residuals (underpredictions) dominating. This reflects Ridge's tendency to compress expensive vehicles toward the center — cars actually worth $300k+ are predicted at $50k–$150k,placing their large residuals in the lower predicted range rather than the upper. CatBoost's residuals are much tighter and more symmetric around zero for typical vehicles, with isolated large residuals in both directions at higher predicted values. The FT-Transformer's residual pattern is similar to CatBoost's, with both models showing scattered positive and negative residuals at the high end — reflecting the inherent difficulty of pricing rare luxury vehicles. Across all three models, positive residuals (underpredictions) are larger in magnitude than negative ones (overpredictions), which is expected given the right-skewed price distribution — there is more room to underpredict a $500k car than to overpredict a $20k one.
**Residuals vs. Age**: All three models show the widest residual spread for young vehicles (ages 0–7), which narrows as age increases. This is expected — younger vehicles have higher and more variable prices, so absolute errors are naturally larger. The outliers scattered at age 25+ are isolated points (likely collector or vintage vehicles) rather than a systematic pattern. CatBoost and the FT-Transformer show similar residual patterns to each other across all ages, with Ridge producing larger extreme residuals but a comparable core band.
**Absolute Error vs. Actual (log scale)**: For all three models, absolute error increases with actual price, accelerating sharply above ~$100k actual — reflecting both the right-skewed price distribution and the log-space loss function, which optimizes for relative rather than absolute accuracy. Ridge's errors grow the fastest, with several errors approaching $400k and one exceeding $500k. CatBoost and the FT-Transformer both maintain substantially tighter error envelopes, with the FT-Transformer showing slightly fewer extreme errors at the very high end of the price range. However, the FT-Transformer's single worst outlier (~$400k error) exceeds CatBoost's worst (~$305k), illustrating the FT-Transformer's greater sensitivity to individual high-value vehicles.
**Clipped views (1–99%)**: With extreme outliers removed, the diagnostic patterns become clearer. Ridge's residuals-vs-predicted plot now shows a visible fan shape — residual variance increasing with predicted price — that was obscured by the scale of the unclipped version. This is classic heteroscedasticity that the linear model cannot capture. CatBoost and the FT-Transformer both produce tighter, more symmetric residual bands across the clipped range, confirming that their advantage over Ridge is not just about handling tail outliers — they also predict typical vehicles more accurately. The absolute error plots reinforce this: Ridge's worst clipped errors reach ~$77k, compared to ~$50k for CatBoost and ~$58k for the FT-Transformer.
**Pred vs. Pred (model agreement)**: The Ridge-vs-CatBoost and Ridge-vs-Keras plots both show the nonlinear models consistently predicting higher than Ridge, particularly in the mid-to-upper price range — reflecting Ridge's tendency to compress predictions toward the center. The CatBoost-vs-Keras plots show strong agreement along the diagonal and moderate scatter, confirming that both nonlinear models learned a similar structure but differ in their predictions for individual vehicles, especially at higher prices. This disagreement pattern suggests an ensemble could potentially improve tail performance.
### Final Model Selection
CatBoost is confirmed as the final model. As detailed in the [Project Background](#project-background), it achieved the lowest error across every metric while also being the most practical to tune and maintain. For a typical used car in the $7k–$91k range, its predictions fall within ~$1,267 of the actual price at the median.
### Key Takeaways
1. **Feature engineering was essential across all model classes.** Collapsing 1,808 raw engine strings into five structured features, normalizing 221 transmission variants by type and gear count, and engineering domain-informed features such as luxury-brand depreciation interactions gave all three models a clean, informative feature set. Even CatBoost, which handles categorical features natively, relied heavily on these engineered features — age, mileage, and the parsed engine attributes — all of which ranked among its top predictors.
2. **CatBoost's categorical handling is a structural advantage.** Ridge required 972 one-hot encoded dummy columns to represent 8 categorical features, inflating the feature space to 991 total dimensions. CatBoost handled the same categories natively — including 5,613 unique models — without one-hot encoding and outperformed Ridge by ~50% across all metrics. This suggests that on high-cardinality tabular data, the model's ability to handle categories efficiently matters as much as the underlying algorithm.
3. **Luxury vehicles are the hardest to price accurately.** All three models show increasing absolute error for vehicles above ~$100k, and the largest residuals are consistently observed for high-value luxury listings. This is likely because luxury pricing depends on factors not captured in the dataset — trim-level distinctions, option packages, condition details, and collector-market dynamics — that matter far more for a $400k Porsche than a $25k Toyota. The consistency of this pattern across Ridge, CatBoost, and the FT-Transformer suggests it reflects a limitation of the available features rather than any particular model's weakness.
4. **Deep learning is competitive but not dominant on tabular data.** The FT-Transformer came within ~$20 of CatBoost on clipped MAE, confirming that learned embeddings can capture meaningful structure. Its error profile also differed — fewer extreme errors at the high end but a larger single worst-case outlier — suggesting the two models fail on different vehicles and reinforcing the potential value of an ensemble. However, CatBoost required substantially less tuning effort, trained faster, and was more stable across hyperparameter choices, making it the practical production choice for this dataset.
### Limitations and Future Work
- **Geographic features**: The dataset lacks location data (state, ZIP code, metro area), which significantly affects used-car pricing.
- **Temporal dynamics**: The dataset lacks listing dates, so all listings are treated as a single cross-section. Time-aware modeling could capture how market conditions (e.g., pandemic-era supply constraints) affect pricing for the same vehicle at different points in time.
- **Ensemble methods**: A weighted blend of CatBoost and the FT-Transformer could potentially improve on either model alone, particularly for high-value vehicles where the two models disagree.
- **Vehicle condition**: The dataset lacks granular condition descriptors (e.g., paint quality, tire wear, service history completeness) that buyers weigh heavily in practice. The `accidents_or_damage` flag captures the most extreme cases, but two "no accident" vehicles can still differ substantially in real-world value based on cosmetic and mechanical wear.
- **Luxury vehicle features**: Luxury pricing showed the highest residuals across all three models, likely because the dataset lacks features that heavily influence high-end pricing — trim level, option packages (e.g., carbon ceramic brakes, premium audio), certification status (CPO vs. private sale), and collector-market relevance. Adding these could meaningfully reduce error for vehicles above $100k.
- **Containerized pipeline (Part 2 — planned)**: The `src/` module stubs are already scaffolded to refactor the notebook workflow into modular, independently deployable stages using Docker and Kubernetes, transitioning from a single-notebook analysis to a production-ready ML pipeline.
## Conclusion
This project demonstrates that careful feature engineering combined with a well-suited model architecture can produce used-car price predictions accurate enough for real business use — within ~$1,300 of the true price for typical vehicles, across a dataset spanning 29 manufacturers and 5,613 model variants.
The progression from Ridge to CatBoost to the FT-Transformer revealed that understanding the data was essential: collapsing 1,808 raw engine strings into five structured features, normalizing 221 transmission variants into type and gear count, and engineering domain-informed features like luxury-brand depreciation interactions gave all three models a strong foundation. CatBoost captured these patterns most reliably, and its practical advantages in training speed, tuning stability, and categorical handling make it the right choice for production.
The FT-Transformer's competitive performance confirms that deep learning can learn meaningful structure from tabular data, but on this problem, it did not justify the additional engineering and tuning cost. That may change as architectures and training recipes for tabular Transformers continue to mature.